

Cosmic Frog users can now visualize routes from Hopper (transportation optimization) and Neo (network optimization) on real road networks instead of straight lines. Valhalla, an open-source routing engine for OpenStreetMap, is used to calculate the waypoints.
This guide assumes familiarity with how to configure maps and their layers in Cosmic Frog. See the Getting Started with Maps help center article for the basics.
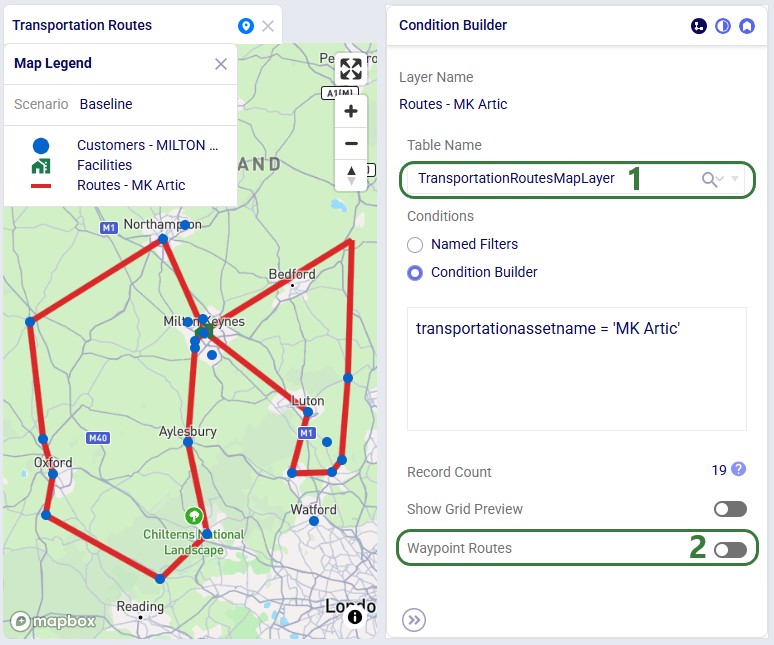
There are 2 tables available in the Table Name drop-down on the Condition Builder panel of a map layer for which waypoint routes can be generated:
In both cases the configuration is similar; first we will cover a Hopper example and then a Neo example.
Please note:
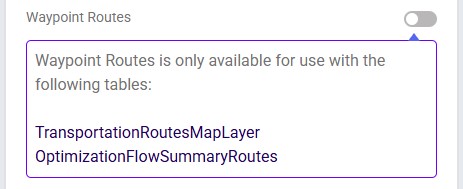

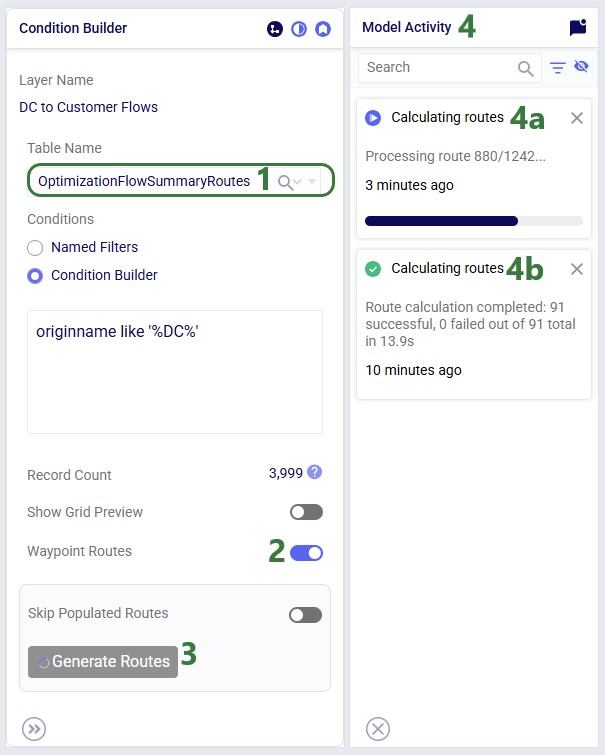
In our example case neither warning comes up, and the user turns on the Waypoint Routes option:
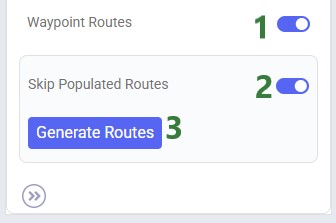
Processing time depends on the number of origin-destination pairs. As an indication, a larger Hopper model with ~3,000 routes took a little under 4 minutes to generate all waypoints.
Users can monitor the progress of the waypoint routes generation by opening the Model Activity panel:

Once the calculation completes, the map is updated to show the routes the waypoints have been calculated for on the road network:

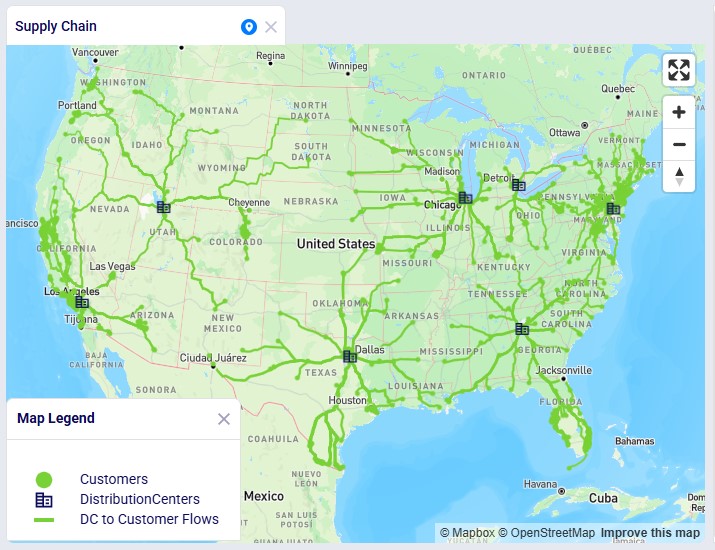
In this Neo example, we will generate road network flows for the following DC to Customer flows. This represents 1,333 unique origin-destination pairs:
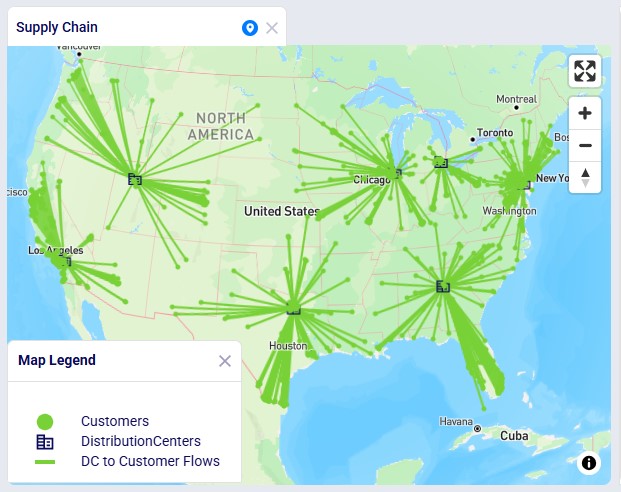
Once the waypoints have been calculated, the map updates and now looks as follows:
Hopper is the Transportation Optimization algorithm within Cosmic Frog. It designs optimal multi-stop routes to deliver/pickup a given set of shipments to/from customer locations at the lowest cost. Fleet sizing and balancing weekly demand can be achieved with Hopper too. Example business questions Hopper can answer are:
Hopper’s transportation optimization capabilities can be used in combination with network design to test out what a new network design means in terms of the last-mile delivery configuration. For example, questions that can be looked at are:
With ever increasing transportation costs, getting the last-mile delivery part of your supply chain right can make a big impact on the overall supply chain costs!
It is recommended to watch this short Getting Started with Hopper video before diving into the details of this documentation. The video gives a nice, concise overview of the basic inputs, process, and outputs of a Hopper model.
In this documentation we will first cover some general Cosmic Frog functionality that is used extensively in Hopper, next we go through how to build a Hopper model which discusses required and optional inputs, how to run a Hopper model is explained, Hopper outputs in tables, on maps and analytics are covered as well, and finally references to a few additional Hopper resources are listed. Note that additional more advanced Hopper features are covered in separate articles:
To not make this document too repetitive we will cover some general Cosmic Frog functionality here that applies to all Cosmic Frog technologies and is used extensively for Hopper too.
To only show tables and fields in them that can be used by the Hopper transportation optimization algorithm, disable all icons except the 4th (“Transportation”) in the Technologies Selector from the toolbar at the top in Cosmic Frog. This will hide any tables and fields that are not used by Hopper and therefore simplifies the user interface:

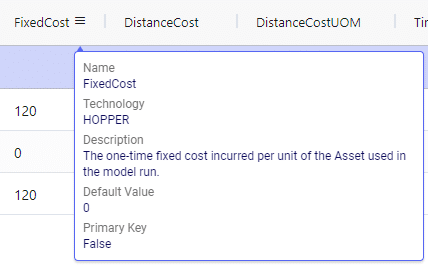
Many Hopper related fields in the input and output tables will be discussed in this document. Keep in mind however that a lot of this information can also be found in the tooltips that are shown when you hover over the column name in a table, see following screenshot for an example. The column name, technology/technologies that use this field, a description of how this field is used by those algorithm(s), its default value, and whether it is part of the table’s primary key are listed in the tooltip.
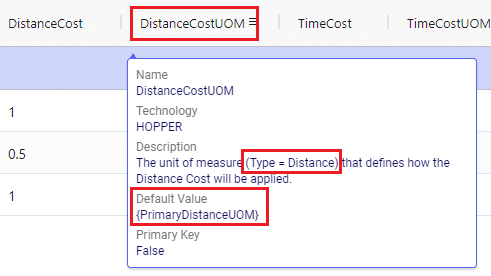
There are a lot of fields with names that end in “…UOM” throughout the input tables. How they work will be explained here so that individual UOM fields across the tables do not need to be explained further in this documentation as they all work similarly. These UOM fields are unit of measure fields and often appear to the immediate right of the field that they apply to, like for example Distance Cost and Distance Cost UOM in the screenshot above. In these UOM fields you can type the Symbol of a unit of measure that is of the required Type from the ones specified in the Units Of Measure table. For example, in the screenshot above, the unit of measure Type for the Distance Cost UOM field is Distance. Looking in the Units of Measure table, we see there are multiple of these specified, like for example Mile (Symbol = MI), Yard (Symbol = YD) and Kilometer (Symbol = KM), so we can use any of these in this UOM field. If we leave a UOM field blank, then the Primary UOM for that UOM Type specified in the Model Settings table will be used. For example, for the Distance Cost UOM field in the screenshot above the tooltip says Default Value = {Primary Distance UOM}. Looking this up in the Model Settings table shows us that this is set to MI (= mile) in our current model. Let’s illustrate this with the following screenshots of 1) the tooltip for the Distance Cost UOM field (located on the Transportation Assets table), 2) units of measure of Type = Distance in the Units Of Measure table and 3) checking what the Primary Distance UOM is set to in the Model Settings table, respectively:
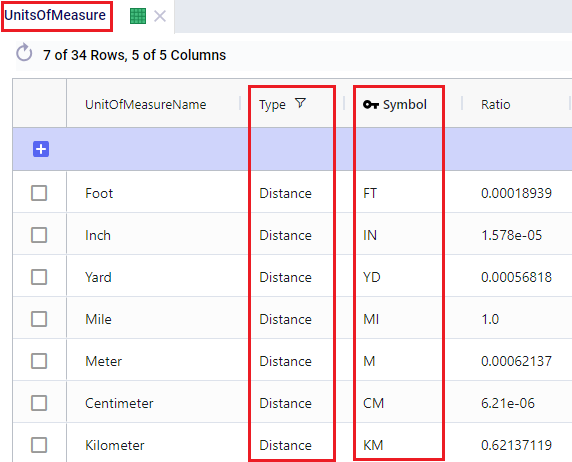
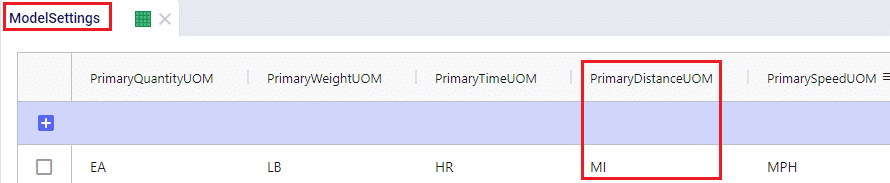
Note that only hours (Symbol = HR) is currently allowed as the Primary Time UOM in the Model Settings table. This means that if another Time UOM, like for example minutes (MIN) or days (DAY), is to be used, the individual UOM fields need to be used to set these. Leaving them blank would mean HR is used by default.
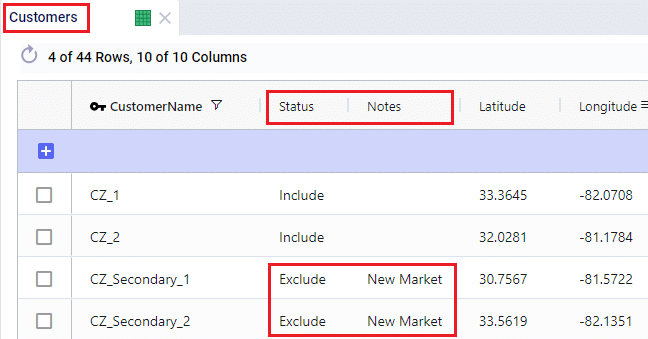
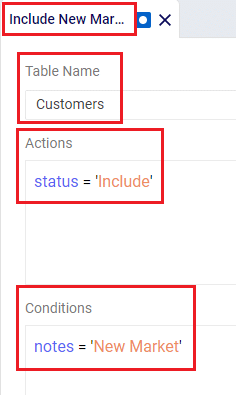
With few exceptions, all tables in Cosmic Frog contain both a Status field and a Notes field. These are often used extensively to add elements to a model that are not currently part of the supply chain (commonly referred to as the “Baseline”), but are to be included in scenarios in case they will definitely become part of the future supply chain or to see whether there are benefits to optionally include these going forward. In these cases, the Status in the input table is set to Exclude and the Notes field often contains a description along the lines of ‘New Market’, ‘New Product’, ‘Box truck for Scenarios 2-4’, ‘Depot for scenario 5’, ‘Include S6’, etc. When creating scenario items for setting up scenarios, the table can then be filtered for Notes = ‘New Market’ while setting Status = ‘Include’ for those filtered records. We will not call out these Status and Notes fields in each individual input table in the remainder of this document, but we definitely do encourage users to use these extensively as they make creating scenarios very easy. When exploring any Cosmic Frog models in the Resource Library, you will notice the extensive use of these fields too. The following 2 screenshots illustrate the use of the Status and Notes fields for scenario creation: 1) shows several customers on the Customers table where CZ_Secondary_1 and CZ_Secondary_2 are not currently customers that are being served but we want to explore what it takes to serve them in future. Their Status is set to Exclude and the Notes field contains ‘New Market’; 2) a scenario item called ‘Include New Market’ shows that the Status of Customers where Notes = ‘New Market’ is changed to ‘Include’.
The Status and Notes fields are also often used for the opposite where existing elements of the current supply chain are excluded in scenarios in cases where for example locations, products or assets are going to go offline in the future. To learn more about scenario creation, please see this short Scenarios Overview video, this Scenario Creation and Maps and Analytics training session video, this Creating Scenarios in Cosmic Frog help article, and this Writing Scenario Syntax help article.
A subset of Cosmic Frog’s input tables needs to be populated in order to run Transportation Optimization, whereas several other tables can be used optionally based on the type of network that is being modelled, and the questions the model needs to answer. The required tables are indicated with a green check mark in the screenshot below, whereas the optional tables have an orange circle in front of them. The Units Of Measure and Model Settings tables are general Cosmic Frog tables, not only used by Hopper and will always be populated with default settings already; these can be added to and changed as needed.

We will first discuss the tables that are required to be populated to set up a basic Hopper model and then cover what can be achieved by also using the optional tables and fields. Note that the screenshots of all input and output tables mostly contain the fields in the order they appear in in the Cosmic Frog user interface, however on occasion the order of the fields was rearranged manually. So, if you do not see a specific field in the same location as in a screenshot, then please scroll through the table to find it.
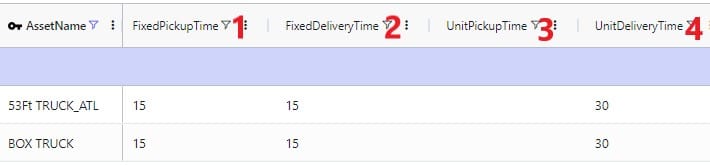
The Customers table contains what for purposes of modelling are considered the customers: the locations that we need to deliver a certain amount of certain product(s) to or pick a certain amount of product(s) up from. The customers need to have their latitudes and longitudes specified so that distances and transport times of route segments can be calculated, and routes can be visualized on a map. Alternatively, users can enter location information like address, city, state, postal code, country and use Cosmic Frog’s built in geocoding tool to populate the latitude and longitude fields. If the customer’s business hours are important to take into account in the Hopper run, its operating schedule can be specified here too, along with customer specific variable and fixed pickup & delivery times. Following screenshot shows an example of several populated records in the Customers table:
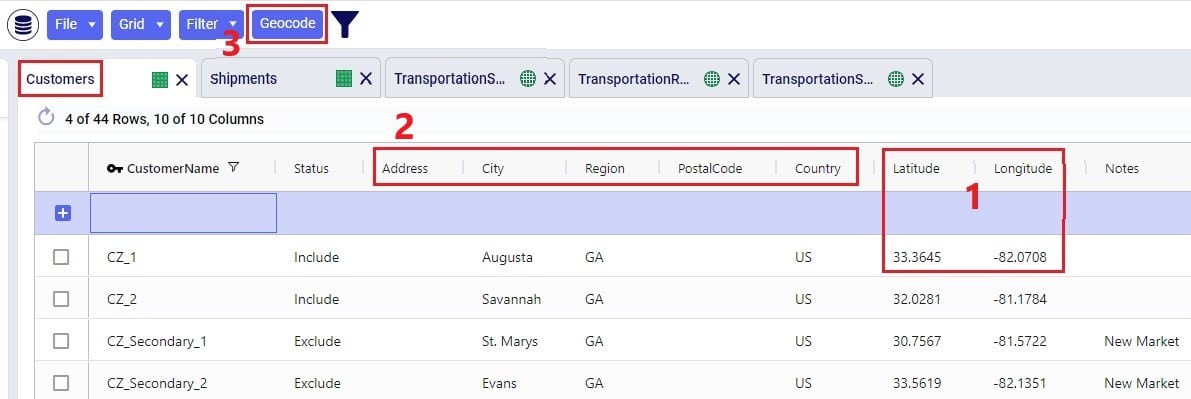
The pickup & delivery time input fields can be seen when scrolling right in the Customers table (the accompanying UOM fields are omitted in this screenshot):

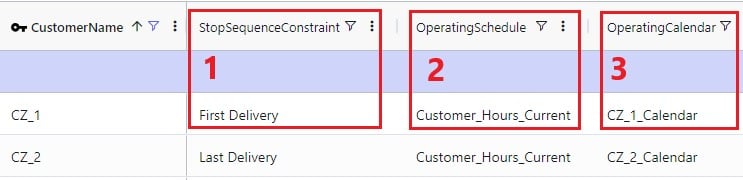
Finally, scrolling even more right, there are 3 additional Hopper-specific fields in the Customers table:
The Facilities table needs to be populated with the location(s) the transportation routes start from and end at; they are the domicile locations for vehicles (assets). The table is otherwise identical to the customers table, where location information can again be used by the geocoding tool to populate the latitude and longitude fields if they are not yet specified. And like other tables, the Status and Notes field are often used to set up scenarios. This screenshot shows the Facilities table populated with 2 depots, 1 current one in Atlanta, GA, and 1 new one in Jacksonville, FL:

Scrolling further right in the Facilities table shows almost all the same fields as those to the right on the Customers table: Operating Schedule, Operating Calendar, and Fixed & Unit Pickup & Delivery Times plus their UOM fields. These all work the same as those on the Customers table, please refer to the descriptions of them in the previous section.
The item(s) that are to be delivered to the customers from the facilities are entered into the Products table. It contains the Product Name, and again a Status and Notes fields for ease of scenario creation. Details around the Volume and Weight of the product are entered here too, which are further explained below this screenshot of the Products table where just one product “PRODUCT” has been specified:

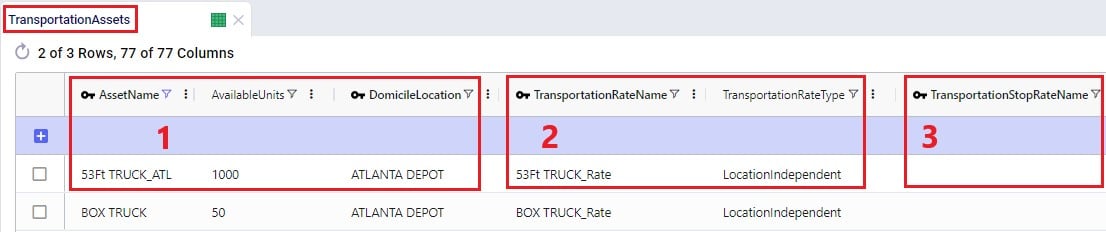
On the Transportation Assets table, the vehicles to be used in the Hopper baseline and any scenario runs are specified. There are a lot of fields around capacities, route and stop details, delivery & pickup times, and driver breaks that can be used on this table, but there is no requirement to use all of them. Use only those that are relevant to your network and the questions you are trying to answer with your model. We will discuss most of them through multiple screenshots. Note that the UOM fields have been omitted in these screenshots. Let’s start with this screenshot showing basic asset details like name, number of units, domicile locations, and rate information:
The following screenshot shows the fields where the operating schedule of the asset, any fixed costs, and capacity of the vehicles can be entered:

Note that if all 3 of these capacities are specified, the most restrictive one will be used. If you for example know that a certain type of vehicle always cubes out, then you could just populate the Volume Capacity and Volume Capacity UOM fields and leave the other capacity fields blank.
If you scroll further right, you will see the following fields that can be used to set limits on route distance and time when using this type of vehicle. Where applicable, you will notice their UOM fields too (omitted in the screenshot):

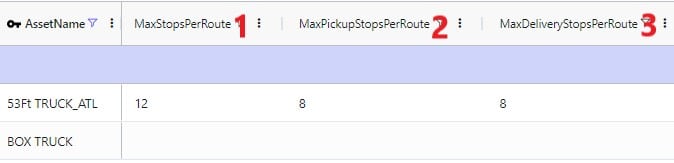
Limits on the amount of stops per route can be set too:
A tour is defined as all the routes a specific unit of a vehicle is used on during the model horizon. Limits around routes, time, and distance for tours can be added if required:

Scrolling still further right you will see the following fields that can be used to add details around how long pickup and delivery take when using this type of vehicle. These all have their own UOM fields too (omitted in the screenshot):
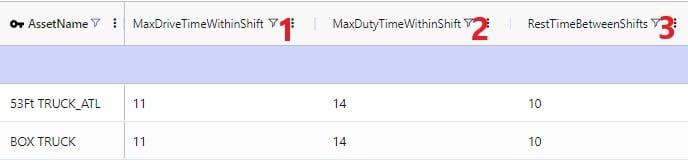
The next 2 screenshots shows the fields on the Transportation Assets table where rules around driver duty, shift, and break times can be entered. Note that these fields each have a UOM field that is not shown in the screenshot:

Limits around out of route distance can be set too. Plus details regarding the weight of the asset itself and the level of CO2 emissions:

Lastly, a default cost, fixed times for admin, and an operating calendar can be specified for a vehicle in the following fields on the transportation assets table:

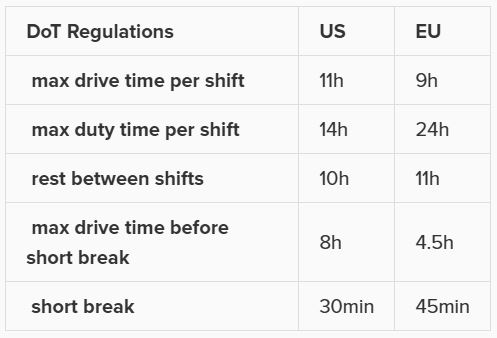
As a reference, these are the department of transportation driver regulations in the US and the EU. They have been somewhat simplified from these sources: US DoT Regulations and EU DoT Regulations:
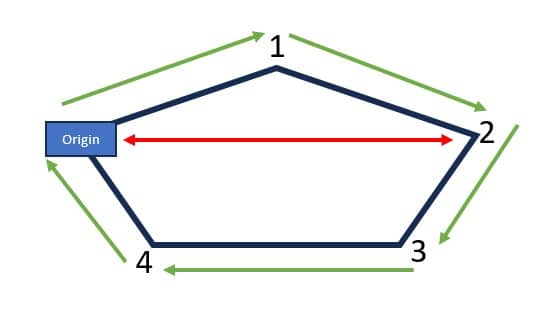
Consider this route that starts from the DC, then goes to CZ1 & CZ2, and then returns to the DC:
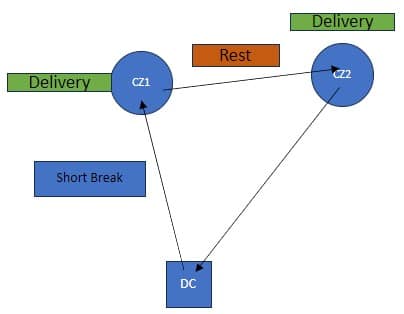
The activities on this route can be thought of as follows, where the start of the Rest is the end of Shift 1 and Shift 2 starts at the end of the Rest:

Notes on Driver Breaks:
Except for asset fixed costs, which are set on the Transportation Assets table, and any Direct Costs which are set on the Shipments table, all costs that can be associated with a multi-stop route can be specified in the Transportation Rates table. The following screenshot shows how a transportation rate is set up with a name, a destination name and the first several cost fields. Note that UOM fields have been omitted in this screenshot, but that each cost field has its own UOM field to specify how the costs should be applied:

Scrolling further right in the Transportation Rates table we see the remaining cost fields:

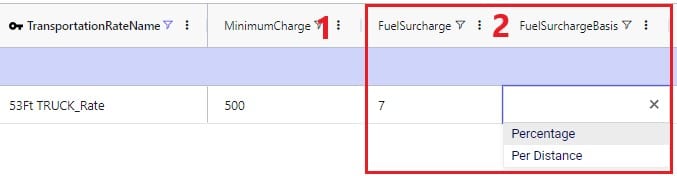
Finally, a minimum charge and fuel surcharge can be specified as part of a transportation rate too:
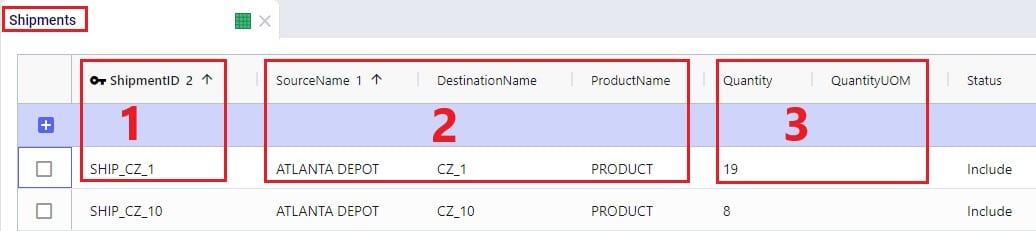
The amount of product that needs to be delivered from which source facility/supplier to which destination customer or picked up from which customer is specified on the Shipments table. Optionally, details around pickup and delivery times, direct costs, and fixed template routes can be set on this table too. Note that the Shipments table is Transportation Asset agnostic, meaning that the Hopper transportation optimization algorithm will choose the optimal one to use from the vehicles domiciled at the source location. This first screenshot of the Shipments table shows the basic shipment details:
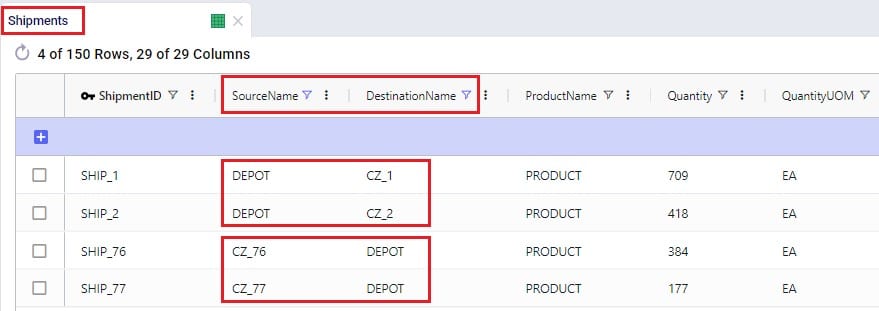
Here is an example of a subset of Shipments for a model that will route both pickups and deliveries:
To the right in the Shipments table we find the fields where details around shipment windows can be entered:

Still further right on the Shipments table are the fields where details around pickup and delivery times can be specified:

Finally, furthest right on the Shipments table are fields where Direct Costs, details around Template Routes and decompositions can be configured:

Note that there are multiple ways to switching between forcing Shipments and the order of stops onto a template route and letting Hopper optimize which shipments will be put on a route together and in which order. Two example approaches are:
The tables and their input fields that can optionally be populated for their inputs to be used by Hopper will now be covered. Where applicable, it will also be mentioned how Hopper will behave when these are not populated.
In the Transit Matrix table, the transport distance and time for any source-destination-asset combination that could be considered as a segment of a route by Hopper can be specified. Note that the UOM fields in this table are omitted in following screenshot:
The transport distances for any source-destination pairs that are not specified in this table will be calculated based on the latitudes and longitudes of the source and destination and the Circuity Factor that is set in the Model Settings table. Transport times for these pairs will be calculated based on the transport distance and the vehicle’s Speed as set on the Transportation Assets table or, if Speed is not defined on the Transportation Assets table, the Average Speed in the Model Settings table.
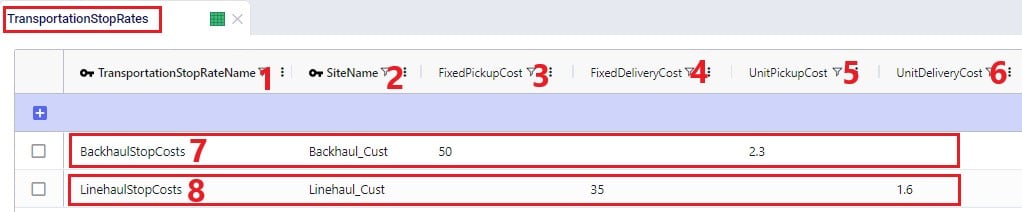
Costs that need to be applied on a stop basis can be specified in the Transportation Stop Rates table:
If Template Routes are specified on the Shipments table by using the Template Route Name and Template Route Stop Sequence fields, then the Template Routes table can be used to specify if and how insertions of other Shipments can be made into these template routes:
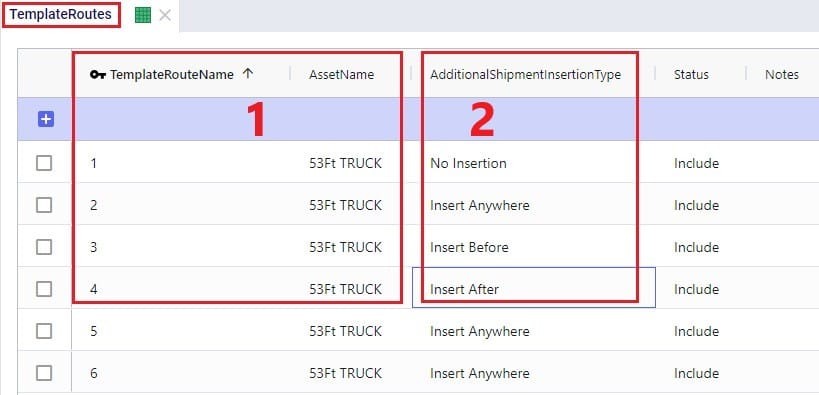
If a template route is set up by using the Template Route Name and Template Route Stop Sequence fields in the Shipments table and this route is not specified in the Template Routes table, it means that no insertions can be made into this template route.
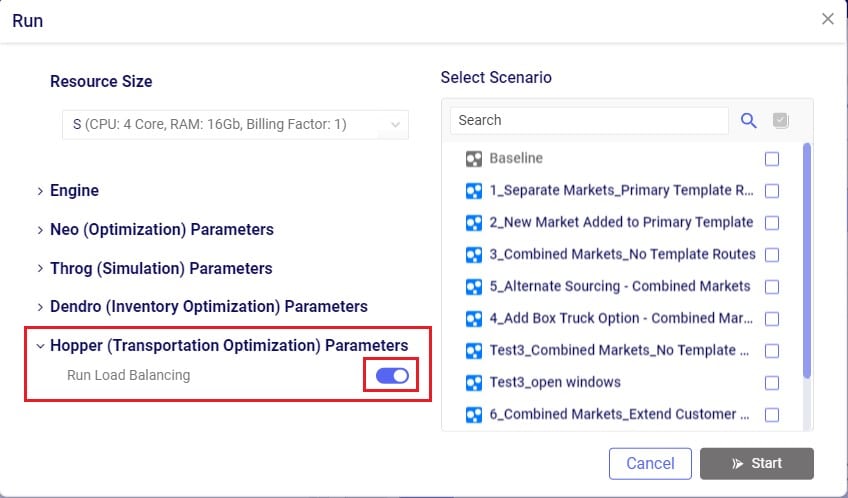
In addition to routing shipments with a fixed amount of product to be delivered to a customer location, Hopper can also solve problems where routes throughout a week need to be designed to balance out weekly demand while achieving the lowest overall routing costs. The Load Balancing Demand and Load Balancing Schedules tables can be used to set this up. If both the Shipments table and the Load Balancing Demand/Schedules tables are populated, by default the Shipments table will be used and the Load Balancing Demand/Schedules tables will be ignored. To switch to using the Load Balancing Demand/Schedules tables (and ignoring the Shipments) table, the Run Load Balancing toggle in the Hopper (Transportation Optimization) Parameters section on the Run screen needs to be switched to on (toggle to the left and grey is off; to the right and blue is on):
The weekly demand, the number of deliveries per week, and, optionally, a balancing schedule can be specified in the Load Balancing Demand table:

To balance demand over a week according to a schedule, these schedules can be specified in the Load Balancing Schedules table:
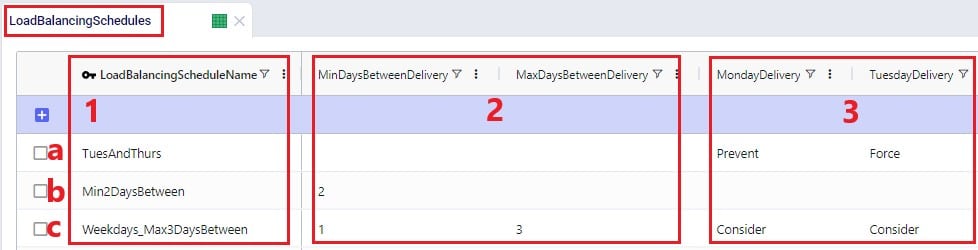
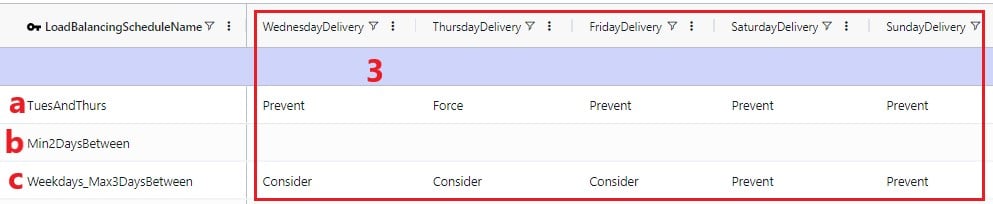
In the screenshots above, the 3 load balancing schedules that have been set up will spread the demand out as follows:
In the Relationship Constraints table, we can tell Hopper what combinations of entities are not allowed on the same route. For example, in the screenshot below we are saying that customers that make up the Primary Market cannot be served on the same route as customers from the Secondary Market:

A few examples of common Relationship Constraints are shown in the following screenshot where the Notes field explains what the constraint does:

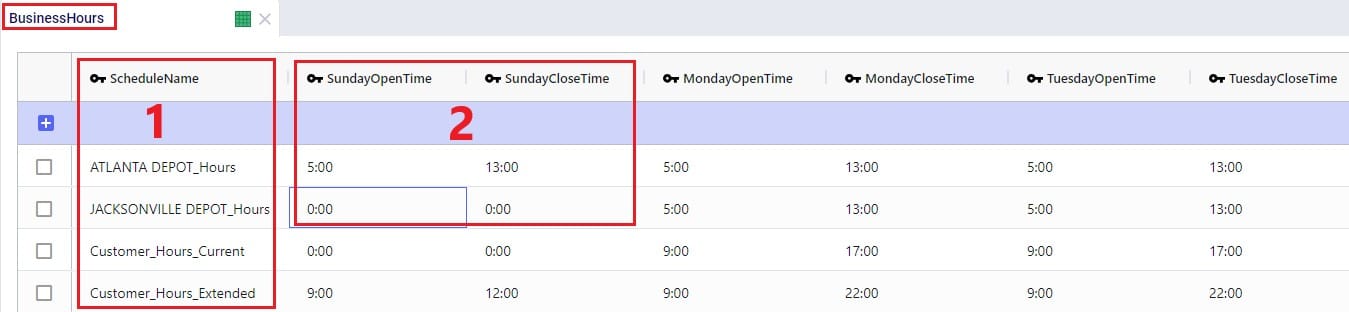
To set the availability of customers, facilities, and assets to certain start and end times by day of the week, the Business Hours table can be used. The Schedule Name specified on this table can then be used in the Operating Schedule fields on the Customers, Facilities and Transportation Assets tables. Note that the Wednesday – Saturday Open Time and Close Time fields are omitted in the following screenshot:
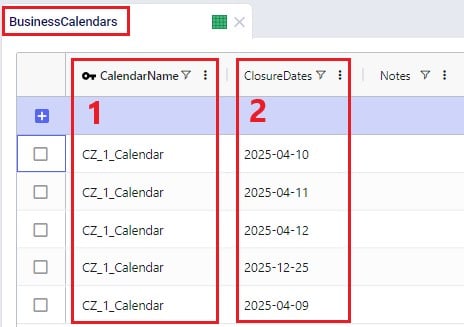
To schedule closure of customers, facilities, and assets on certain days, the Business Calendars table can be used. The Calendar Name specified on this table can then be used in the Operating Calendar fields on the Customers, Facilities and Transportation Assets tables:
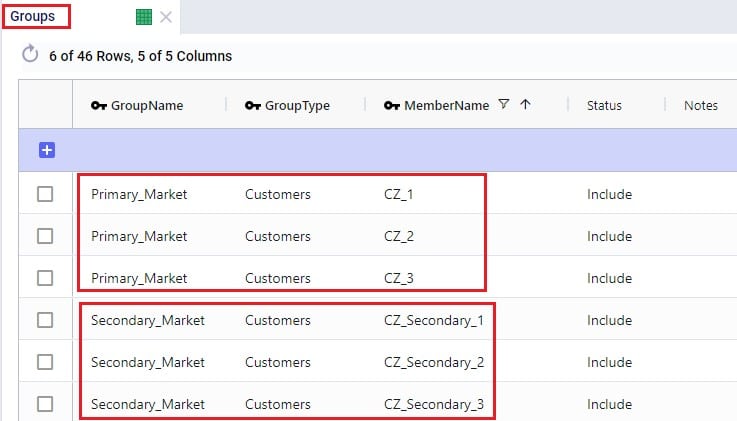
Groups are a general Cosmic Frog feature to make modelling quicker and easier. By grouping elements that behave the same together in a group we can reduce the number of records we need to populate in certain tables since we can use the Group names to populate the fields instead of setting up multiple records for each individual element which will all have the same information otherwise. Underneath the hood, when a model that uses Groups is run, these Groups are enumerated into the individual members of the group. We have for example already seen that groups of Type = Customers were used in the Relationship Constraints table in the previous section to prevent customers in the Primary Market being served on the same route as customers in the Secondary Market. Looking in the Groups table we can see which customers are part (‘members’) of each of these groups:
Examples of other Hopper input tables where use of Groups can be convenient are:
Note that in addition to Groups, Named Filters can be used in these instances too. Learn more about Named Filters in this help center article.
The Step Costs table is a general table in Cosmic Frog used by multiple technologies. It is used to specify costs that change based on the throughput level. For Hopper, all cost fields on the Transportation Rates table, the Transportation Stop Rates table, and the Fixed Cost on the Transportation Assets table can be set up to use Step Costs. We will go through an example of how Step Costs are set up, associated with the correct cost field, and how to understand outputs using the following 3 screenshots of the Step Costs table, Transportation Rates table and Transportation Route Summary output table, respectively. The latter will also be discussed in more detail in the next section on Hopper outputs.

In this example, the per unit cost for units 0 through 20 is $1, $0.9 for units 21 through 40, and $0.85 for all units over 40. Had the Step Cost Behavior field been set to All Item, then the per unit cost for all items is $1 if the throughput is between 0 and 20 units, the per unit cost for all items is $0.9 if the throughput is between 21 and 40 units, and the per unit cost for all items is $0.85 if the throughput is over 41 units.
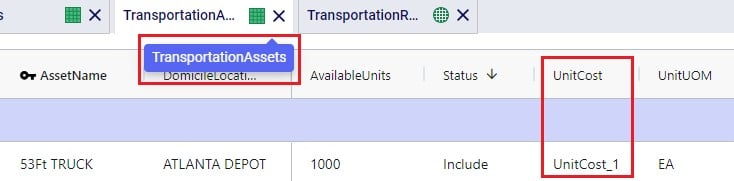
In this screenshot of the Transportation Rates table, it is shown that the Unit Cost field is set to UnitCost_1 which is the stepped cost with 3 throughput levels that we just discussed in the screenshot above:
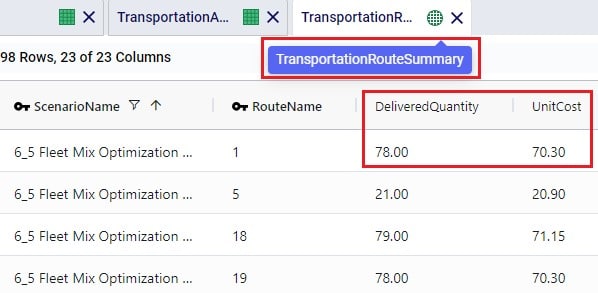
Lastly, this is a screenshot of the Transportation Route Summary output table where we see that the Delivered Quantity on Route 1 is 78. With the stepped cost structure as explained above for UnitCost_1, the Unit Cost in the output is calculated as follows: 20 * $1 (for units 1-20) + 20 * $0.9 (for units 21-40) + 38 * $0.85 (for units 41-78) = $20 + $18 + $32.30 = $70.30.
When the input tables have been populated and scenarios are created (several resources explaining how to set up and configure scenarios are listed in the “2.4 Status and Notes fields” section further above), one can start a Hopper run by clicking on the Run button at the top right in Cosmic Frog:

The Run screen will come up:

Once a Hopper run is completed, the Hopper output tables will contain the outputs of the run.
As with other Cosmic Frog algorithms, we can look at Hopper outputs in output tables, on maps and analytics dashboards. We will discuss each of these in the next 3 sections. Often scenarios will be compared to each other in the outputs to determine which changes need to be made to the last-mile delivery part of the supply chain.
In the Output Summary Tables section of the Output Tables are 8 Hopper specific tables, they start with “Transportation…”. Plus, there is also the Hopper specific detailed Transportation Activity Report table in the Output Report Tables section:
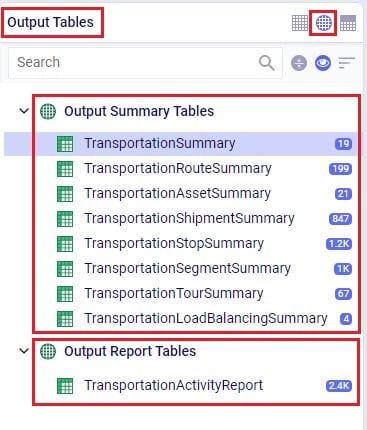
Switch from viewing Input Tables to Output Tables by clicking on the round grid at the top right of the tables list. The Transportation Summary table gives a high-level summary of each Hopper scenario that has been run and the next 6 Summary output tables contain the detailed outputs at the route, asset, shipment, stop, segment, and tour level. The Transportation Load Balancing Summary output table is populated when a Load Balancing scenario has been run, and summarizes outputs at the daily level. The Transportation Activity Report is especially useful to understand when Rests and Breaks are required on a route. All these output tables will be covered individually in the following sections.
The Transportation Summary table contains outputs for each scenario run that include Hopper run details, cost details, how much product was delivered and how, total distance and time, and how many routes, stops and shipments there were in total.

The Hopper run details that are listed for each scenario include:
The next 2 screenshots show the Hopper cost outputs, summarized by scenario:


Scrolling further right in the Transportation Summary table shows the details around how much product was delivered in each scenario:

For the Quantity UOM that is shown in the farthest right column in this screenshot (eaches here), the Total Delivered Quantity, Total Direct Quantity and Total Undelivered Quantity are listed in these columns. If the Total Direct Quantity is greater than 0, details around which shipments were delivered directly to the customer can be found in the Transportation Shipment Summary output table where the Shipment Status = Direct Shipping. Similarly, if the total undelivered quantity is greater than 0, then more details on which shipments were not delivered and why are detailed in the Unrouted Reason field of the Transportation Shipment Summary output table where the Shipment Status = Unrouted.
The next set of output columns when scrolling further right repeat these delivered, direct and undelivered amounts by scenario, but in terms of volume and weight.
Still further to the right we find the outputs that summarize the total distance and time by scenario:


Lastly, the fields furthest right on the Transportation Summary output table contain details around the number of routes, assets and shipments, and CO2 emissions:

A few columns contained in this table are not shown in any of the above screenshots, these are:
The Transportation Route Summary table contains details for each route in each scenario that include cost, distance & time, number of stops & shipments, and the amount of product delivered on the route.

The costs that together make up the total Route Cost are listed in the next 11 fields shown in the next 2 screenshots:


The next set of output fields show the distance and time for each route:


Finally, the fields furthest right in the Transportation Route Summary table list the amount of product that was delivered on the routes, and the number of stops and delivered shipments on each route.

The Transportation Asset Summary output table contains the details of each type of asset used in each scenario. These details include costs, amount of product delivered, distance & time, and the number of delivered shipments.
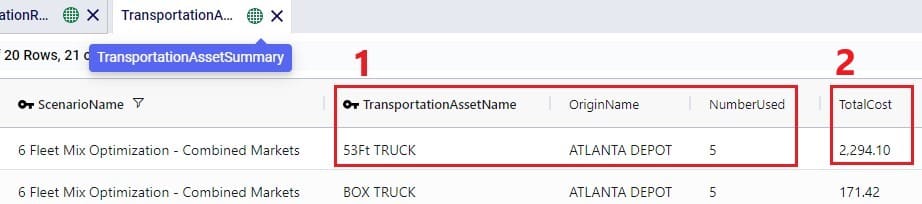
The costs that together make up the Total Cost are listed in the next 12 fields:


The next set of fields in the Transportation Asset Summary summarize the distances and times by asset type for the scenario:


Furthest to the right on the Transportation Asset Summary output table we find the outputs that list the total amount of product that was delivered, the number of delivered shipments, and the total CO2 emissions:

The Transportation Shipment Summary output table lists for each included Shipment of the scenario the details of which asset type it is served by, which stop on which route it is, the amount of product delivered, the allocated cost, and its status.

The next set of fields in the Transportation Shipment Summary table list the total amount of product that was delivered to this stop.
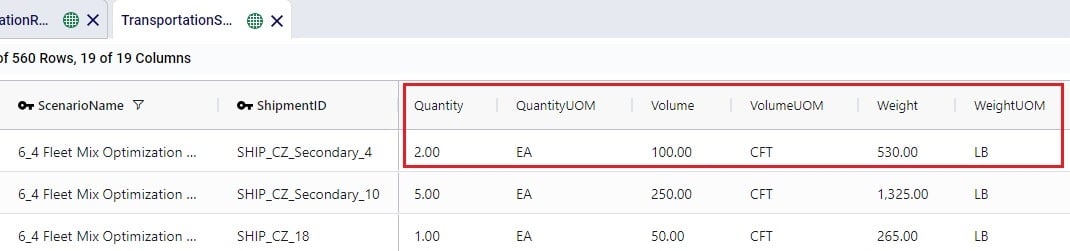
The next screenshot of the Transportation Shipment Summary shows the outputs that detail the status of the shipment, costs, and a reason in case the shipment was unrouted.

Lastly, the outputs furthest to the right on the Transportation Shipment Summary output table list the pickup and delivery time and dates, the allocation of CO2 emissions and associated costs, and the Decomposition Name if used:

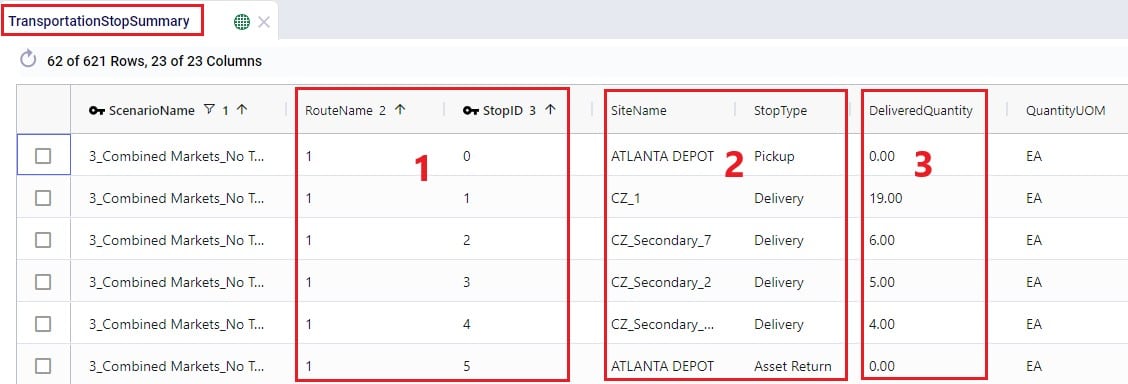
The Transportation Stop Summary output table lists for each route all the individual stops and their details around amount of product delivered, allocated cost, service time, and stop location information.
This first screenshot shows the basic details of the stops in terms of route name, stop ID, location, stop type, and how much product was delivered:
Somewhat further right on the Transportation Stop Summary table we find the outputs that detail the route cost allocation and the different types of time spent at the stop:

Lastly, farthest right on the Transportation Stop Summary table, arrival, service, and departure dates are listed, along with the stop’s latitude and longitude:

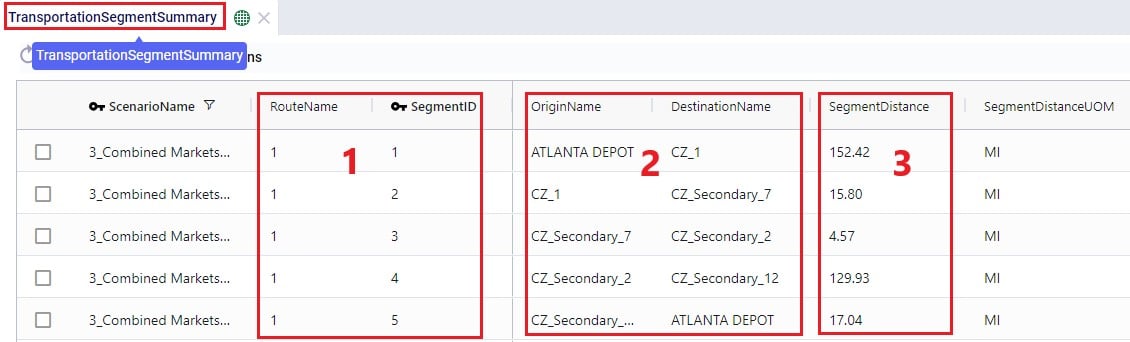
The Transportation Segment Summary output table contains distance, time, and source and destination location details for each segment (or “leg”) of each route.
The basic details of each segment are shown in the following screenshot of the Transportation Segment Summary table:
Further right on the Transportation Segment Summary output table, the time details of each segment are shown:

Next on the Transportation Segment Summary table are the latitudes and longitudes of the segment’s origin and destination locations:

And farthest right on the Transportation Segment Summary output table details around the start and end date and time of the segment are listed, plus CO2 emissions and the associated CO2 cost:

For each Tour (= asset schedule) the Transportation Tour Summary output table summarizes the costs, distances, times, and CO2 details.
The next 3 screenshots show the basic tour details and all costs associated with a tour:



The next screenshot shows the distance outputs available for each tour on the Transportation Tour Summary output table:

Scrolling further right on the Transportation Tour Summary table, the outputs available for tour times are listed:


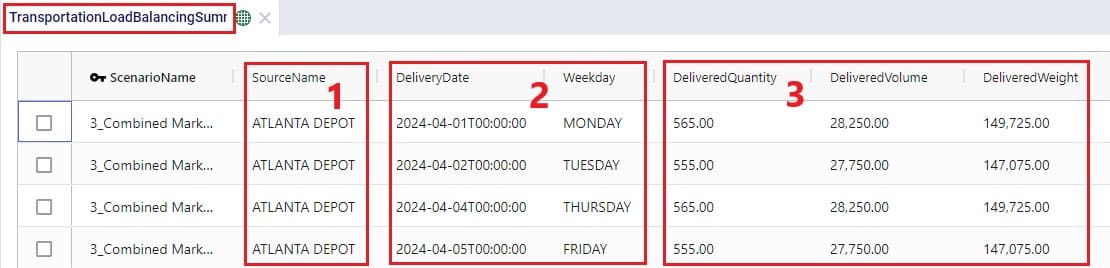
If a load balancing scenario has been run (see the Load Balancing Demand input table further above for more details on how to run this), then the Transportation Load Balancing Summary output table will be populated too. Details on amount of product delivered, plus the number of routes, assets and delivered shipments by day of the week can be found in this output table; see the following 2 screenshots:

For each route, the Transportation Activity Report details all the activities that happen in chronological order with details around distance and time and it breaks down how far along the duty and drive times are at each point in the route, which is very helpful to understand when rests and short breaks are happening.
This first screenshot of the Transportation Activity Report shows the basic details of the activities:
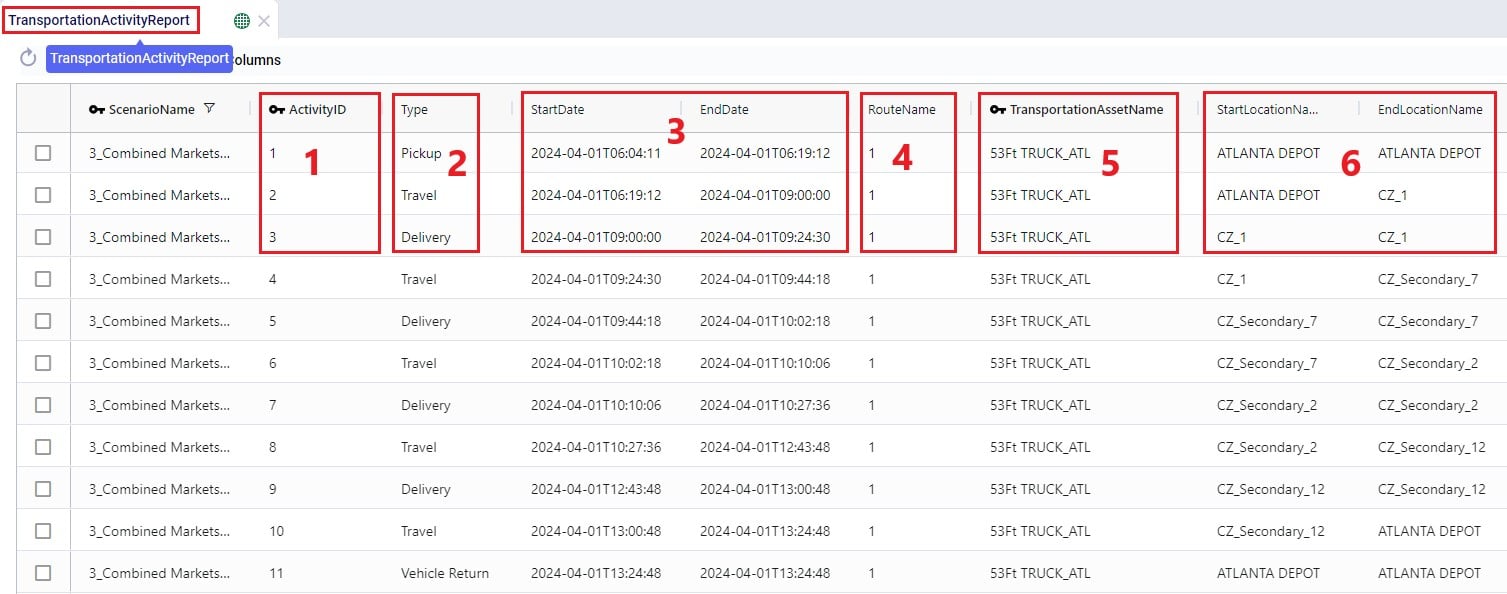
Next, the distance, time, and delivered amount of product are detailed on the Transportation Activity Report:

Finally, the last several fields on the Transportation Activity Report details cost, and the thus far accumulated duty and drive times:

As with the other engines within Cosmic Frog, Maps are very helpful in visualizing baseline and scenario outputs. Here, we will discuss how to set up Hopper specific Maps at a high level; we will not cover all the ins and outs of maps. If you are unfamiliar with the Maps module in Cosmic Frog, then please review the “Getting Started with Maps” article in the Optilogic Help Center first. It covers how to add and configure new maps and their layers.
Visualizing Hopper routes and direct shipments on maps is achieved by adding map layers which use 1 of the following as the table name:
Using what we have discussed above and the learnings from the Getting Started with Maps help center article, we can create the following map quite easily and quickly (the model used here is one from the Resource Library, named Transportation Optimization):
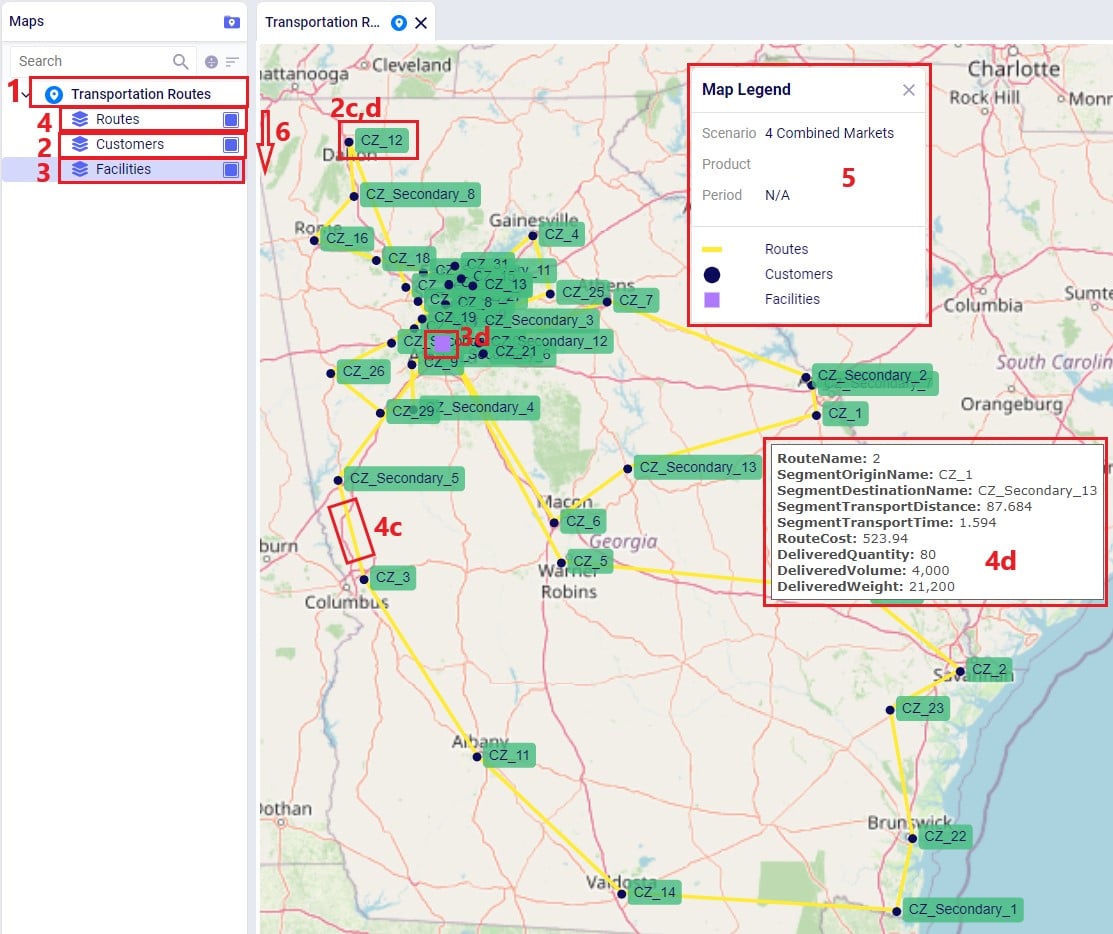
The steps taken to create this map are:
Let’s also cover 2 maps of a model where both pickups and deliveries are being made, from “backhaul” and to “linehaul” customers, respectively. When setting the LIFO (Is Last In First Out) field on the Transportation Assets table to True, this leads to routes that contain both pickup and delivery stops, but all the pickups are made at the end (e.g. modeling backhaul):
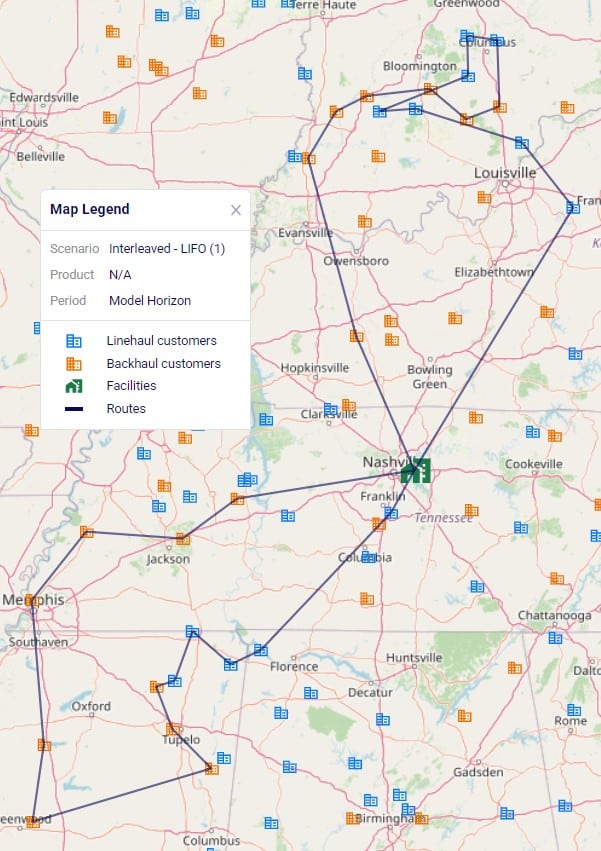
Two example routes are being shown in the screenshot above and we can see that all deliveries are first made to the linehaul customers which have blue icons. Then, pickups are made at the backhaul customers which have orange icons. If we want to design interleaved routes where pickups and deliveries can be mixed, we need to set the LIFO field to False. The following screenshot shows 2 of these interleaved routes:

The above 2 screenshots use the Transportation Routes Map Layer as the table name to draw the Routes map layer, where the condition builder is used to filter for 2 of the route names.
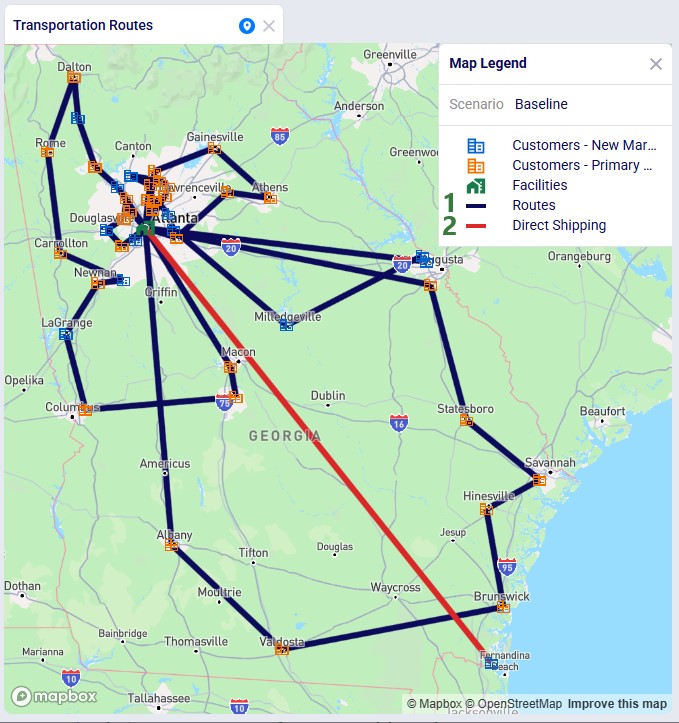
Finally, we will go back to the Transportation Optimization model which was used for the first map screenshot in this section. The Baseline scenario in this model has 1 shipment that is being shipped directly. To visualize this on the map we add a map layer named "Direct Shipping" which uses the Transportation Shipment Summary as the table name input. On the Layer Style pane we change the color for this line layer to red. We also keep the "Routes" map layer, which is drawn from the Transportation Routes Map Layer with the default dark blue color:
In the Analytics module of Cosmic Frog, dashboards that show graphs of scenario outputs, sliced and diced to the user’s preferences, can quickly be configured. Like Maps, this functionality is not Hopper specific and other Cosmic Frog technologies use these extensively too. We will cover setting up a Hopper specific visualization, but not all the details of configuring dashboards. Please review these resources on Analytics in Cosmic Frog first if you are not yet familiar with these:
We will do a quick step by step walk through of how to set up a visualization of comparing scenario costs by cost type in a new dashboard:
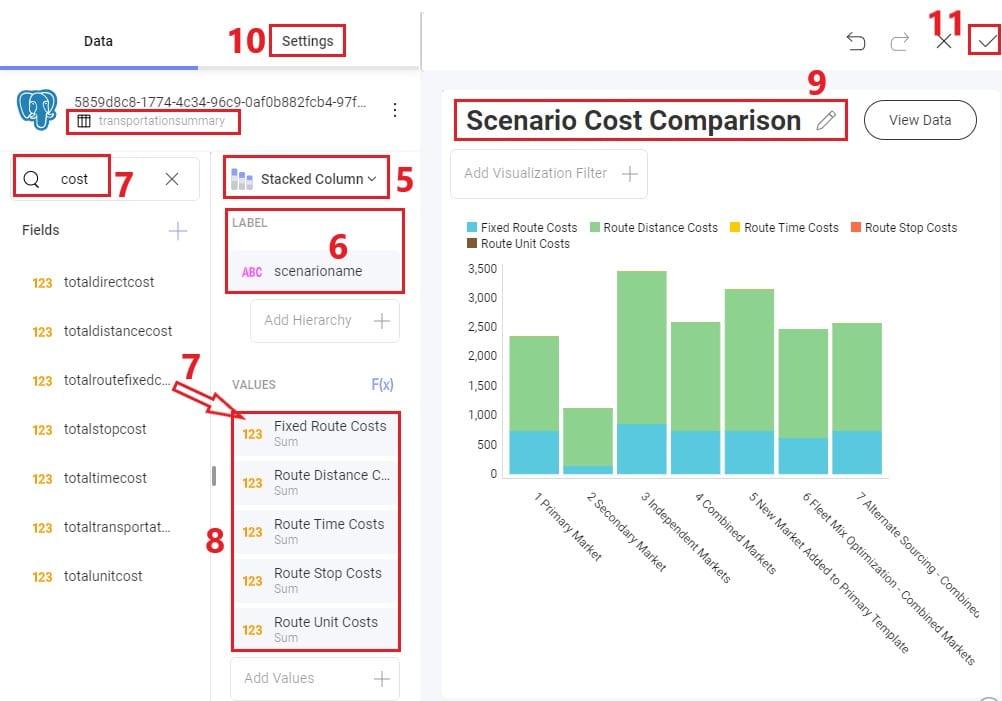
The steps to set this up are detailed here, note that the first 4 bullet points are not shown in the screenshot above:
All Hopper specific Help Center articles can be found in the Hopper - Transportation Optimization section under Navigating Cosmic Frog.
There are also several models in the Resource Library that transportation optimization users may find helpful to review. How to use resources in the Resource Library is described in the help center article “How to Use the Resource Library”.
Incremental Change is a powerful new capability in Cosmic Frog’s NEO engine (Network Optimization) that helps you manage the transition between two network states – such as moving from your current baseline network to an optimized future state. Rather than implementing all changes at once, Incremental Change allows you to control the pace and sequence of changes over time, making network transformations more practical and manageable.
This feature bridges the gap between theoretical optimization results and realistic implementation plans by generating a sequenced roadmap of network changes.
In this documentation, we will discuss the impact of Incremental Change, explain how to use it, and then walk through 2 demo models showing examples of the new capabilities. These models can be copied to your own Optilogic account from the Resource Library:
Please also see the following brief video for an introduction to Incremental Change and an overview of the second demo model, Incremental Change - Supplier Base Transition:
Supply chain networks rarely change overnight. Whether you are opening new distribution centers, shifting supplier bases, or adapting to seasonal demand fluctuations, real-world constraints limit how quickly you can implement changes. Organizations face practical limitations including:
Incremental Change addresses these realities by helping you answer critical questions: What is the best order of changes? What is the optimal rate of change? What tolerance levels are appropriate for different types of modifications?
Understand which network modifications deliver the greatest value earliest in your transition. Incremental Change provides clear visibility into expected savings versus the number of changes required, along with detailed change checklists for each scenario.
Create realistic, step-by-step roadmaps for moving from your current network to your target network. You will receive:
Manage network evolution in response to changing business conditions while respecting operational constraints. Balance total cost optimization against your tolerance for change, with detailed monthly implementation plans.
Cosmic Frog's Incremental Change currently supports the following network changes:
Progressive Facility Expansion: When opening a new distribution center, specify that you want to reassign up to 10 customers per month, and the system determines which customers to transition each month to maximize savings.
Seasonal Production Smoothing: For products with seasonal demand patterns, set constraints to ensure facility production never varies by more than 10% month-over-month, maintaining operational stability.
Multi-Year Facility Rollouts: Plan the optimal sequence for opening 10 facilities over five years including a detailed 2-year implementation roadmap.
Strategic Supplier Transitions: Systematically shift your supplier base. For example, progressively move sourcing out of or into a particular region – with Incremental Change determining the optimal sequence of supplier changes.
Incremental Change uses a new input table and generates 2 new output tables with different levels of detail:
Input: Use the Incremental Change Constraints table to set the change type(s) being included and your change budget for each period.
Outputs:
By leveraging Incremental Change, you can transform theoretical network optimization results into actionable, phased implementation plans that respect real-world operational constraints while maximizing value delivery.
Some additional pointers that may prove helpful are as follows:
In this example model, "Incremental Change - Production Smoothing", we will see how we can ensure that increases in production from one month to the next are limited to a certain percentage using the Incremental Change feature. This model can be copied from the Resource Library to your own account in case you want to follow along.
The following screenshot shows which input tables are populated in this example model:
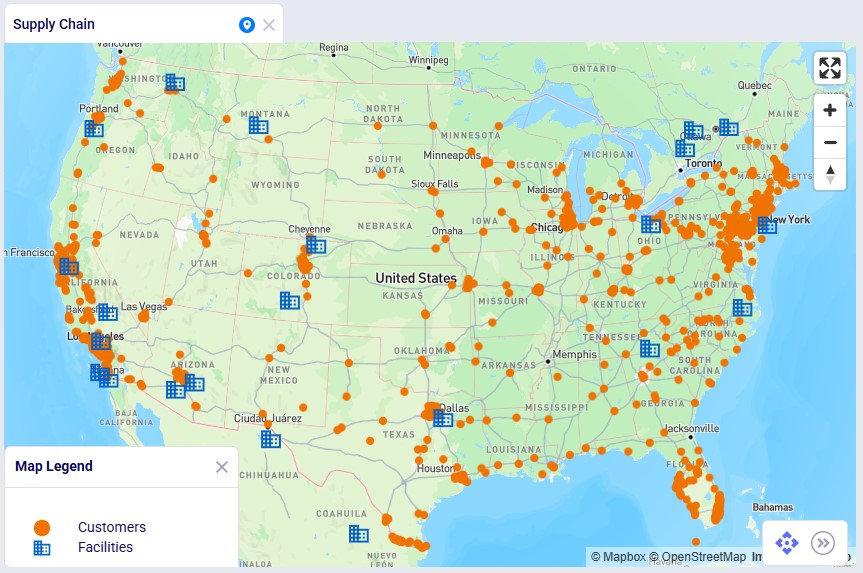
This next screenshot shows the customer and facility locations on a map:
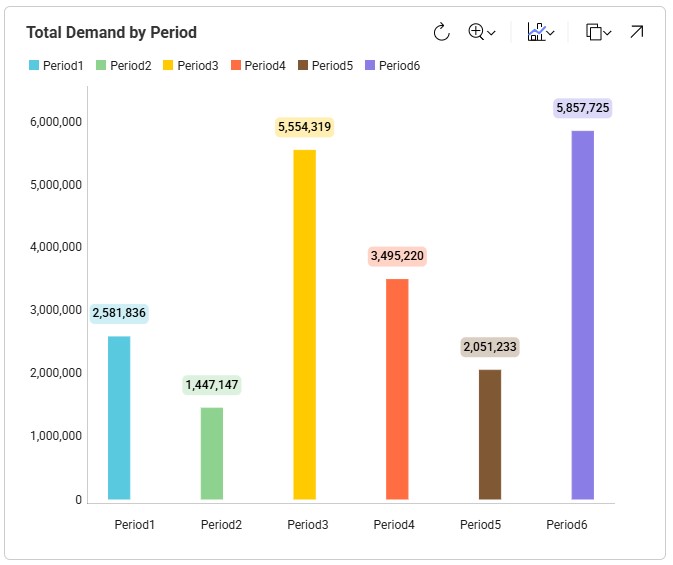
As mentioned, the demand varies quite a lot by period; the following bar chart shows the total demand by period:
Now, we will take a closer look at the new Incremental Change Constraints input table:
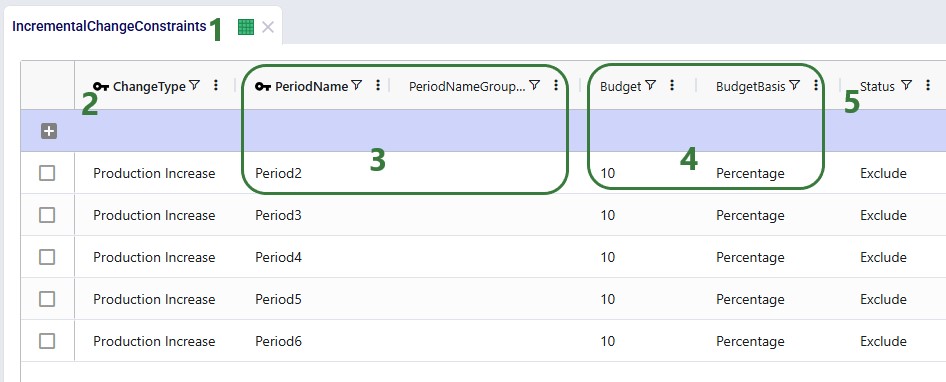
Please note that this table also has a Notes field, which is not shown in the screenshot. Notes fields are also often used by scenarios, for example to filter out a subset of records for which the Status needs to be switched based on the text contained in the Notes field.
The following 5 scenarios are included in this example model:
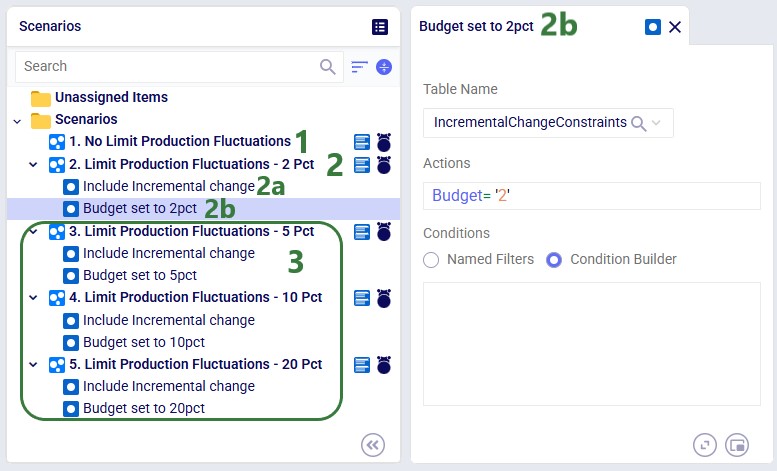
After running all 5 scenarios, we will first look at the 2 new output tables, and then at several graphs set up in the Analytics module specifically for this model.
The following screenshot shows the Optimization Incremental Change Summary output table:
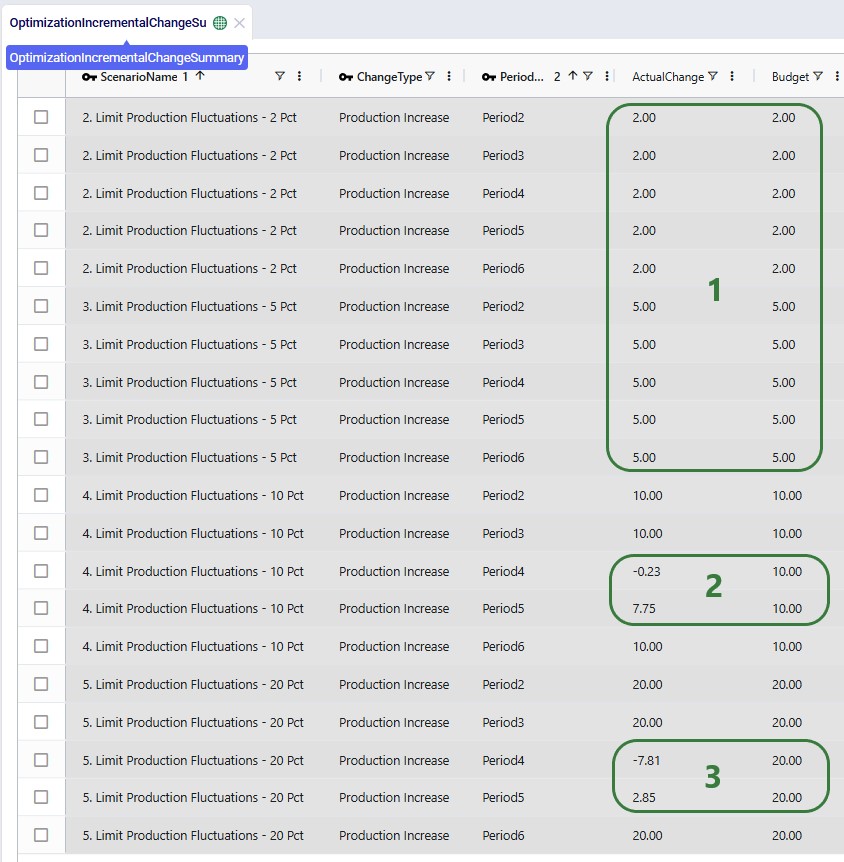
The other new output table, the Optimization Incremental Change Report, contains the changes at a more detailed level. For production increase incremental change types, it indicates the change in production at the individual facilities for the periods the constraint(s) are applied. In the next screenshot, we look at the report which is filtered for the fourth scenario and only the records for Facility_01 are shown:
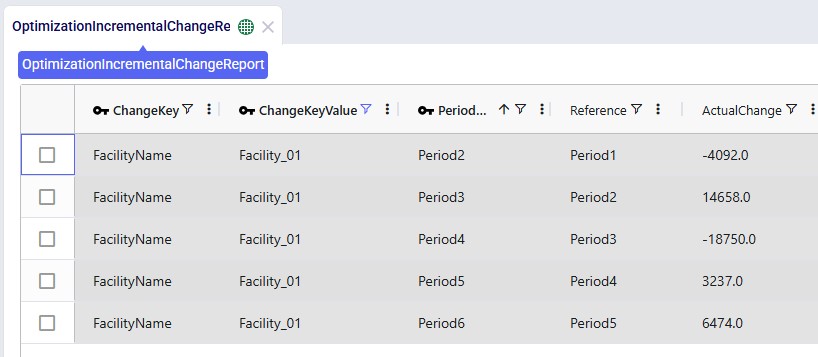
The Actual Change column here reflects the difference in the quantity produced between the period and the referenced (previous) period. The first record tells us that in Period2 Facility_01 produced 4,092 units less than it produced in Period1, etc.
Now, we will look at several graphs set up in the Analytics module. The names of the dashboards containing the graphs start with “Incremental Change - …”. The first one we will look at is the Production by Period graph found on the “Incremental Change – Production by Period” dashboard. Here we compare the first scenario (No Limit) with the most constrained scenario which is the second one (only 2% increase in production allowed in each subsequent month):
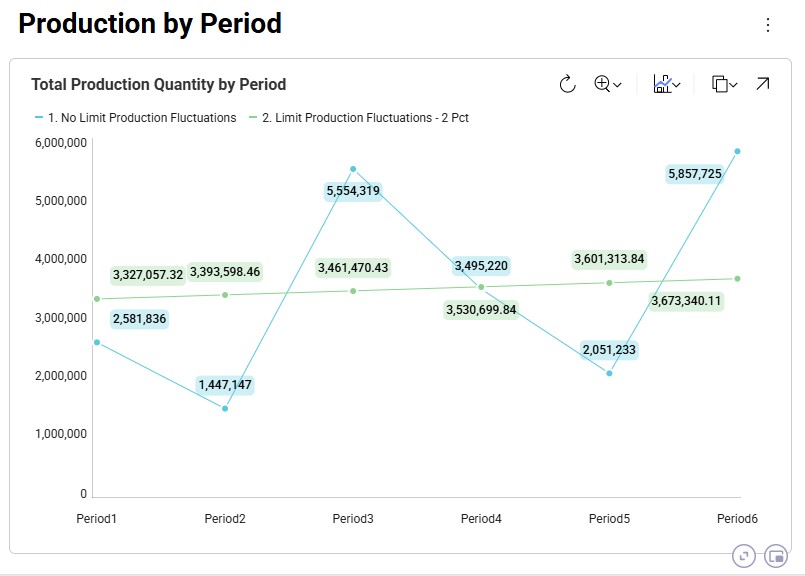
The blue line and numbers represent the production quantities of the first scenario (no limit). Since there are no limits set on how much production can fluctuate, the production is equal to the demand in that period to avoid any pre-build inventory and its holding costs. Since the demand varies greatly between each period, so does the production. For example, in Period2 the quantity produced is 1.45M units and in Period3 this is 5.55M units, which is a 280% increase.
The green line and numbers represent the production quantities of the second scenario (max 2% production increase). To even out the production and stay within the 2% increase restriction, we see that production in periods 1 and 2 is higher in this scenario as compared to the first one. We can deduce that inventory is being pre-built here in order to be able to fulfill the high demand in Period3. We will show the pre-build inventory levels by period in another upcoming dashboard.
The next graph, from the "Incremental Change - Demand and Production" dashboard, compares the production by period for all 5 scenarios using a bar-chart:
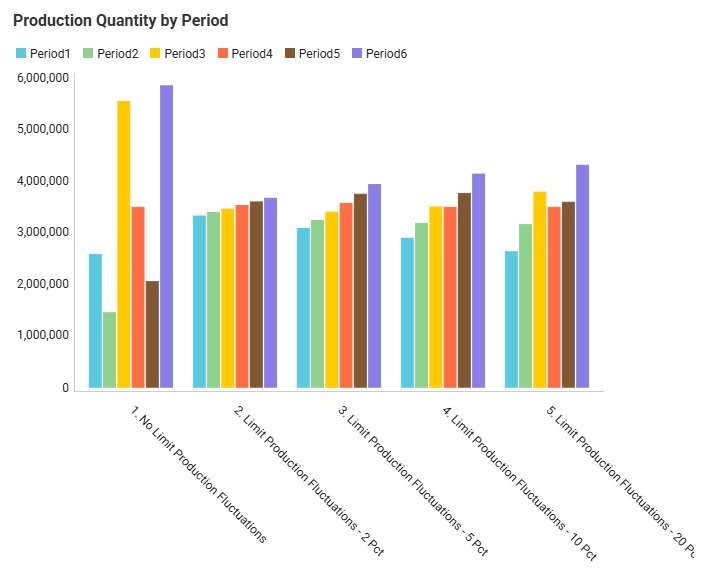
We see the same for scenarios 1 and 2 as we discussed for the previous graph: high fluctuations in scenario 1 and only slight increases period-over-period in scenario 2. Scenarios 3, 4, and 5 gradually allow higher increases in production (5%, 10%, and 20%), and we can see from the production outputs that in order to reduce cost of holding pre-build inventory in stock, the scenarios do show more fluctuations in the production quantity so that product is produced as close as possible in time to when the product is demanded, while adhering to the % increase limitations.
We can also illustrate this by looking at the amount of pre-build inventory across the periods for each scenario, which is shown on the “Incremental Change – Pre-build Inventory” dashboard:
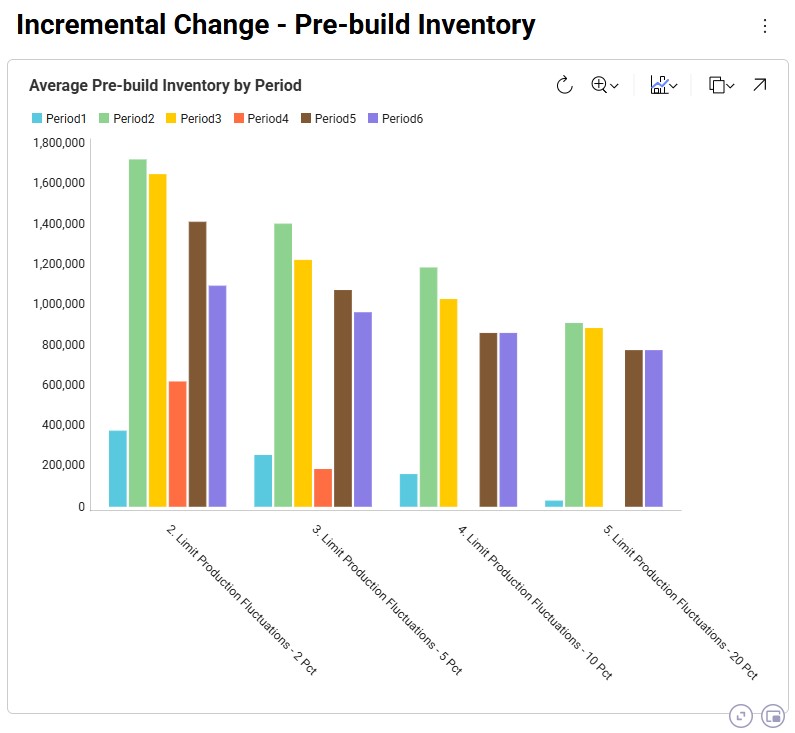
We notice that the first scenario is not shown here as it does not have any pre-build inventory in any of the periods: the production in each period matches the demand in each period to avoid any pre-build holding costs. For the other scenarios, we see, as expected, that the more stringent the limitation on the fluctuation in production quantity is, the more pre-build inventory is being held. In scenarios 4 and 5 (10% and 20% increases allowed), there is no need to have pre-build inventory in Period4 for example, whereas this is needed in scenarios 2 and 3 (2% and 5% increases allowed).
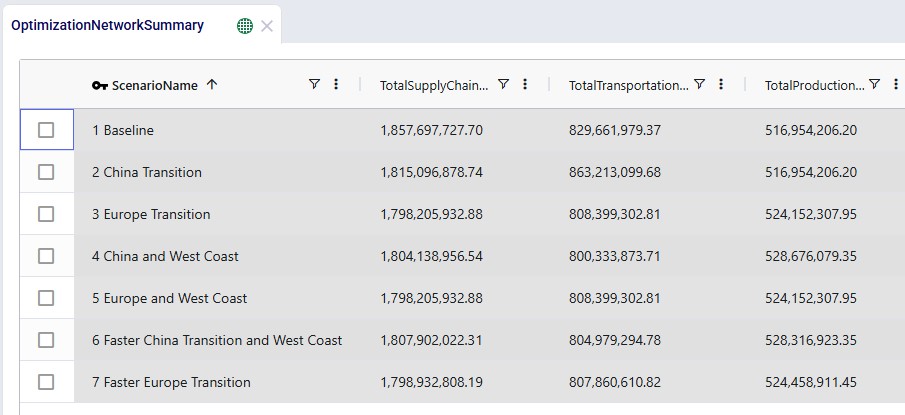
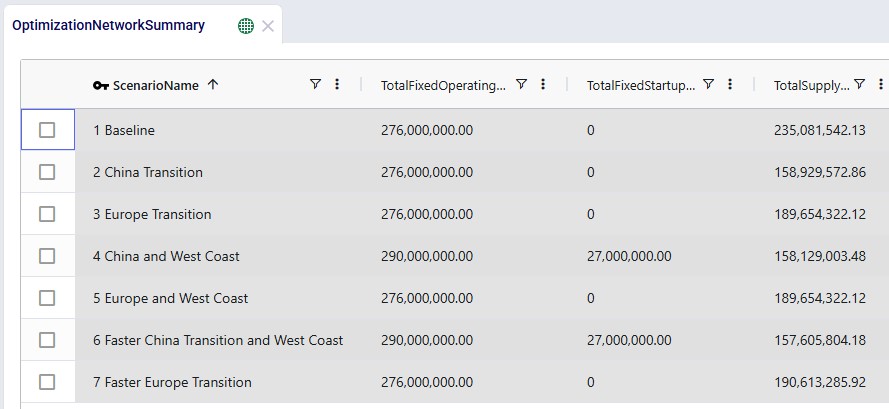
We can of course also look at the costs associated with each of the 5 scenarios, using the Optimization Network Summary output table:
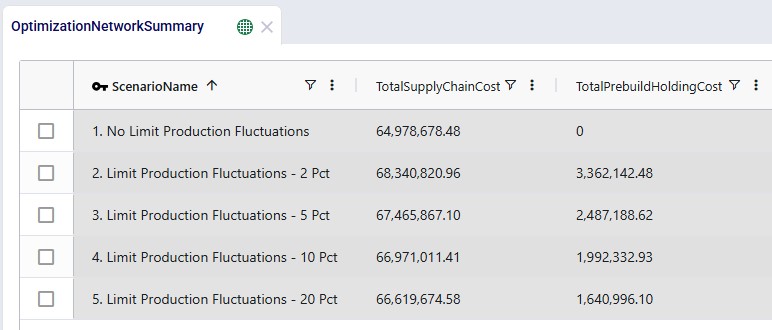
The costs are made up of transportation costs ($41.2M for all scenarios), in transit holding costs ($51k for all scenarios), production costs ($4.2M for all scenarios), outbound handling costs ($19.5M for all scenarios), and pre-build holding costs. Only the pre-build holding costs differ between the scenarios due to the timing of production being different because of the production increase incremental change constraints. As we saw above, no pre-build inventory was held in scenario 1, so the pre-build holding cost for this scenario is 0. Most pre-build inventory was held in the most stringent scenario, scenario #2, and therefore the pre-build holding costs are highest for this scenario, decreasing as the production increase change constraint is gradually loosened from 2 to 20%.
Finally, we will have a look at a map to see the flows from the facilities to the customers:
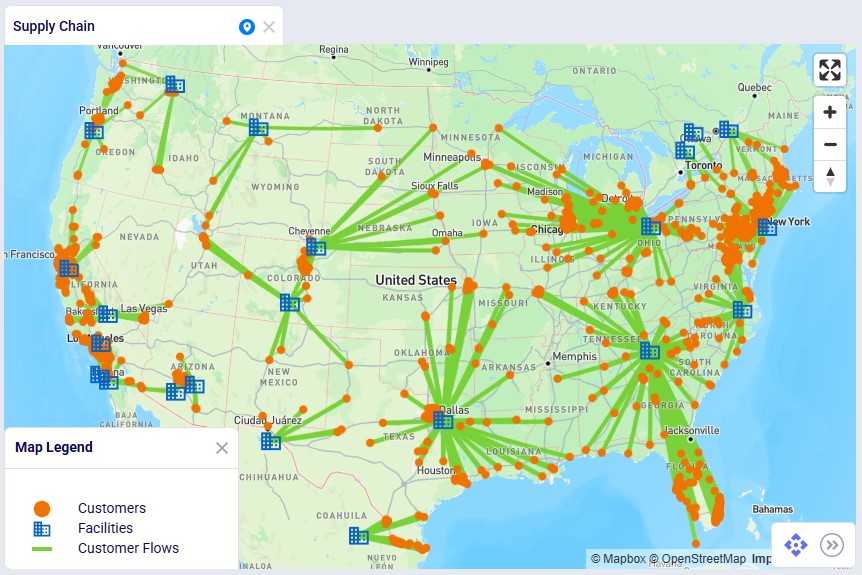
In this map we see all flows for all periods for scenario 3. We notice that customers source from their closest facility. Since this is a multi-period model, we can also configure the map to see the flows for just a single period or a subset of the periods, by using the fold-out periods toolbar located at the bottom-right in the screenshot.
This example demonstrates how Incremental Change can be used to determine the optimal sequence of supplier changes when transitioning from a mixed supplier base to a single-region sourcing strategy.
The model evaluates two potential transitions:
Supplier onboarding is limited to two suppliers per quarter, reflecting operational onboarding limits.
In addition, the model evaluates whether adding a new West Coast port and factory improves the network. These locations could realistically only become operational starting in 2028, which is modeled using incremental change constraints.
This example model, "Incremental Change - Supplier Base Transition", can be copied from the Resource Library if you want to follow along.
This example is based on the Global Supply Chain Strategy model from the Resource Library (here) and has been modified to demonstrate Incremental Change functionality.
This model includes two supplier regions:
Europe
China
The current supplier base consists of:
The additional suppliers are included in the model but initially inactive.
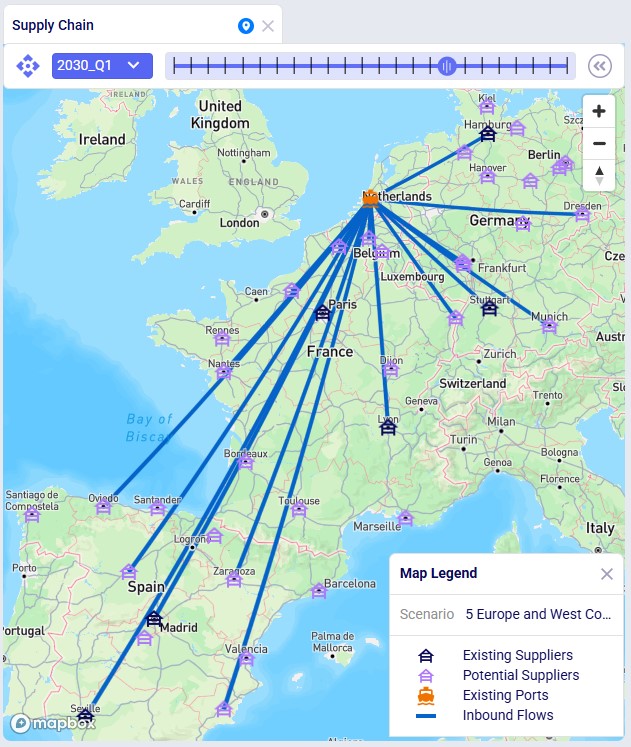
This screenshot shows the existing and potential suppliers in Europe:
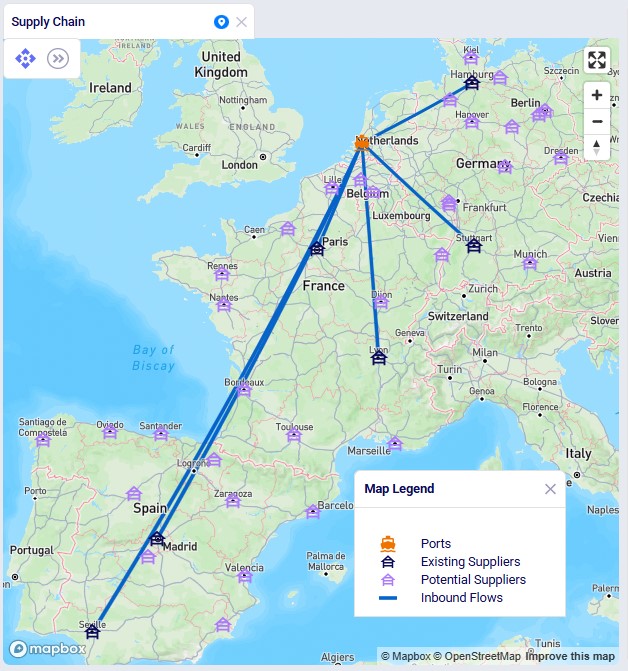
The next screenshot shows the existing and potential suppliers in China:
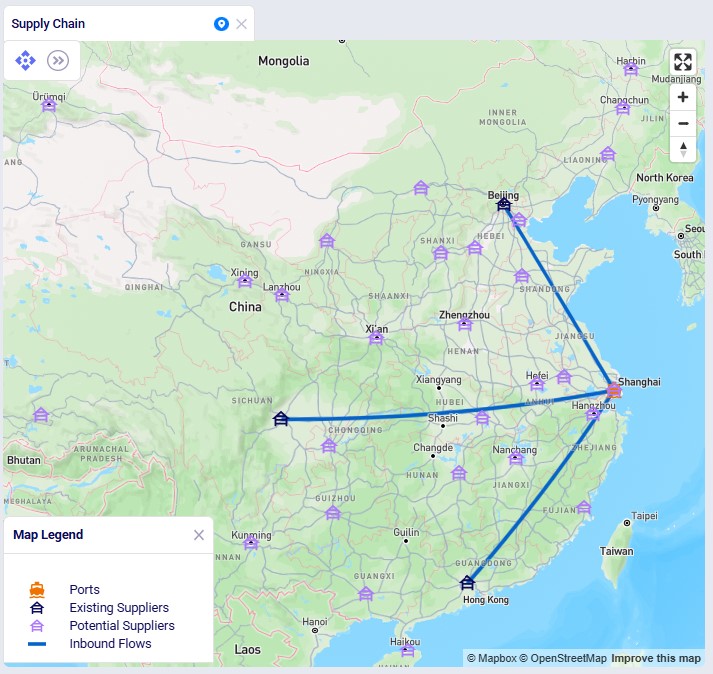
Materials flow through the network as follows:
The model also includes potential West Coast expansion locations:
These facilities are evaluated in selected scenarios.
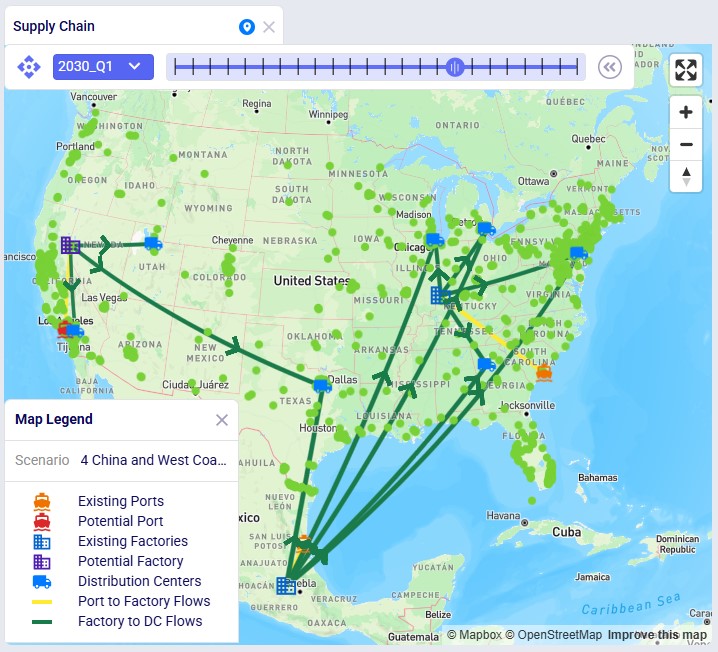
The following screenshot shows the port, factory, DC, and customer locations in North America, with the port to factory and factory to DC flows showing too:
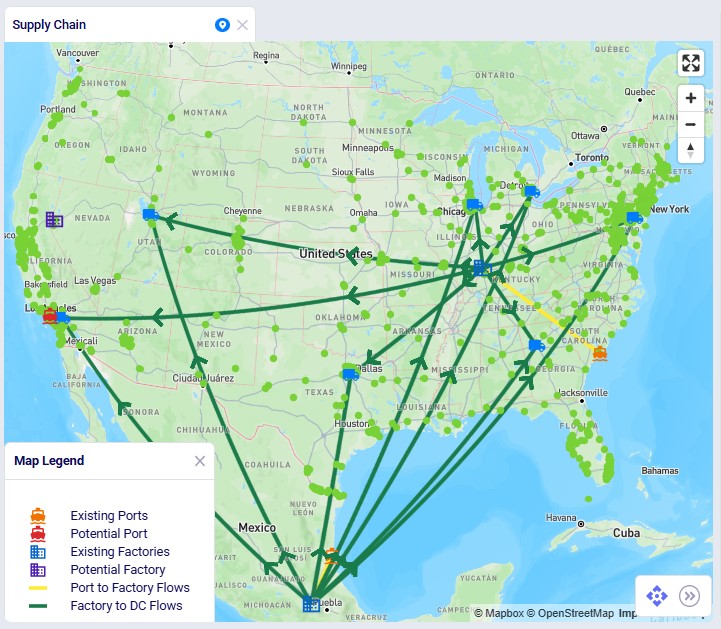
First, we will cover the basic inputs in this model that were added / modified from the original Global Supply Chain Strategy model. After that we will explain the inputs that have been added to model the supplier base transition and those that enable consideration of using the new port and factory on the US west coast.
Several changes were made to the base model to support the incremental change example:
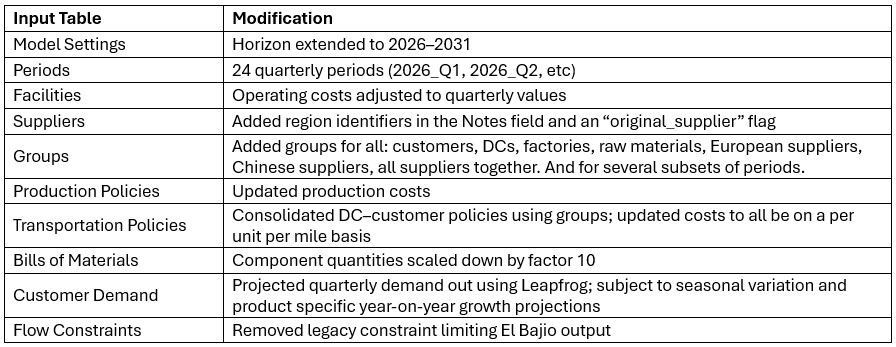
The model evaluates transitions to either an all-Europe or all-China supplier base under the following rules:
This supplier base transition is visualized on the following timeline:
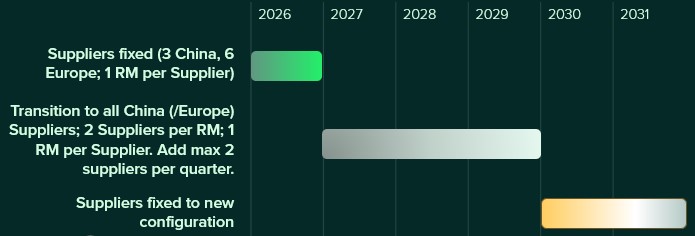
After running scenarios with the above transition settings, we will also run 2 accelerated transition scenarios:
This looks as follows on a timeline:

Supplier availability is controlled using two input tables:
Supplier Capabilities
Supplier Capabilities Multi-Time Period
Three configuration sets are included:

Scenarios activate the appropriate configuration by switching the Status field to Include for the relevant records.
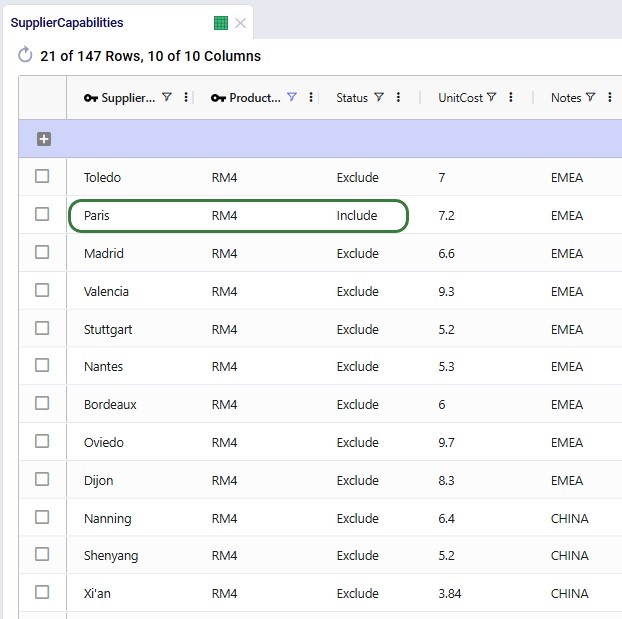
In the following screenshot of the Supplier Capabilities table, we see 12 (of the 21) suppliers that can supply RM4. Since the Paris supplier is the one which currently supplies this raw material, we see that the Status for that record is set to Include, whereas it is set to Exclude for all others. This is similarly set up for the other 8 raw materials. In scenarios where the supplier base is being shifted, the Status of the other records is set to Include.
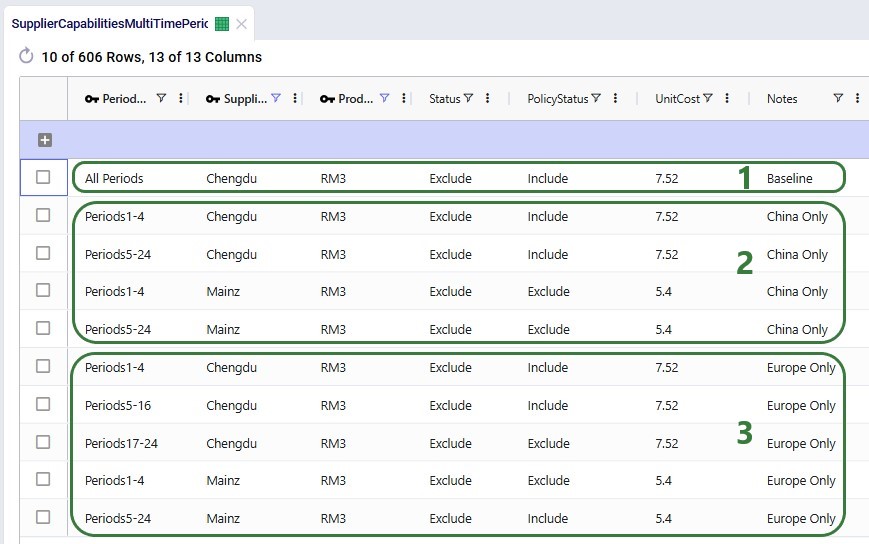
The next screenshot shows the Supplier Capabilities Multi-Time Period table which is filtered for Supplier Name = Chengdu or Mainz and Product Name = RM3. Chengdu (China) is the original supplier for RM3, while Mainz (Europe) is not currently used at all and will be considered for supplying RM3 in scenarios that transition the supplier base to Europe:
To ensure meaningful dual sourcing, each raw material must be supplied by two suppliers.
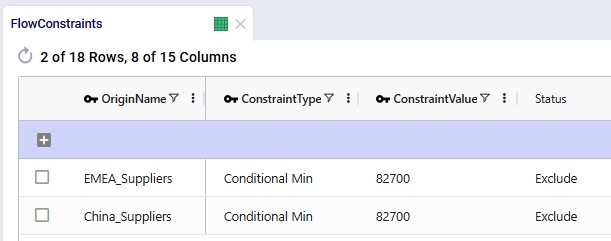
To prevent trivial allocations (e.g., one supplier providing only a few units), conditional minimum flow constraints require that each active supplier provides approximately 35% of total supply. This ensures both suppliers meaningfully contribute to supply.
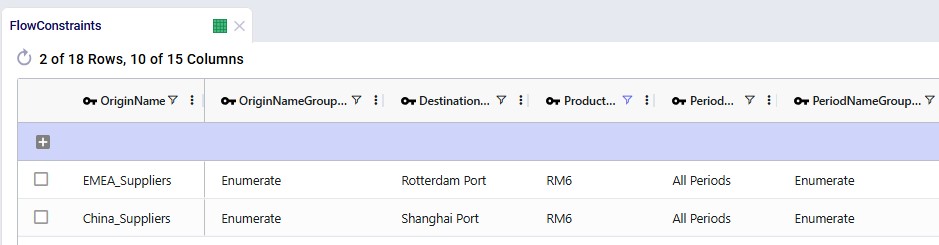
The 2 screenshots below show the setup for RM6 on the Flow Constraints input table:
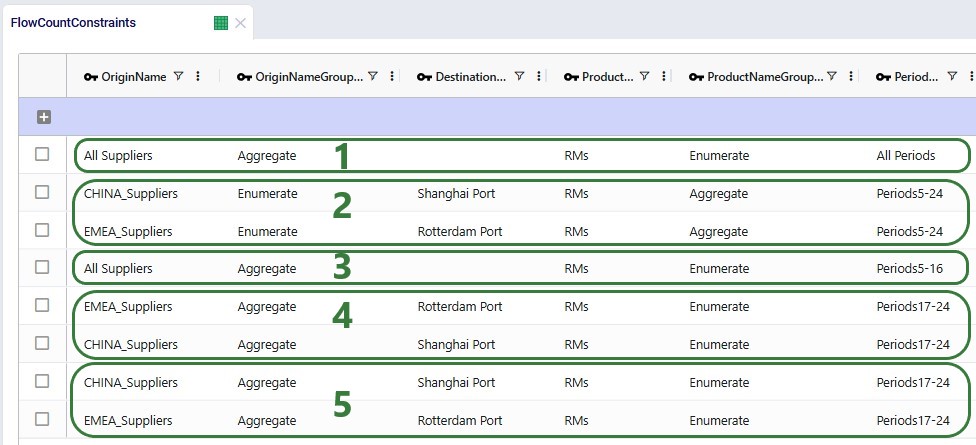
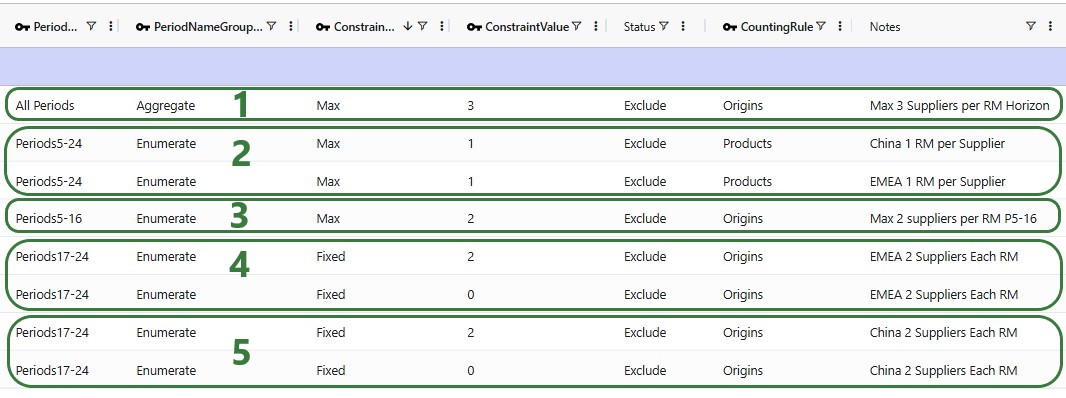
Additional flow count constraints enforce the supplier structure:
These 2 screenshots show the flow count constraints which are used (Status switched from Exclude to Include) in the scenarios where the supplier base is shifted; they are explained underneath the second screenshot:
Incremental Change controls the rate of supplier onboarding.
Two configurations are included:
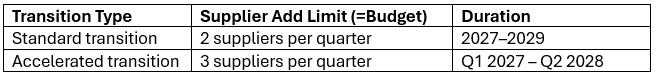
Additional constraints prevent supplier changes after the transition period.
The first 2 constraints shown in the screenshot below are for the standard transition type (Budget = 2 during transition, 0 after) and are included (Status switched to Include) in the scenarios where the supplier base is shifted. The bottom 2 constraints are used together with the one in the second record for scenarios modeling the accelerated transition (Budget =3 during transition, 0 after):
The model evaluates adding:
These facilities:
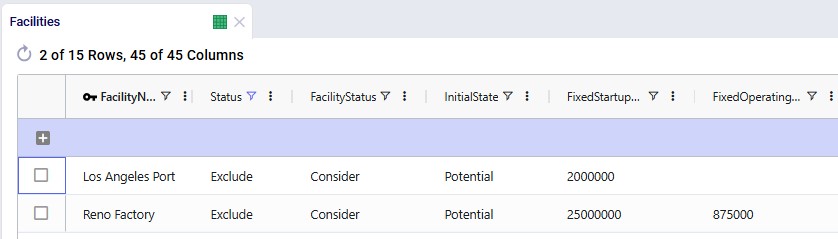
Facilities table:
Records were added for Los Angeles Port and Reno Factory. As these are currently not existing locations and will be considered for inclusion, their Facility Status = Consider and Initial State = Potential:
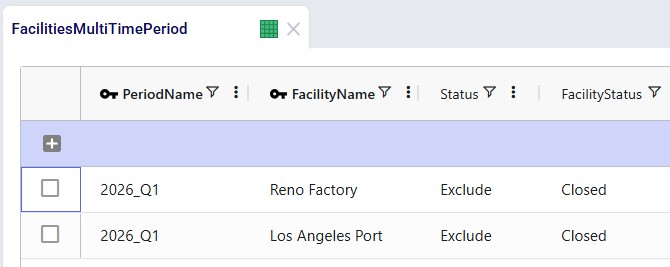
Facilities Multi-Time Period table:
Since we only want to consider including the west coast locations from 2028 onwards, we need to make sure that at the beginning of the model horizon they are closed. This is done by adding 2 records for 2026_Q1 to the Facilities Multi-Time Period table setting the Status for both the Reno Factory and the Los Angeles Port to Closed, see screenshot below. For the remaining periods in the model the Incremental Change Constraints (see further below in this section) take care of when the factory and port are considered for opening.
Production Policies table:
Records are added for the Reno Factory so it can manufacture all 3 finished goods, using the existing BOMs:
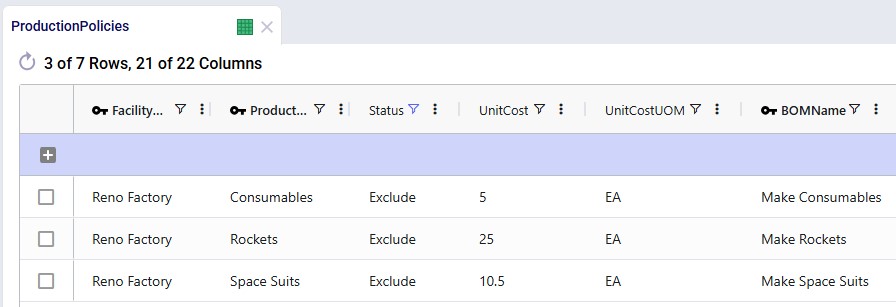
Transportation Policies table:
Records are added so that Los Angeles Port can receive raw materials from the ports in Rotterdam and Shanghai, the Los Angeles Port can ship these to the factory in Reno, and Reno Factory can serve the finished goods to all 7 DCs:
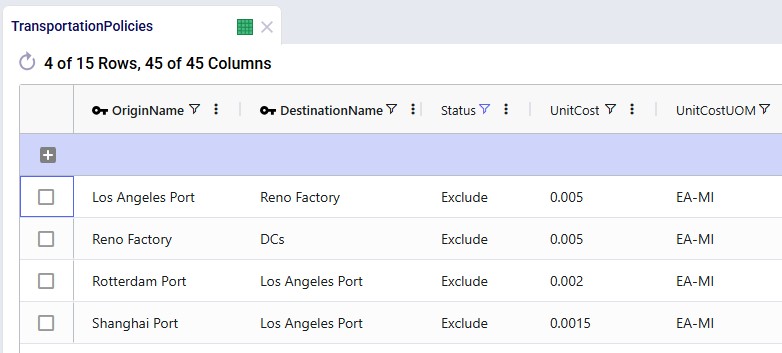
Incremental Change Constraints table:
Here, 2 records are added to set up the desired behavior of allowing the Reno Factory and Los Angeles Port to be added to the network from 2028_Q1 onwards.
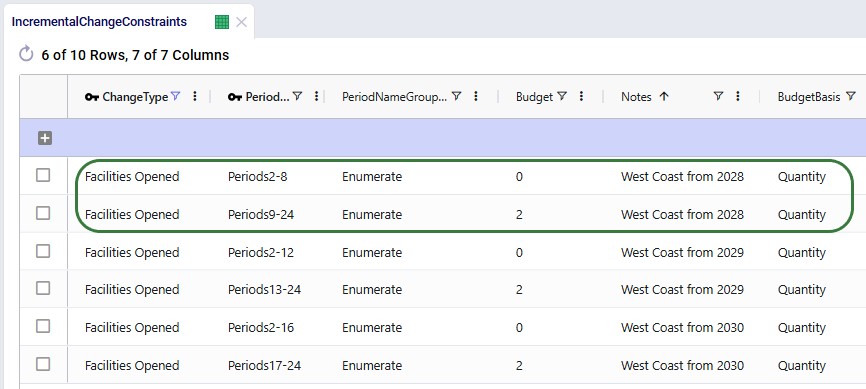
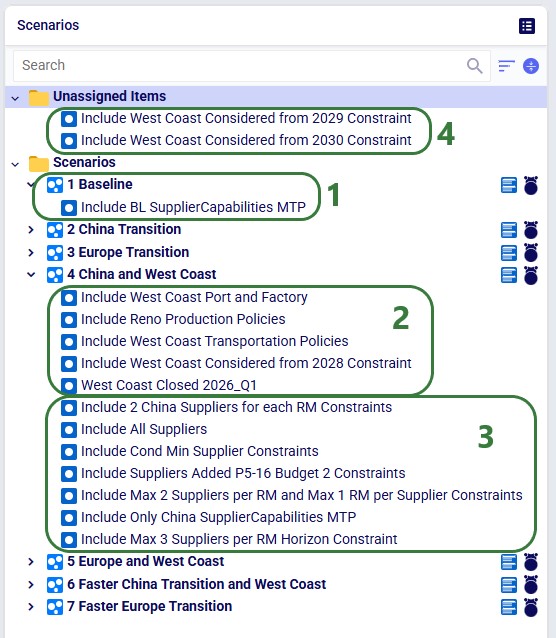
The other 4 "Facilities Opened" records in this table are not used in this model. They were added in case users want to set up and run some scenarios themselves where the west coast port and factory are allowed to be added from 2029 (records 3 and 4) or from 2030 (records 5 and 6) onwards.
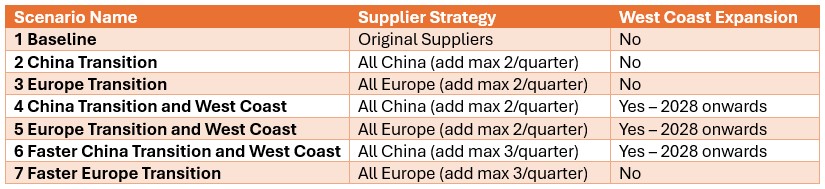
The following table shows the scenarios that were run in this example model. Initially the first 5 were run and based on the results, number 6 and 7 were added and run too:
The Scenarios module of this example model looks as follows:
For running the scenarios, 2 of the technology parameters were changed from their defaults:

After running all scenarios, it is time to examine the outputs. We will start by looking at the new Optimization Incremental Change Summary and Optimization Incremental Change Report output tables and then visualize the supplier base changes on maps and a timeline grid. For these, we will mostly focus on scenarios 4 and 5 which show all incremental change constructs we have used in the model. Finally, we will also have a look at the financial impact and compare all scenarios.
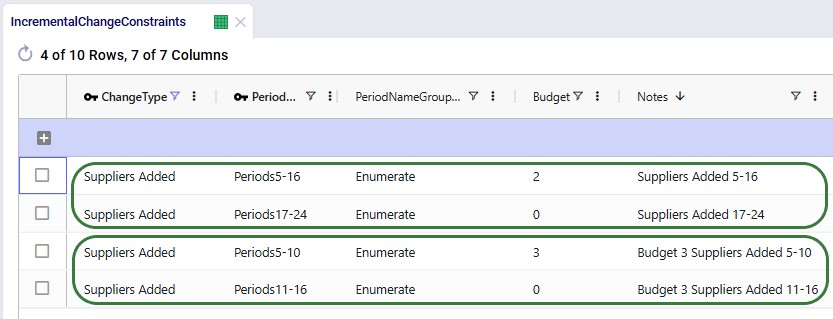
The Optimization Incremental Change Summary table shows how much of each change budget is used in each period. Two screenshots of this output table are shown next; in both, the table is filtered for scenario number 5 (field not shown) where the supplier base is moved to Europe and adding the west coast locations to the network is considered:
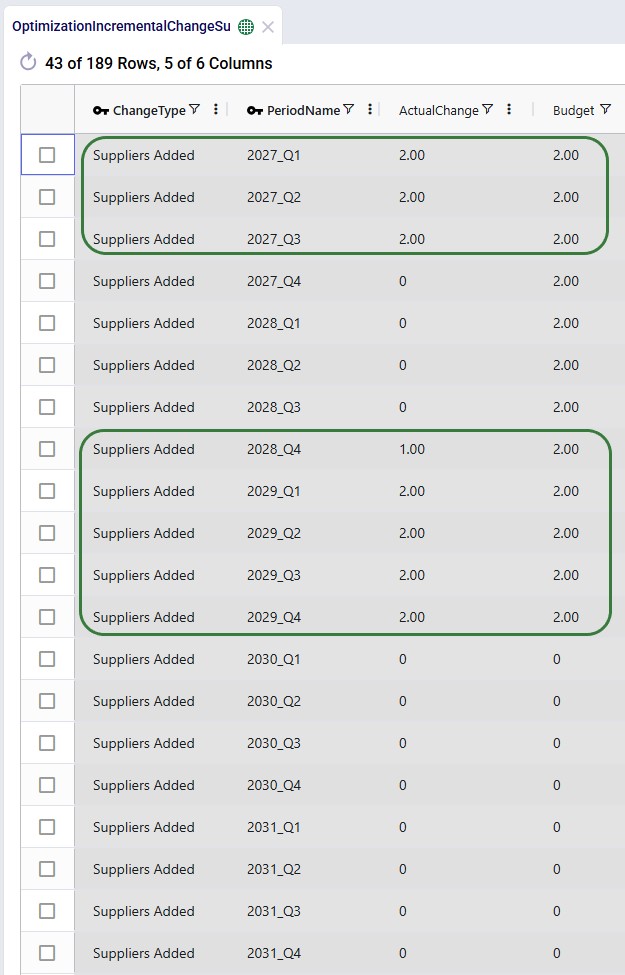
During each of the first 3 quarters of the transition period 2 suppliers were added, then there is a pause in adding suppliers, and towards the end of the transition period, another 9 suppliers are added, essentially as late as possible. We can interpret this as:
The next screenshot shows the same table, still filtered for scenario 5, but now the records for the Facilities Opened change type constraints are shown:
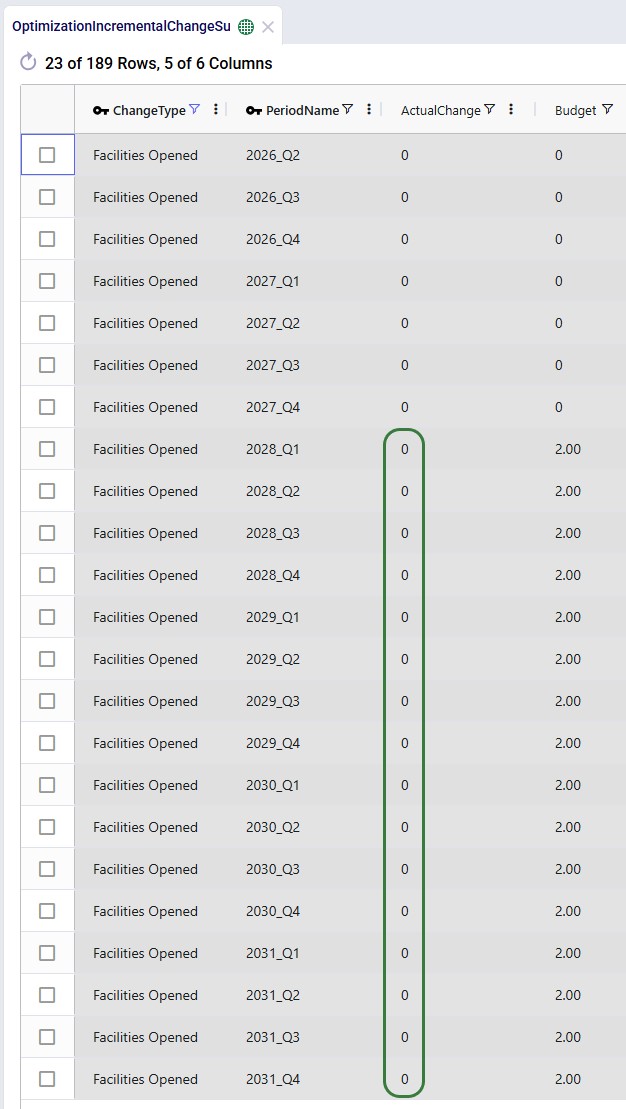
We see that the budget was 2 for each of the periods in the 2028 – 2031 timeframe, but the Actual Change column indicates that no change (0) happened in any of those periods. In this scenario, it is not beneficial to start using the west coast port and factory anytime from Q1 2028 onwards.
Next, we will cover the Optimization Incremental Change Report output table. This table has a record for each incremental change that was made, including details on what the change was. This table is filtered for scenario 4 (field not shown) where the supplier base is moved to China and the west coast locations are considered (note that records beyond Q1 2029 are not shown here):

From the first 4 records for Q1 of 2027, we can tell that suppliers in Hefei and Taiyuan were added to the supplier base, while suppliers in Lyon and Madrid were removed. Similarly, 2 suppliers are added and removed in each of the next 2 quarters. Then in Q1 of 2028, the Reno Factory and Los Angeles Port are opened, which is apparently beneficial to do as early as possible when moving the supplier base to China. This is due to the lower transportation costs because of the shorter distance from Shanghai to Los Angeles as compared to going to the Charleston or Altamira ports.
In summary:
The next map shows the final configuration of the supplier base for scenario 4 where it is moved entirely to China. Notice that we have used the Period selector bar (at the top of the map) to show the map for Q1 of 2030 when the transition is complete. You can use this period selector to step through the periods to see the gradual changes over time.
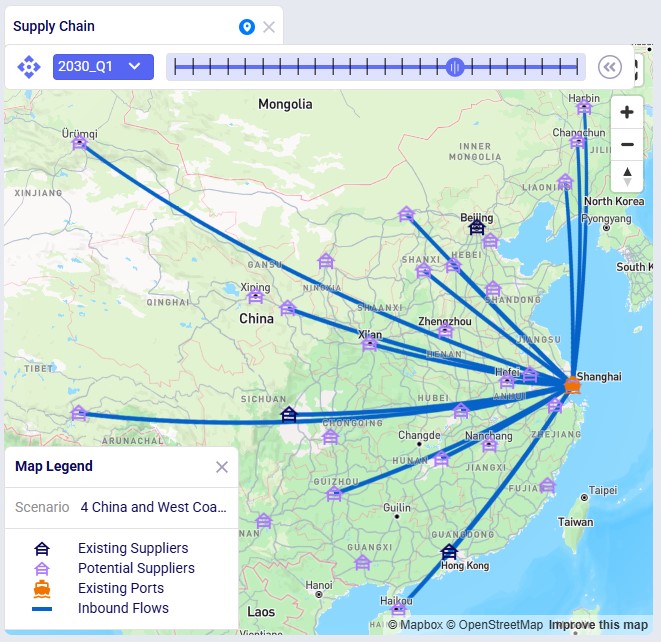
The next map is also for scenario 4 but now showing the North American locations and flows (except for the DC – Customer flows) for the same period of Q1 2030. We see that the Los Angeles Port and Reno Factory are being used in this scenario.
Similar to the first map shown above, the next map shows the final supplier configuration in Q1 2030 for scenario 5, where the whole base is moved to Europe:
The next 2 timeline grids on the Supplier Transition Timeline dashboard (Analytics module) are generated from a custom table “timeline_rm_bysupplier_byperiod”, which in turn was generated from the Optimization Supply Summary output table. The appendix describes the steps to create the custom table and how to re-create it in case (new) scenarios are added / adjusted and run.
The first screenshot is for scenario 4, the second for scenario 5. They show which supplier supplies which RM when. Note that Q1-Q3 of 2026 are not included as the supplier configuration is equal to the Q4 2026 configuration. Similarly, the timeframe of Q2 2030 through Q4 2031 is not included in this dashboard either, since the supplier configuration is equal to the Q1 2030 configuration. Not all suppliers and period columns are shown in the screenshots, users can scroll horizontally and vertically in the dashboard to examine the full timeline.
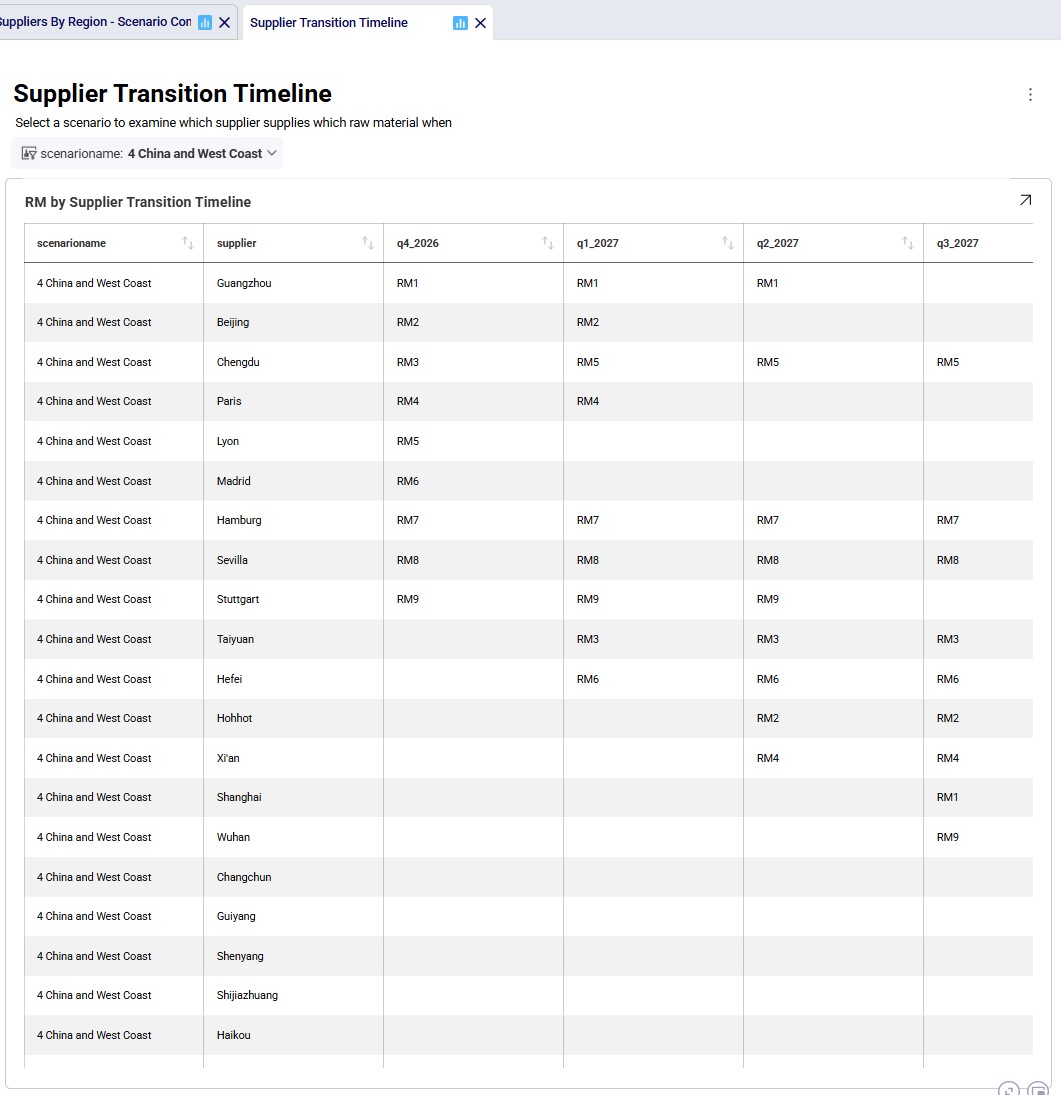
Some things we notice here for scenario 4 are:
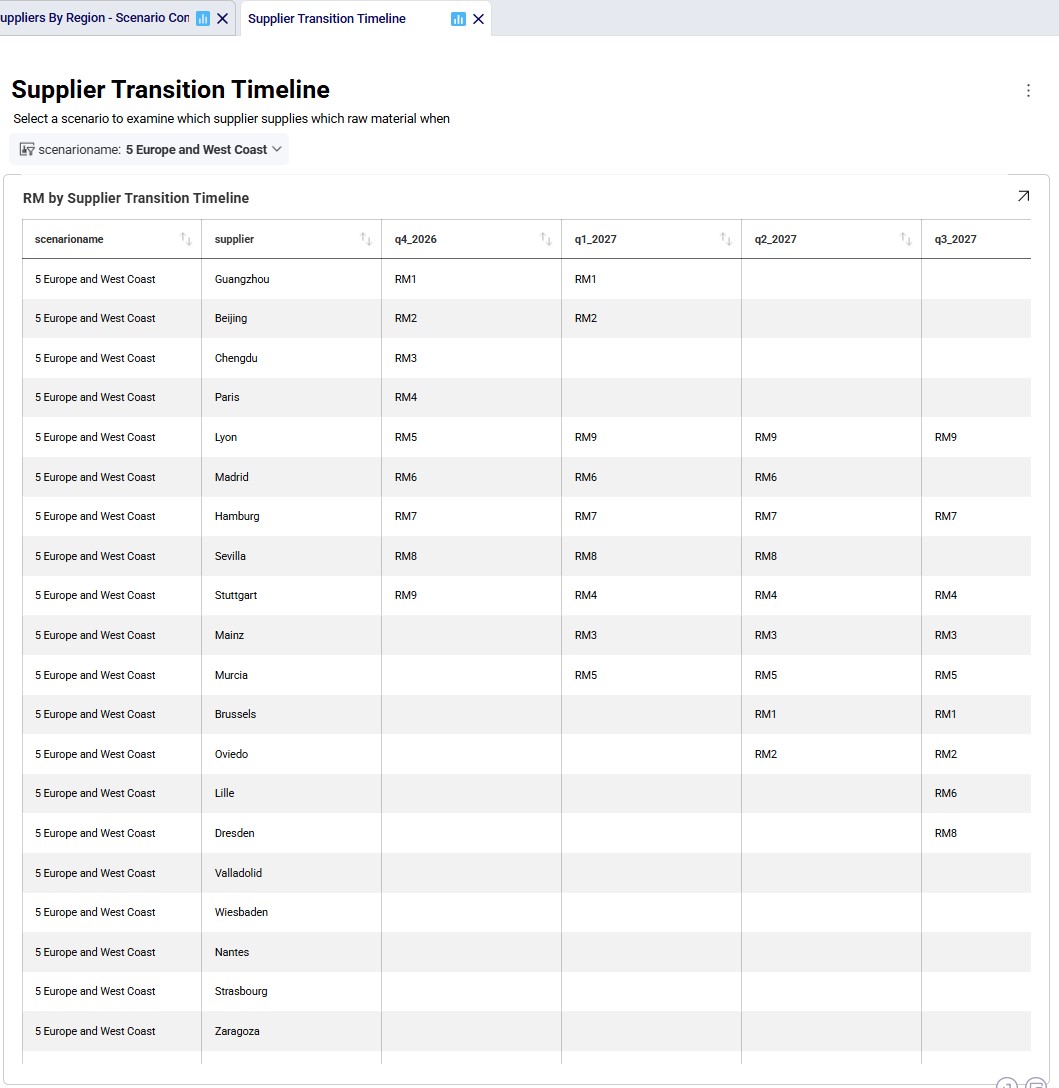
Some things we notice examining the above grid for scenario 5 are:
Since we are interested in looking at the impact of requiring the supplier base to be transitioned over sooner, scenarios 6 and 7 were run too where the budget for adding suppliers is set to 3 per quarter. We know from scenarios 4 and 5 that the west coast locations are only used when moving the supplier base to China, therefore we run scenario 6 (where we speed up the transition to the China supplier base) with these locations still considered. We do not consider them in scenario 7 where we speed up the transition to the Europe supplier base.
We will now have a look at how the costs compare for all 7 scenarios that were run with the next 2 screenshots of the Optimization Network Summary output table and the screenshot of the “Financials: Scenario Cost Comparison” chart. The latter can be found on the Scenario Comparison dashboard in the Analytics module:
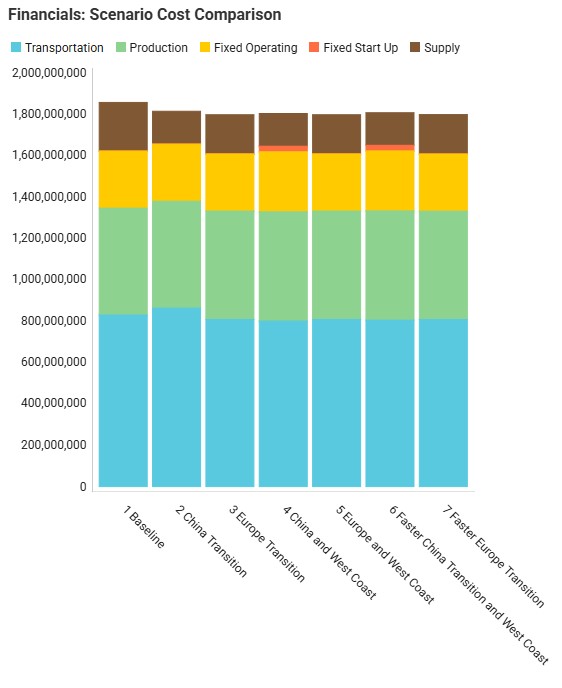
Comparing all scenarios reveals:
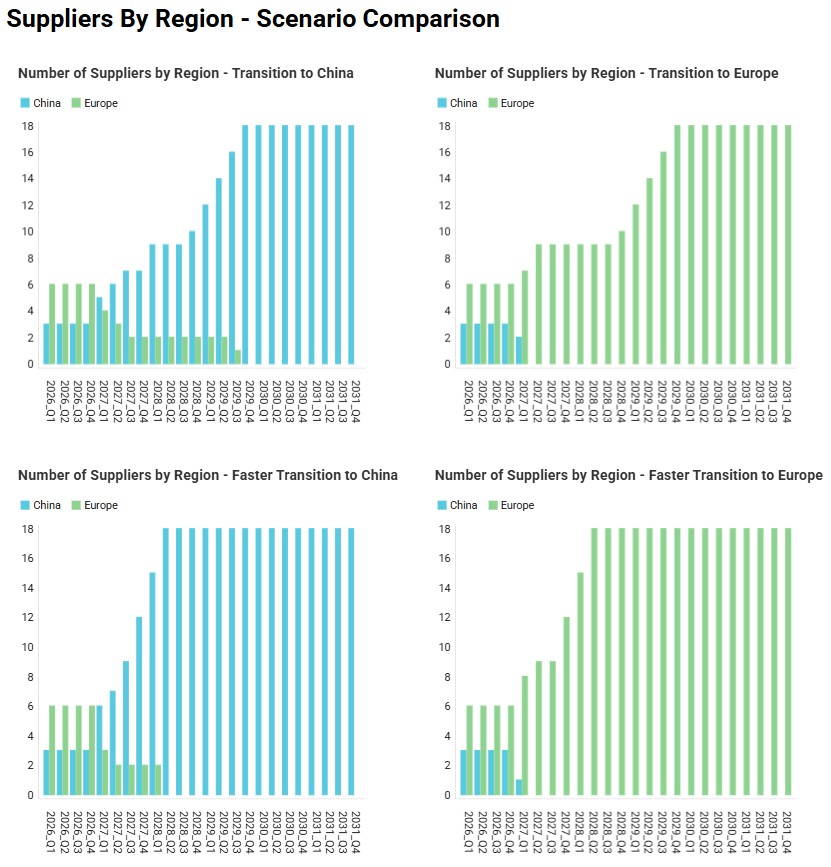
Finally, the following 4 charts for scenarios 4-7 which show the number of suppliers by region over time can be found in the “Suppliers by Region – Scenario Comparison” dashboard in the Analytics module:
Please do not hesitate to contact Optilogic support at support@optilogic.com in case of questions or feedback.
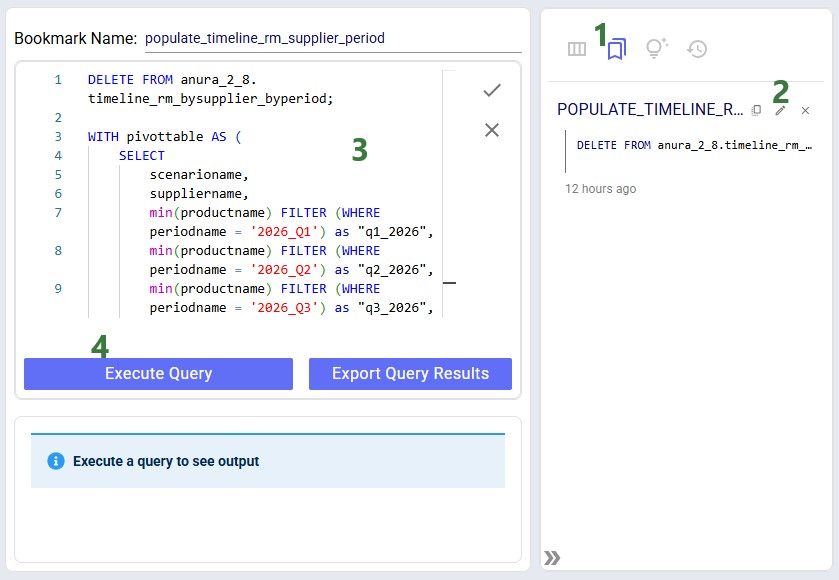
To create the timeline grid on the Supplier Transition Timeline dashboard, we first created a custom table named timeline_rm_bysupplier_byperiod, where we added columns for scenarioname, supplier, and 1 column for each period in the model. The latter we named q1_2026, q2_2026, etc. rather than 2026_Q1, 2026_Q2, etc. (which is how the periods in the model are named) as column names in custom tables cannot start with a digit.
Next, this table was populated from the outputs in the Optimization Supply Summary output table, using a SQL Query, which is saved in the model and can be used to refresh the custom table if scenarios are modified/added and (re-)run. For this we use the SQL Editor application on the Optilogic platform:
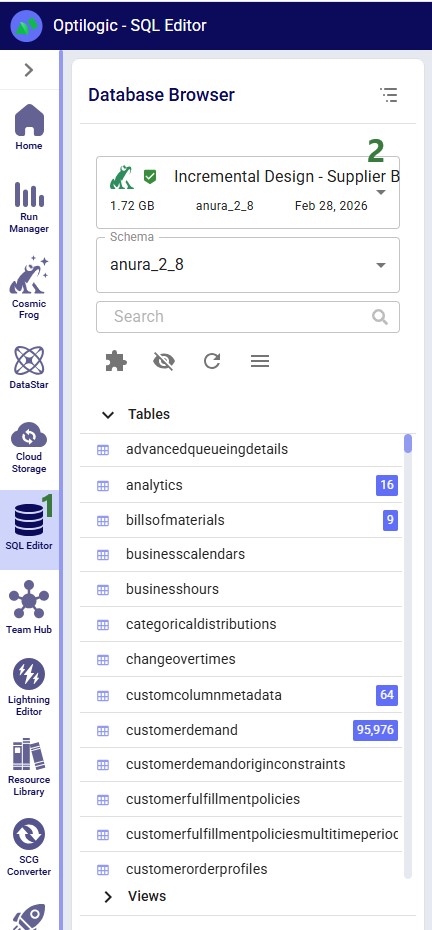
The following screenshot shows the central part and right-hand side panel of the SQL Editor application:
Please note that this custom table, the Supplier Transition Timeline dashboard, and SQL Query to populate it are specific to how this model is set up. All three will need to be updated if the model is changed in certain ways. For example, when adding/removing/renaming periods or if it becomes possible for 1 supplier to supply more than 1 raw material within a period.
Scenarios let you rapidly explore "what-if" questions against an existing Cosmic Frog model. Define one or more data changes (scenario items), run the scenarios, then compare outputs - all without altering your baseline input data.
Follow these five steps to run your first scenario:
💡 Tip: Use Leapfrog (Cosmic Frog's AI assistant) to create scenarios and items from plain-language prompts - no manual configuration needed.
A scenario defines one or more input-table changes to apply before running a solve. Common examples include:
In the context of this documentation, we mean the following with scenario and scenario item:
In other words: a scenario without any scenario items uses all the data in the input tables as is (often called Baseline); most scenarios will contain 1 or more scenario items to test certain changes as compared to a baseline.
Open the Scenarios module from the Module menu. A freshly opened module looks like this:
The Scenario drop-down (top of module) provides quick access to common actions:
Each scenario is associated with one engine. To change it, select the scenario and use the radio buttons in the central panel:
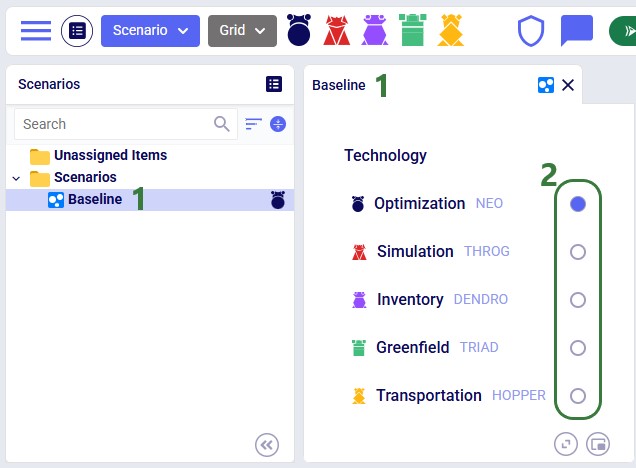
📝 Note: Running with multiple technologies
You can solve the same scenario with more than one engine sequentially: assign the first technology → run → change technology → run again. Be aware that any scenario edits between runs may cause results to differ for subsequent runs.
💡 Tip: Dendro workflow
To optimize inventory policies with Dendro: first build and validate a Throg (simulation) scenario, then switch its technology to Dendro and run.
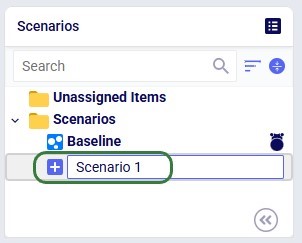
Right-click an existing scenario or the Scenarios folder and choose New Scenario, or use the New Scenario option from the Scenario drop-down menu. Enter a name when prompted:
Select the target scenario, then right-click → New Item (or use the Scenario drop-down). Name the item - its configuration panel opens automatically:
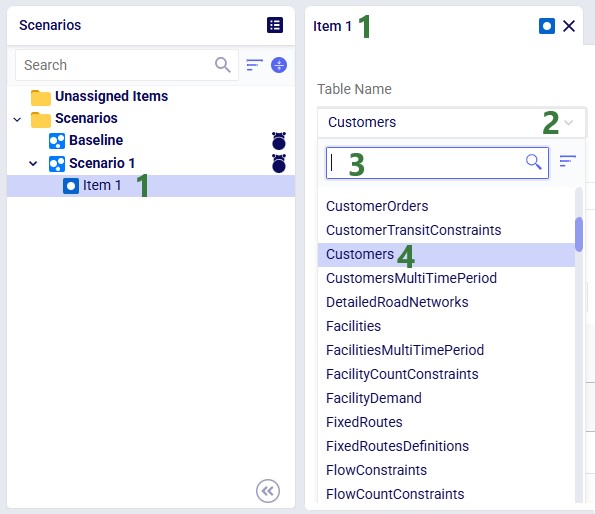
After selecting the table, specify the change in the Actions field. Intelli-type suggests column names as you type:
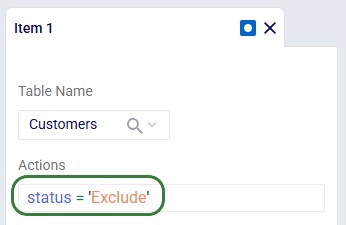
Once the column to change has been typed in, we can set its new value. In our example we want to set the value of the status column to Exclude:
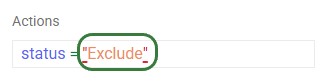
Intelli-type also validates syntax. Incorrect quote style (need to use single quotes, not double quotes):
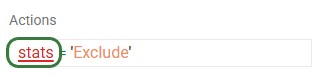
Unrecognized column name:
📝 Note: For full Actions syntax, see the Writing Syntax for Actions Help Center article.
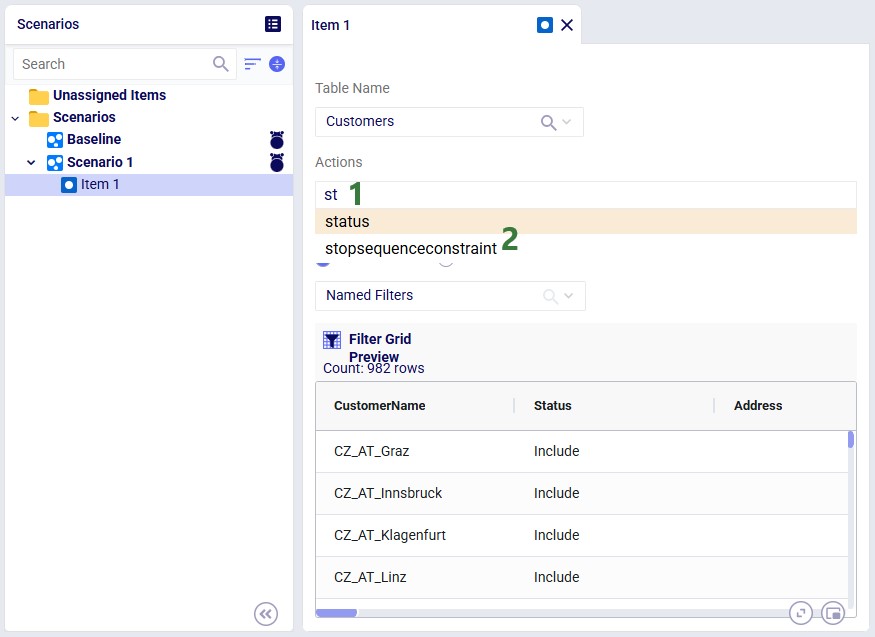
By default, a scenario item's action applies to every record in the selected table. Add a filter to restrict which records are changed. Two methods are available:
If Named Filters exist for the selected table, you can apply one directly to the scenario item:
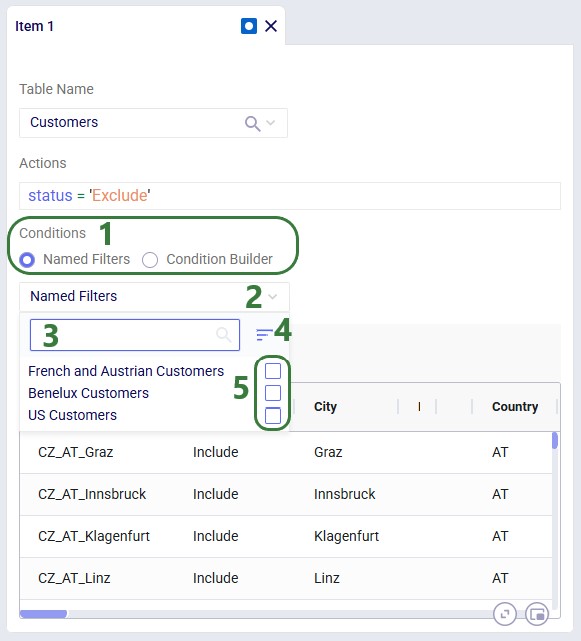
After selecting a filter, the Filter Grid Preview updates to show exactly which records will be affected:
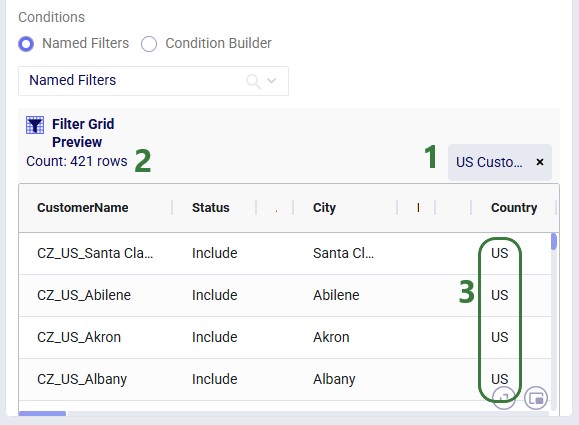
💡 Tip: Why prefer Named Filters?
Named Filters are pre-validated - you have already confirmed they select the right records when creating the filter. The Condition Builder requires you to write syntax manually, which is more error-prone. Named Filters also show a record preview. (Preview for Condition Builder is coming soon.)
📝 Note: One Named Filter per scenario item
Each scenario item supports a maximum of one Named Filter. If you need to combine multiple filter conditions, create a new Named Filter that merges all required conditions.
Use the Condition Builder when no applicable Named Filter exists, or for ad hoc conditions:
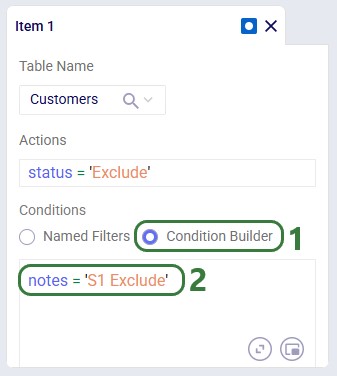
📝 Note: For condition syntax, see the Writing Syntax for Conditions Help Center article.
When multiple items modify the same column in the same table, they execute top-to-bottom. Order matters. Consider the following 2 scenarios where both scenario items are applied to the Quantity column in the Customer Demand table:
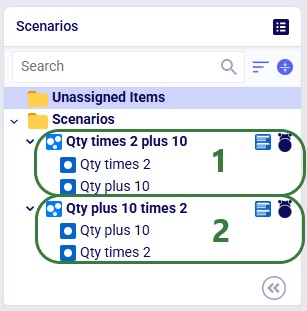
💡 Tip: Drag items up or down within a scenario to reorder them.
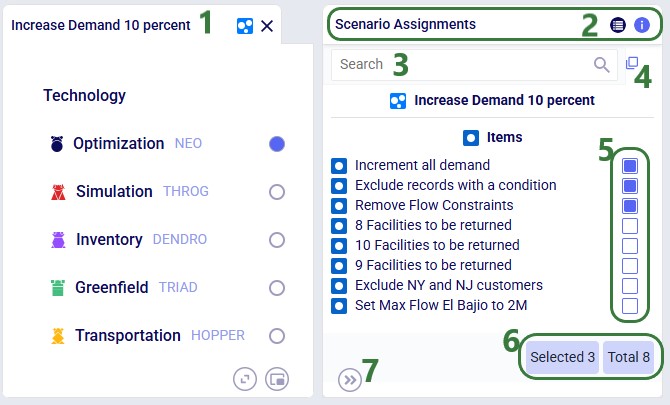
A single scenario item can be shared across multiple scenarios. The Item Assignments panel (right side) appears automatically when an item is selected:
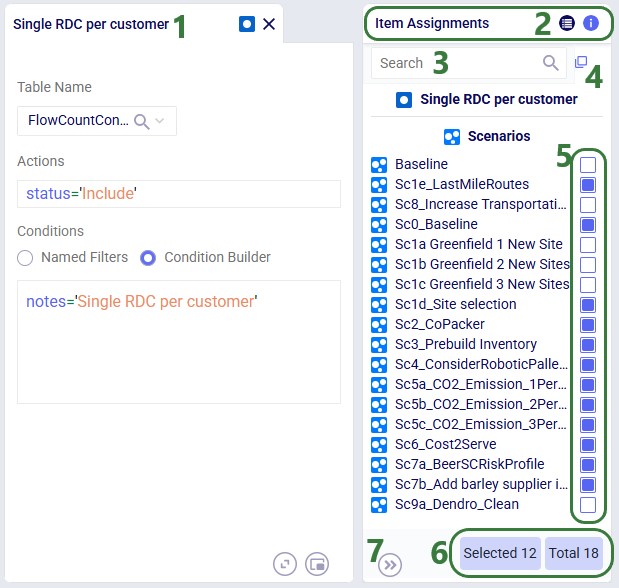
Switch to the Item Information tab on the same panel to edit the item's name or add a description:
The Scenario Assignments panel (right side) appears when a scenario is selected, showing all available items and which are assigned:
Switch to the Scenario Information tab to edit the scenario name or add a description:
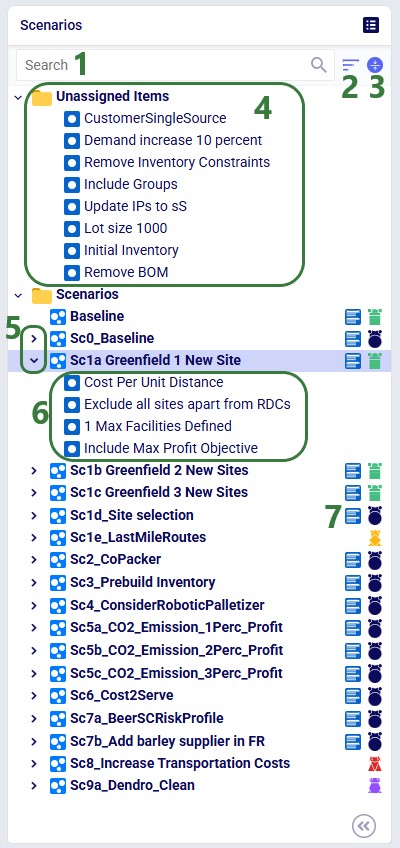
The scenarios list includes several navigation and status indicators that become useful as your model grows:
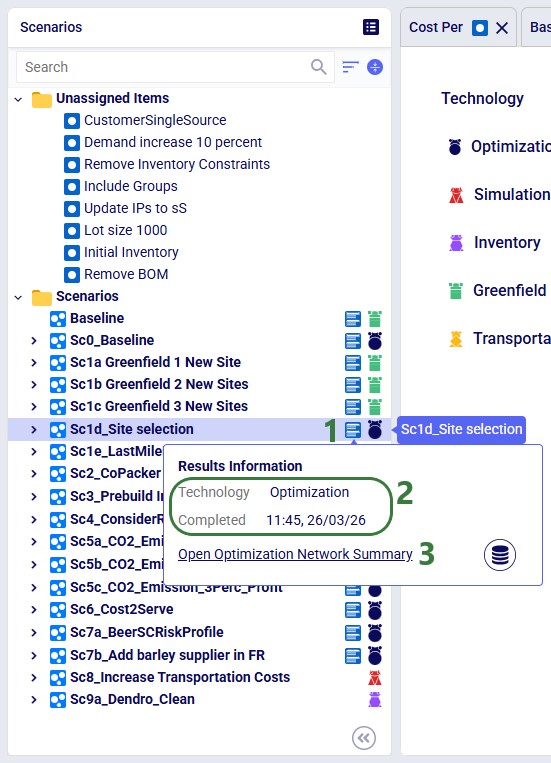
Click the green Run button (top right in Cosmic Frog), select the scenario(s) to solve, and configure technology parameters. See the Running Models & Scenarios in Cosmic Frog Help Center article for full details.
Sensitivity @ Scale automates demand-quantity and transportation-cost sensitivity analysis with a single click. See the Sensitivity at Scale Scenarios Help Center article for more information.
In addition, there are three S@S-related utilities available in the Utilities module:
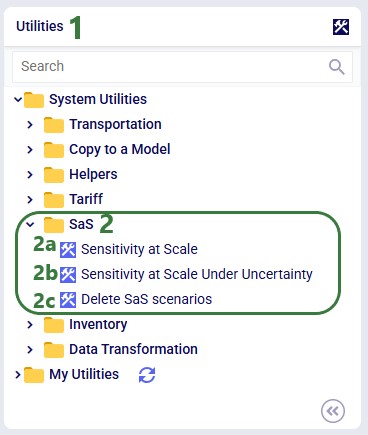
📝 Note: See the How to Use & Create Cosmic Frog Model Utilities Help Center article for details on using and building utilities.
Select one or more scenarios or items, then right-click ? Delete or use the Delete option from the Scenario drop-down menu at the top of the module. Key behaviors to keep in mind:
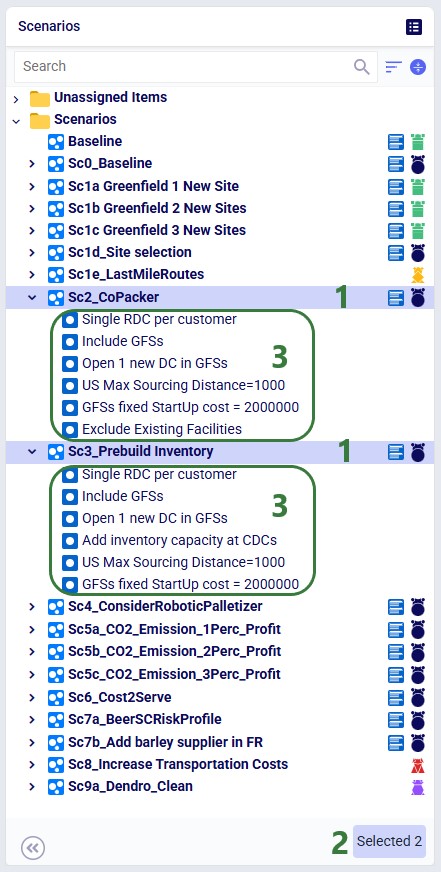
Deleting removes only the two scenarios. Items used exclusively by those scenarios move to Unassigned Items; items shared with other scenarios remain untouched.
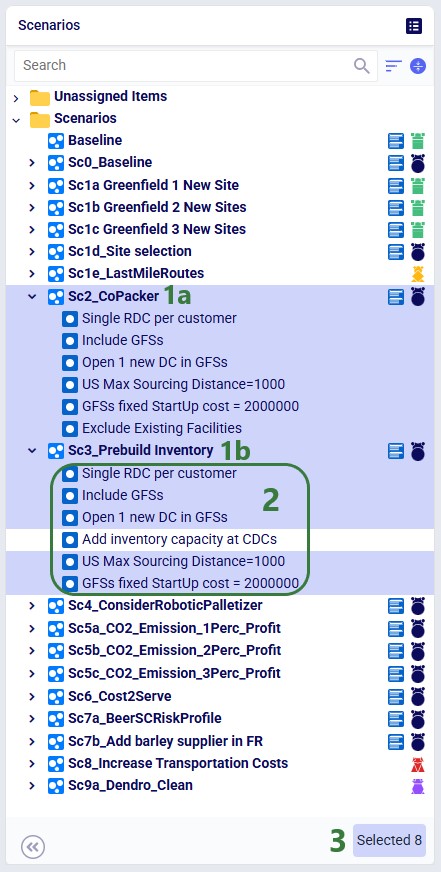
Deleting removes both selected scenarios and all 6 selected items - including from any other scenarios that use them. The one unselected item in these 2 scenarios, "Add Inventory capacity at CDCs", remains.
⚠️ Important: Deleting a scenario item removes it from all scenarios that it is assigned to, not just the selected scenario. Review item assignments before deleting.
Use Delete Scenario Results (context menu or Scenario drop-down) to clear output data for one or more scenarios without removing the scenarios themselves:
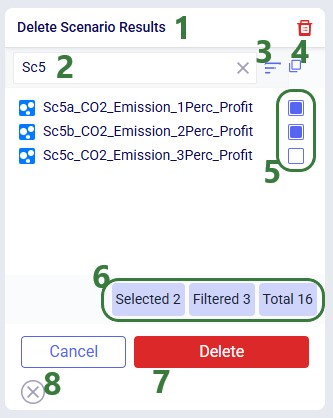
Think through scenario naming conventions ahead of time. You can for example:
Most input tables include Status and Notes fields. A powerful scenario pattern is:
This keeps all data in the model without interfering with the Baseline.
Custom columns let you store alternative values in a table and reference them in scenario items, e.g.:
The Copy Scenarios utility (Utilities module → Copy to a Model) copies a single scenario or all scenarios from one model to another, including all items and assignments.
Use Leapfrog for scenario and item creation, and also for manipulating scenario-specific data.
Leapfrog can create scenarios and scenario items from a plain-language description - ideal for quickly spinning up variations without manually configuring each item. See the specific section on this in the Getting Started with Leapfrog AI Help Center article.
🔧 Leapfrog Use Case: 2026 Demand Projections from 2025 Numbers
Model 2026 demand from 2025 quantities using a custom growth projections table. Leapfrog can be utilized to set this up, so no external tool needs to be used:
Happy scenario modeling! As always, please contact our Support team on support@optilogic.com for any questions or feedback.
The Run Python task allows you to execute Python scripts within a DataStar macro. You select a script, define its inputs (arguments), and run it as part of your workflow. This is ideal when built-in tasks are insufficient or when you want to reuse existing Python logic.
The Run Python task is especially useful when:
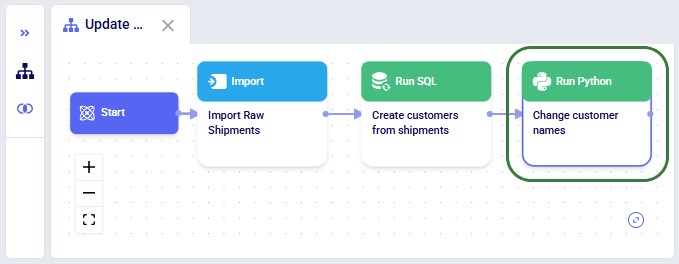
This walkthrough uses the end state of the DataStar Quick Start: Creating a Task using Natural Language guide as a starting point. At that point, a raw_shipments table has been imported and a Run SQL task has produced a customers table with unique customers. We will use a Run Python task to transform customer names from the format CZ1, CZ10, CZ100 to Cust_0001, Cust_0010, Cust_0100 - ensuring alphabetical sort matches customer number order and aligning the prefix with other data sources. The transformation steps are:
The screenshot below shows the "Change customer names" Run Python task added to the macro:
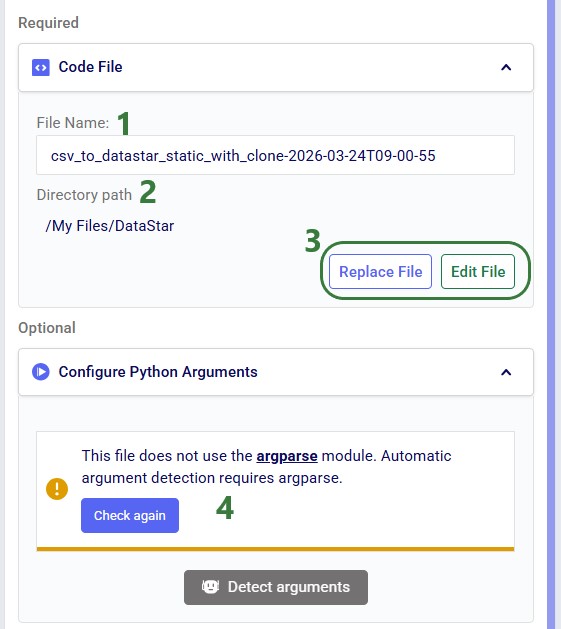
Once a Python task is added to the macro canvas, its configuration tab opens on the right:
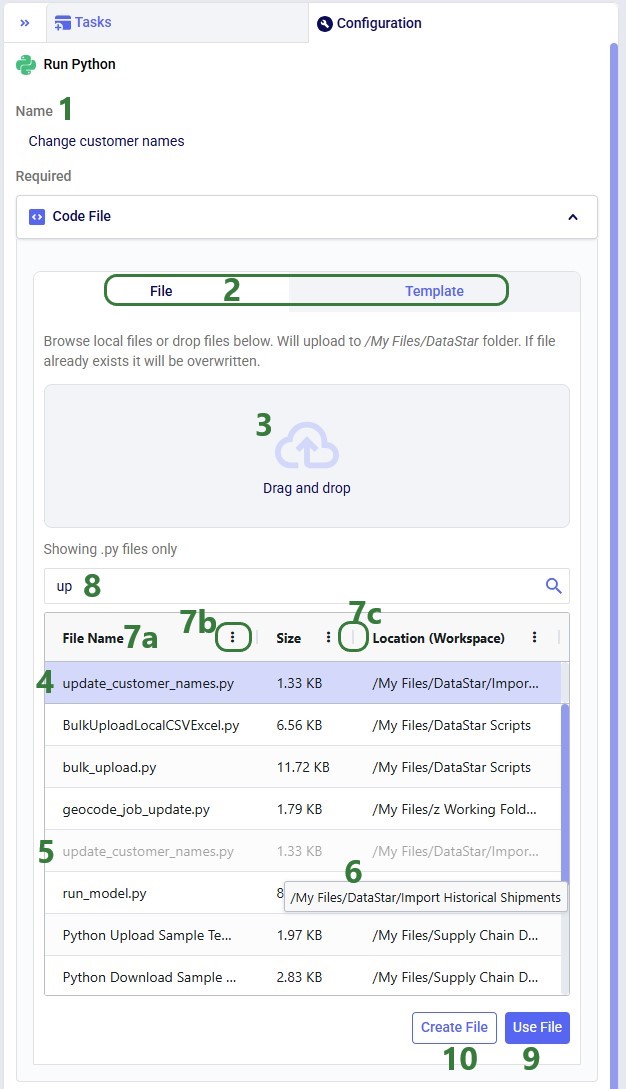
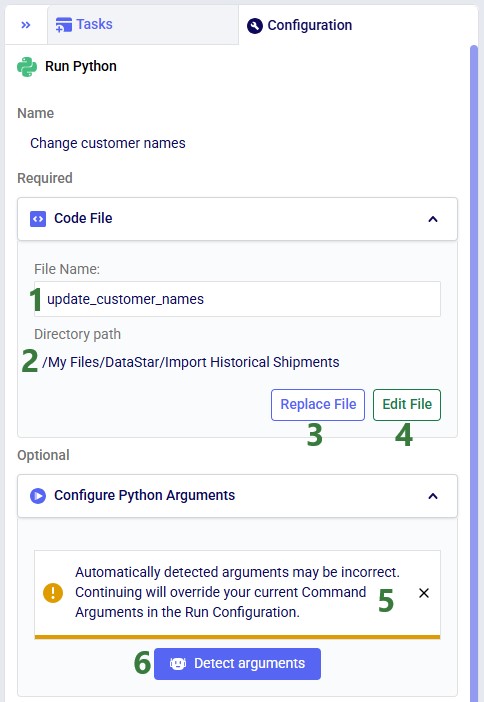
After clicking Use File with update_customer_names.py selected, the configuration updates as follows:
Before configuring arguments, we will cover the update_customer_names.py script. We can review its arguments so we can verify auto-detection is correct and look at the script body to understand what it does. You can copy the full script text from the Appendix.
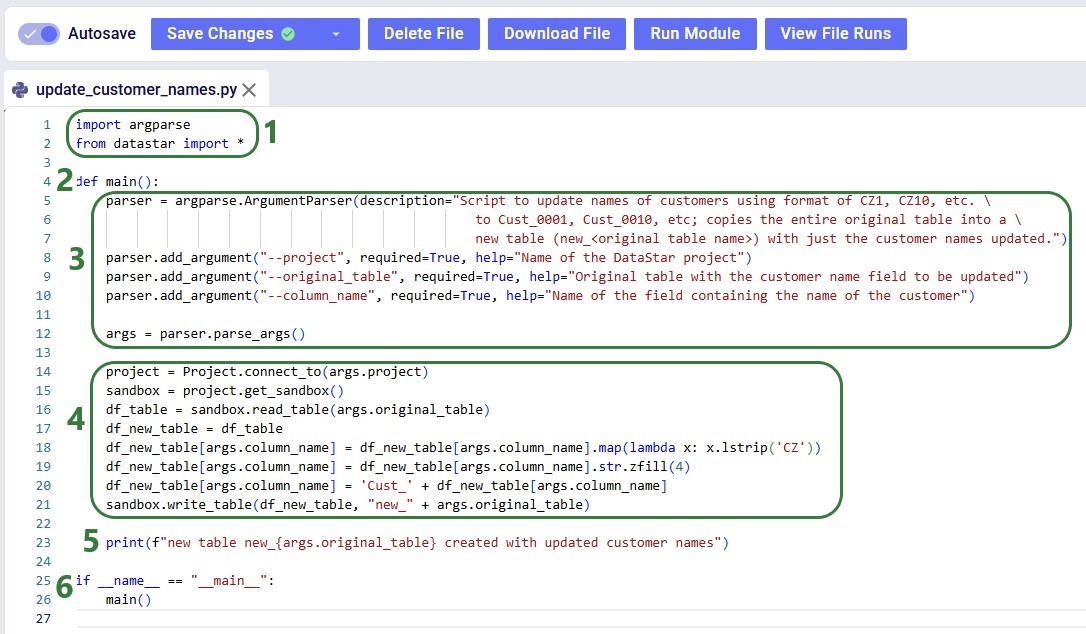
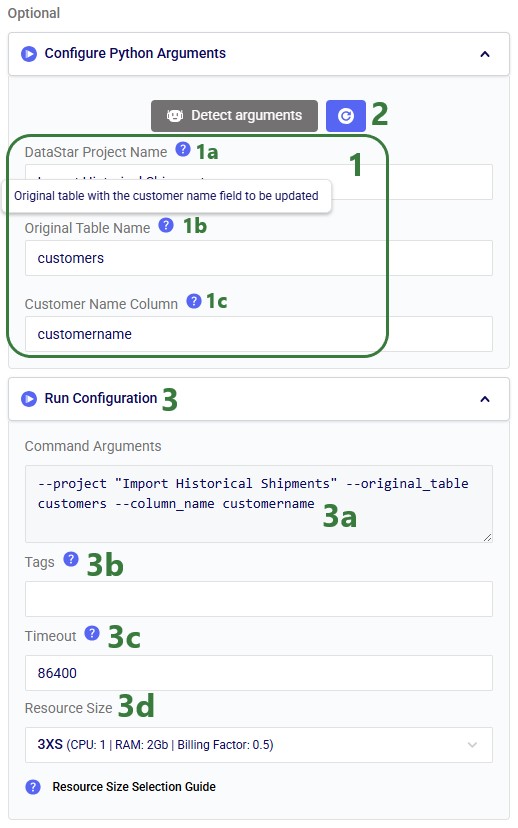
With the script understood, let us use Detect arguments and configure the task:
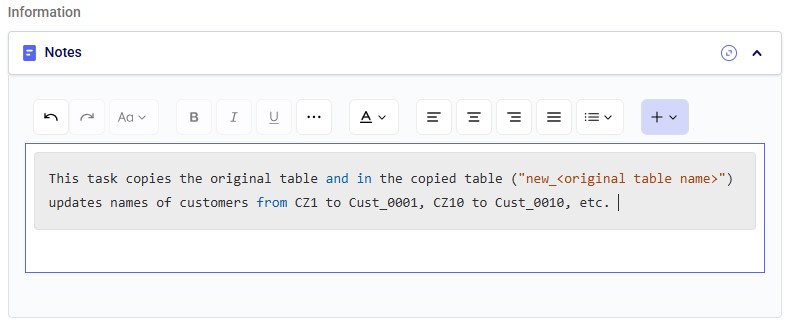
The Notes section is the final configuration area. It is especially valuable for complex tasks or collaborative projects, enabling users to quickly understand what the task does. Formatting options are available above the text box:
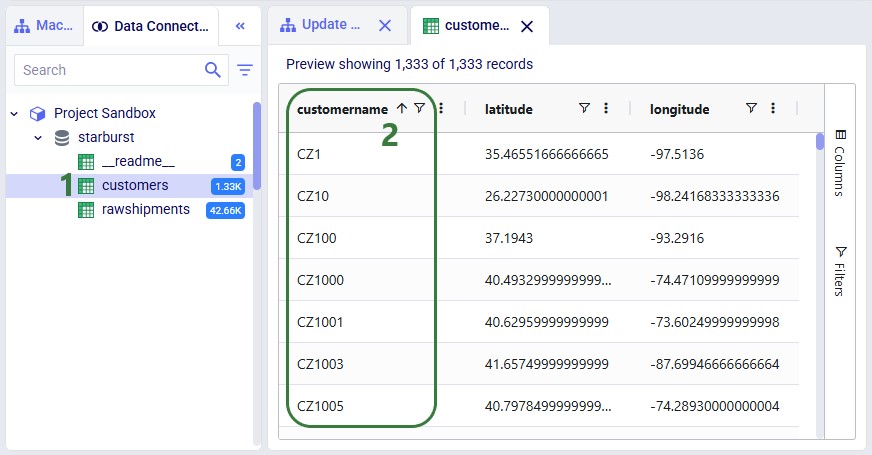
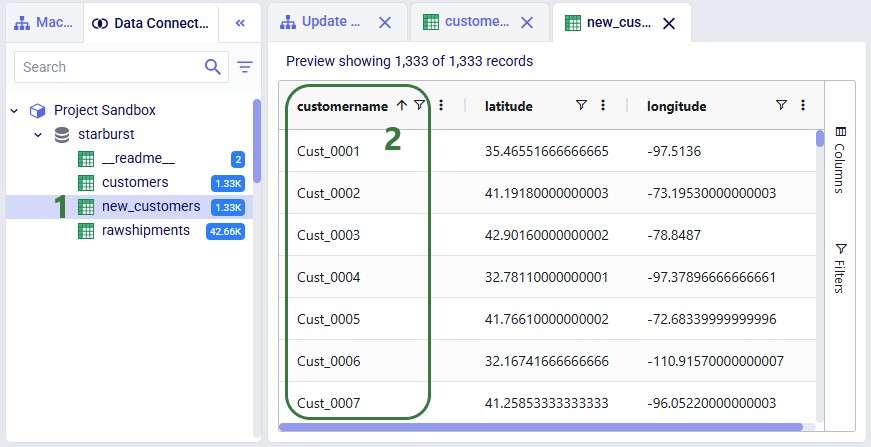
Before running the task, we examine the customers table in the sandbox:
Now run the "Change customer names" task (hover over it on the macro canvas and click the play button) and examine the results:
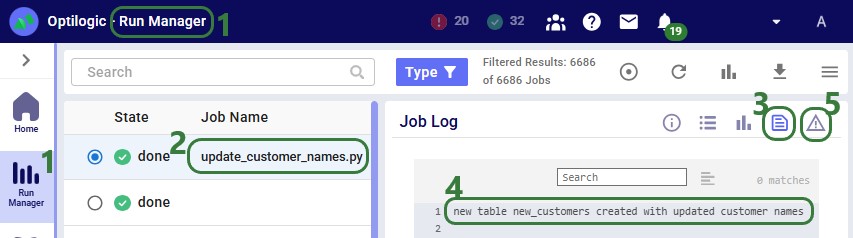
The Run Manager logs are useful for monitoring progress and troubleshooting:
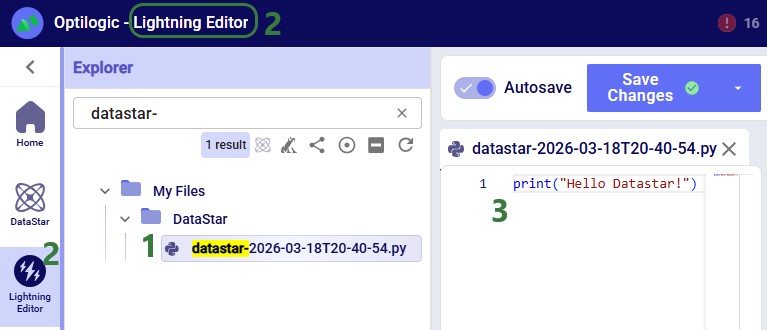
Instead of using an existing file, users can click the Create File button in the Code File area (see bullet 10 underneath the first screenshot of the Code File section) to create a new script directly on the Optilogic platform:
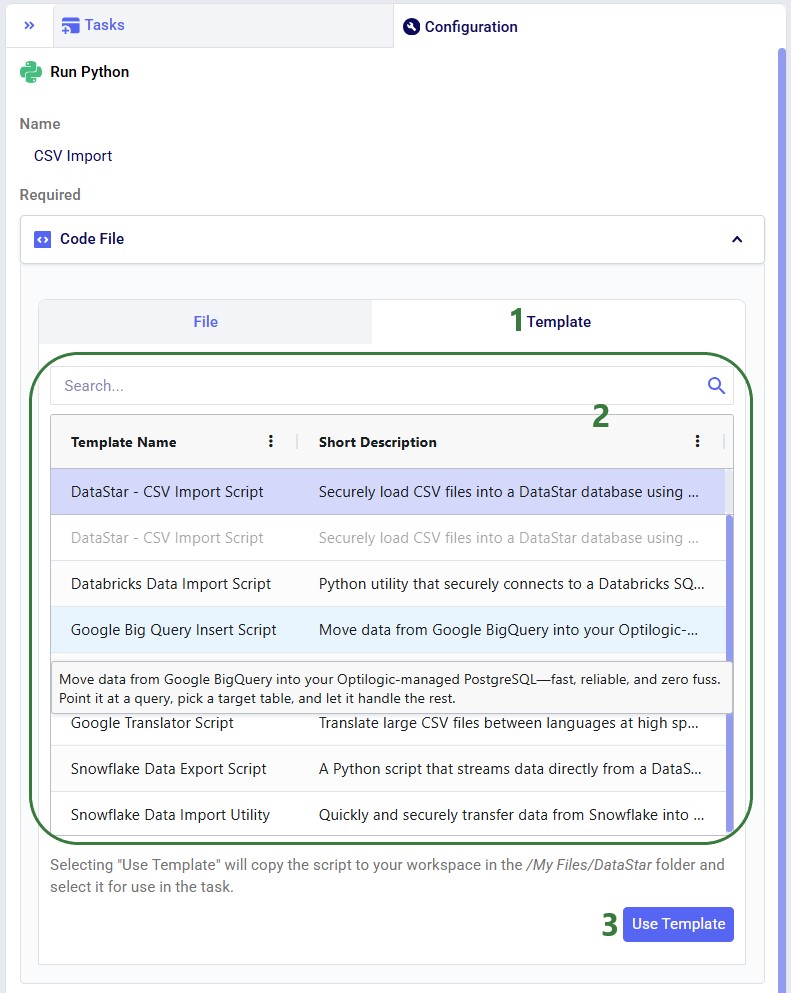
Templates are pre-built scripts available to all users from the Resource Library, covering common import/export patterns. To browse them, open the Resource Library application, filter for DataStar resources (button at the right top) and the Script tag. Clicking a resource also shows available documentation, which can be copied to your Optilogic account or downloaded.
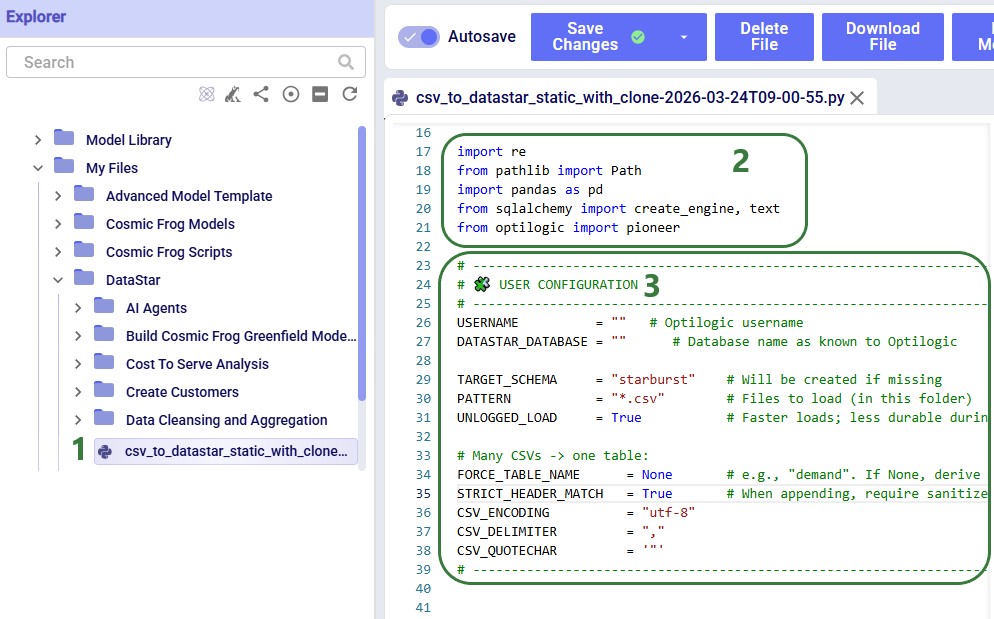
The Python base image used by the Run Python task contains the Python libraries most used in conjunction with DataStar. If your script uses a library that is not included in this base image, you need to create a requirements.txt file and place it in the same location as your Python script. In this file, you need to list the names of the libraries (without quotes), 1 library name per line.
If your script uses a library that is not part of the base image, the Job Error Log of the Python task run will contain the following error: "ModuleNotFoundError: No module named '<module name>'".
Keep the following in mind when developing scripts for Run Python tasks:
As always, our Support team is happy to help with any questions; they can be reached at support@optilogic.com.
Copy the script below into a .py file in your Optilogic account (via the Lightning Editor) and modify it as needed:
import argparse
from datastar import *
def main():
parser = argparse.ArgumentParser(description="Script to update names of customers using format of CZ1, CZ10, etc. \
to Cust_0001, Cust_0010, etc; copies the entire original table into a \
new table (new_<original table name>) with just the customer names updated.")
parser.add_argument("--project", required=True, help="Name of the DataStar project")
parser.add_argument("--original_table", required=True, help="Original table with the customer name field to be updated")
parser.add_argument("--column_name", required=True, help="Name of the field containing the name of the customer")
args = parser.parse_args()
project = Project.connect_to(args.project)
sandbox = project.get_sandbox()
df_table = sandbox.read_table(args.original_table)
df_new_table = df_table
df_new_table[args.column_name] = df_new_table[args.column_name].map(lambda x: x.lstrip('CZ'))
df_new_table[args.column_name] = df_new_table[args.column_name].str.zfill(4)
df_new_table[args.column_name] = 'Cust_' + df_new_table[args.column_name]
sandbox.write_table(df_new_table, "new_" + args.original_table)
print(f"new table new_{args.original_table} created with updated customer names")
if __name__ == "__main__":
main()
The following link provides a downloadable (excel) template describing the fields included in the output tables for Neo (Optimization), Throg (Simulation), Triad (Greenfield), and Hopper (Routing).
Anura 2.8 is the current schema.
A downloadable template describing the fields in the input tables can be downloaded from the Downloadable Anura Data Structure - Inputs Help Center article.
The best way to understand modeling in Cosmic Frog is to understand the data model and structure. The following link provides a downloadable (Excel) template with the documentation and explanation for every input table and field in the modeling schema.
A downloadable template describing the fields in the output tables can be downloaded from the Downloadable Anura Data Structure - Outputs Help Center article.
For a brief review of how to use the template file, please watch the following video.
If you are seeing a "Something went wrong" error when trying to open a model in Cosmic Frog — for example, Cannot read properties of undefined (reading 'call') — this is likely caused by a cached version of the application conflicting with a recent platform update. Follow the steps below in order to resolve it.
A hard refresh forces the browser to bypass its cache and reload all files directly from the server. It clears the cache for that specific page only and ensures the latest version is loaded. This is the quickest fix for pages that have not updated properly and should be tried first.
Press the following keyboard shortcut to perform a hard refresh:
Once the page has reloaded, try opening your model again.
If the hard refresh does not resolve the issue, clearing your full browser cache will remove all stored files and force the browser to fetch the latest version of Cosmic Frog from the server.
Press the following keyboard shortcut to open the Clear Browsing Data menu:
In the menu that appears:
Once cleared, refresh the Cosmic Frog page and try opening your model again.
If neither step resolves the problem, please contact the Optilogic support team. Include your browser type and version, and a screenshot of the error if possible.
Email: support@optilogic.com
In this quick start guide we will walk-through importing a CSV file into the Project Sandbox of a DataStar project. The steps involved are:
Our example CSV file is one that contains historical shipments from May 2024 through August 2025. There are 42,656 records in this Shipments.csv file, and if you want to follow along with the steps below you can download a zip-file containing it here (please note that the long character string at the beginning of the zip's file name is expected).
Open the DataStar application on the Optilogic platform and click on the Create Data Connection button in the toolbar at the top:
In the Create Data Connection form that comes up, enter the name for the data connection, optionally add a description, and select CSV Files from the Connection Type drop-down list:
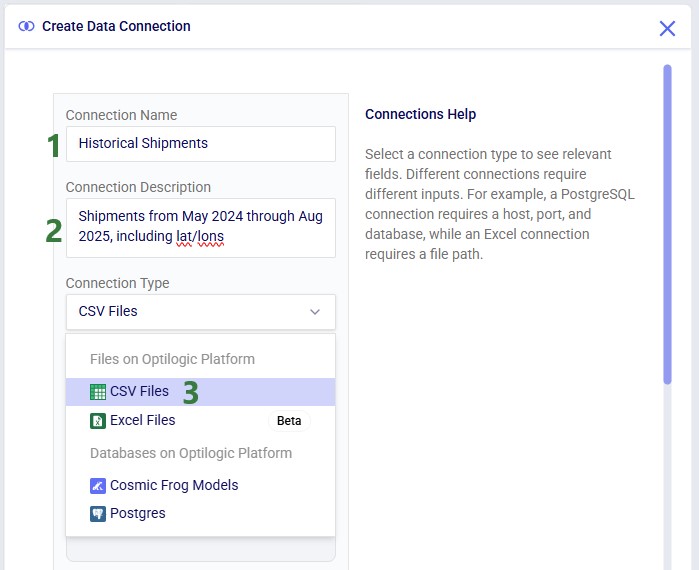
If your CSV file is not yet on the Optilogic platform, you can drag and drop it onto the “Drag and drop” area of the form to upload it to the /My Files/DataStar folder. If it is already on the Optilogic platform or after uploading it through the drag and drop option, you can select it in the list of CSV files. Once selected it becomes greyed out in the list to indicate it is the file being used; it is also pinned at the top of the list with darker background shade so users know without scrolling which file is selected. Note that you can filter this list by typing in the Search box to quickly find the desired file. Once the file is selected, users can optionally configure additional settings available on the right-hand side of the form, see the CSV File Data Connection help center article for details on these configuration options. Finally, clicking on the Add Connection button will create the CSV connection:
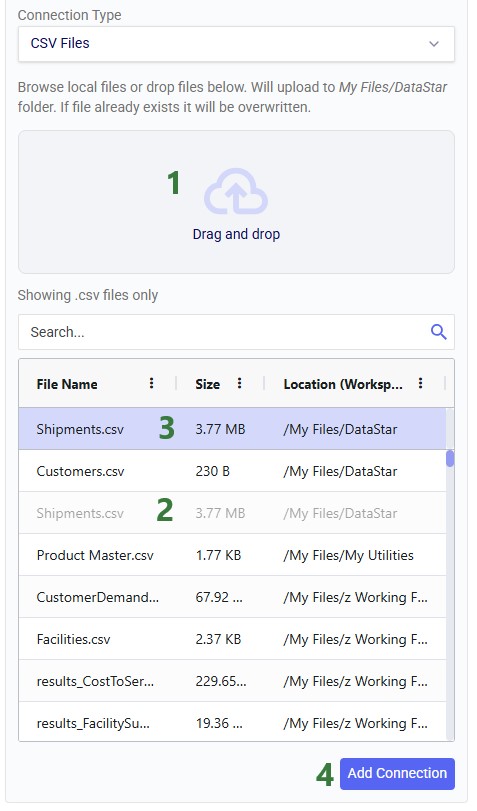
After creating the connection, the Data Connections tab on the DataStar start page will be active, and it shows the newly added CSV connection at the top of the list (note the connections list is shown in list view here; the other option is card view):
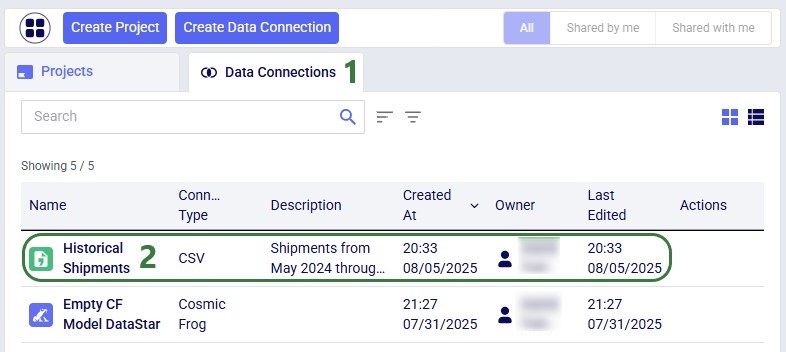
You can either go into an existing DataStar project or create a new one to set up a Macro that will import the data from the Historical Shipments CSV connection we just set up. For this example, we create a new project by clicking on the Create Project button in the toolbar at the top when on the start page of DataStar. Enter the name for the project, optionally add a description, change the appearance of the project if desired by clicking on the Edit button, and then click on the Add Project button:
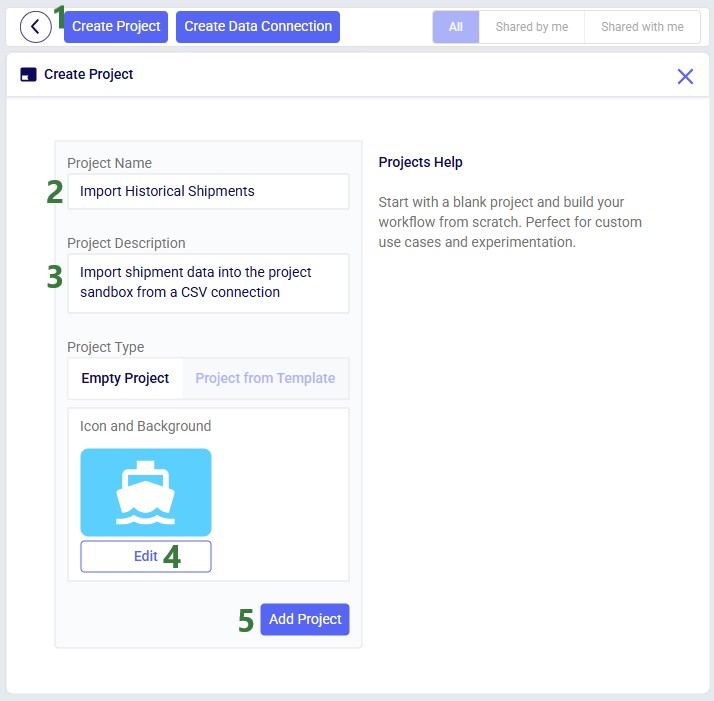
After the project is created, the Projects tab will be shown on the DataStar start page. Click on the newly created project to open it in DataStar. Inside DataStar, you can either click on the Create Macro button in the toolbar at the top or the Create a Macro button in the center part of the application (the Macro Canvas) to create a new macro which will then be listed in the Macros tab in the left-hand side panel. Type the name for the macro into the textbox:
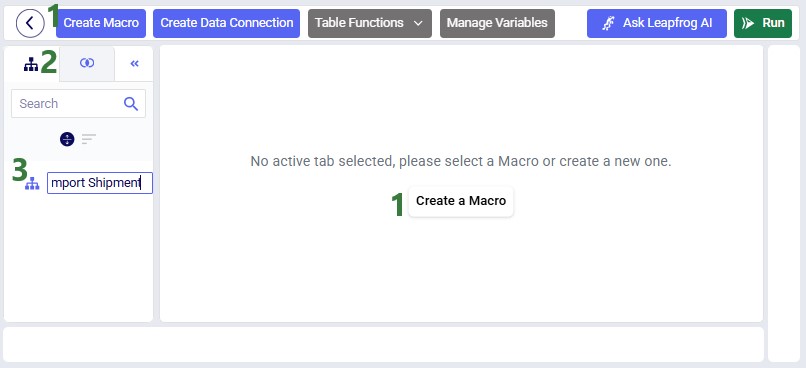
When a macro is created, it automatically gets a Start task added to it. Next, we open the Tasks tab by clicking on tab on the left in the panel on the right-hand side of the macro canvas. Click on Import and drag it onto the macro canvas:

When hovering close to the Start task, it will be suggested to connect the new Import task to the Start task. Dropping the Import task here will create the connecting line between the 2 tasks automatically. Once the Import task is placed on the macro canvas, the Configuration tab in the right-hand side panel will be opened. Here users can enter the name for the task, select the data connection that is the source for the import (the Historical Shipments CSV connection), and the data connection that is the destination of the import (a new table named “rawshipments” in the Project Sandbox):
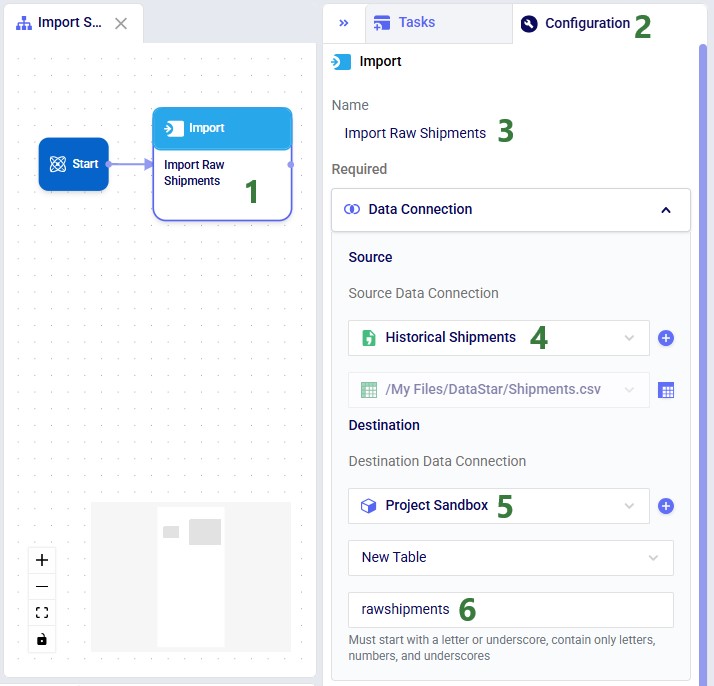
If not yet connected automatically in the previous step, connect the Import Raw Shipments task to the Start task by clicking on the connection point in the middle of the right edge of the Start task, holding the mouse down and dragging the connection line to the connection point in the middle of the left edge of the Import Raw Shipments task. Next, we can test the macro that has been set up so far by running it: either click on the green Run button in the toolbar at the top of DataStar or click on the Run button in the Logs tab at the bottom of the macro canvas:
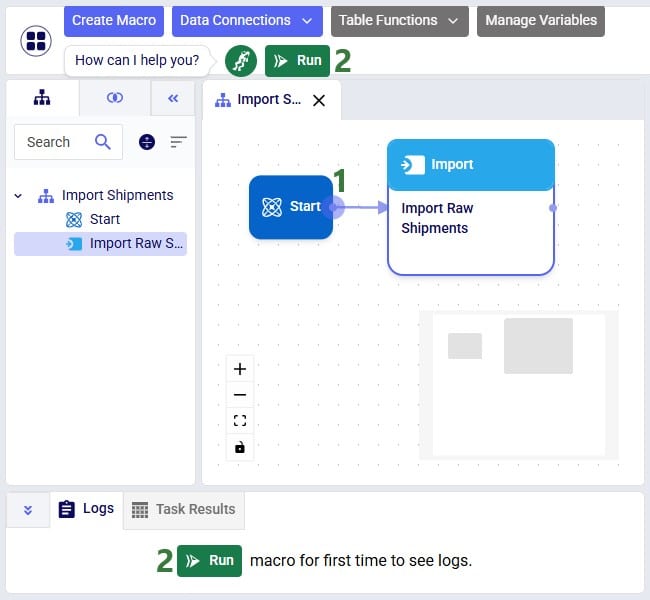
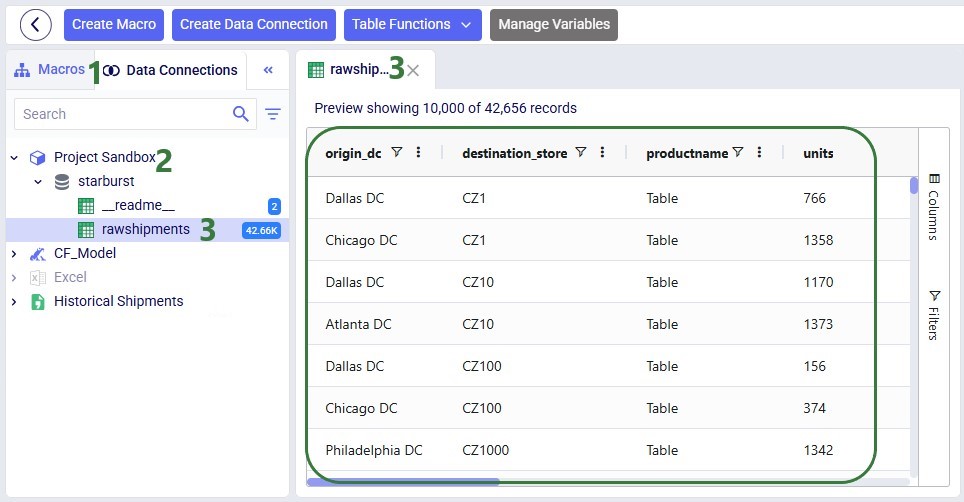
You can follow the progress of the Macro run in the Logs tab and once finished examine the results on the Data Connections tab. Expand the Project Sandbox data connection to open the rawshipments table by clicking on it. A preview of the table of up to 10,000 records will be displayed in the central part of DataStar:
Please watch this 5-minute video for an overview of DataStar, Optilogic’s new AI-powered data application designed to help supply chain teams build and update models & scenarios and power apps faster & easier than ever before!
For detailed DataStar documentation, please see Navigating DataStar on the Help Center.
This documentation covers how to create and configure DataStar CSV File data connections.
After opening DataStar, you can use the Create Data Connection button to add new data connections which can be used by all your DataStar projects:
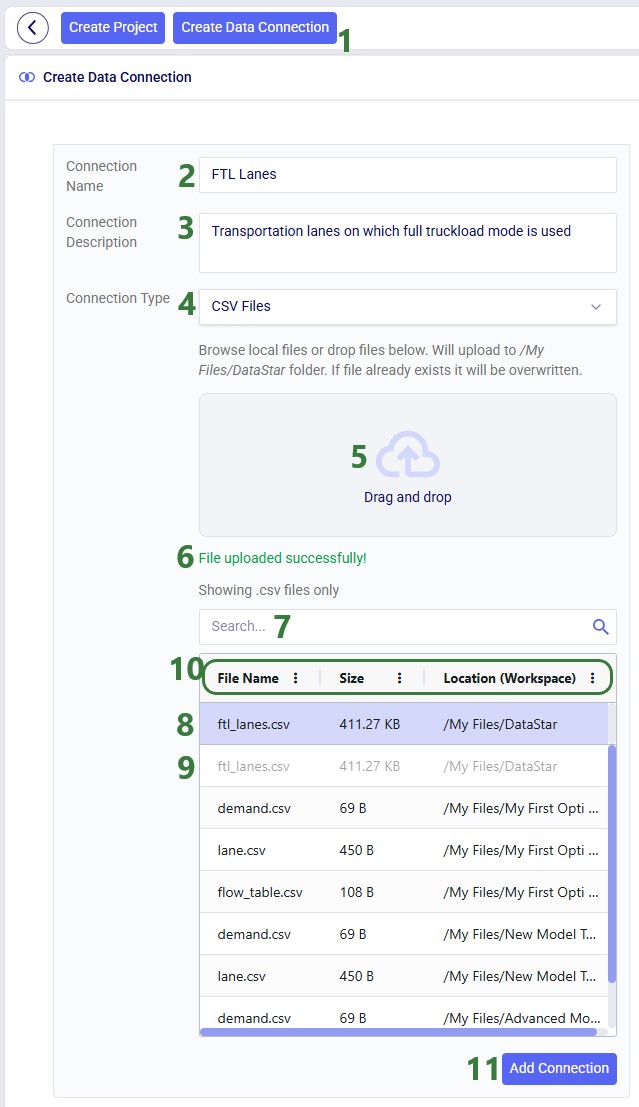
On the right-hand side of the Create Data Connection form, configuration options for the creation of the CSV File data connection are available. These will be covered now using the following screenshots.
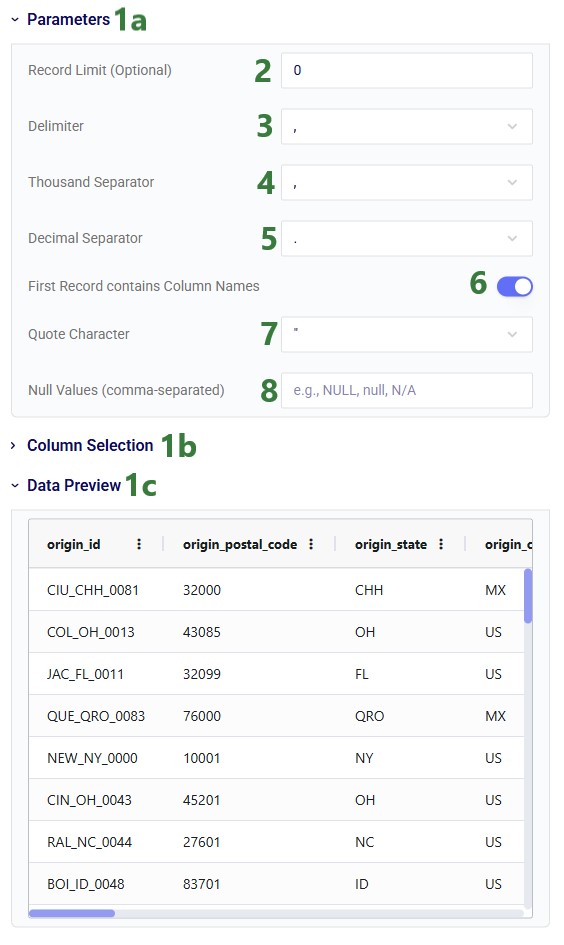
Note that when making any changes in these parameters the Data Preview below is immediately updated to take those changes into account. This is helpful to ensure that the parameters are set correctly.
Next, we will look at the Column Selection area, which was collapsed (the default) in the previous screenshot, but is expanded in the next one:
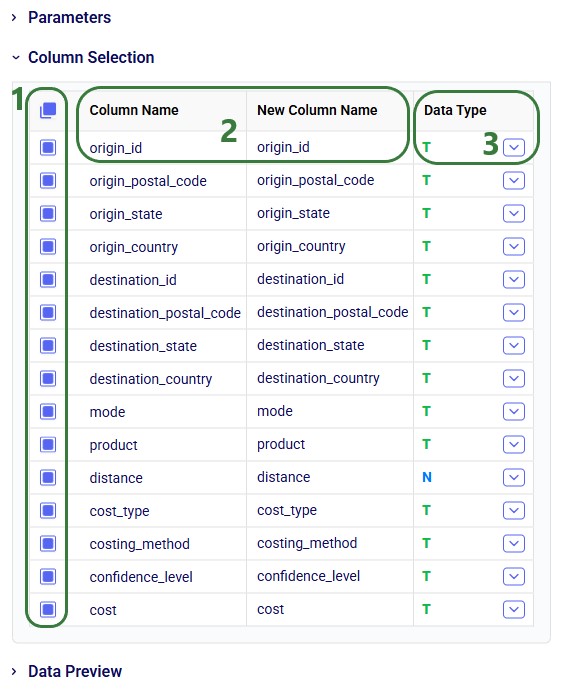
The drop-down list that comes up when clicking on the caret icon in a data type field is shown in this screenshot:

Just as with the Parameters section, making changes in this Column Selection section updates the Data Preview automatically.
Finally, the Data Preview section shows a preview of the data as it is currently configured based on the Parameters and Column Selection sections:
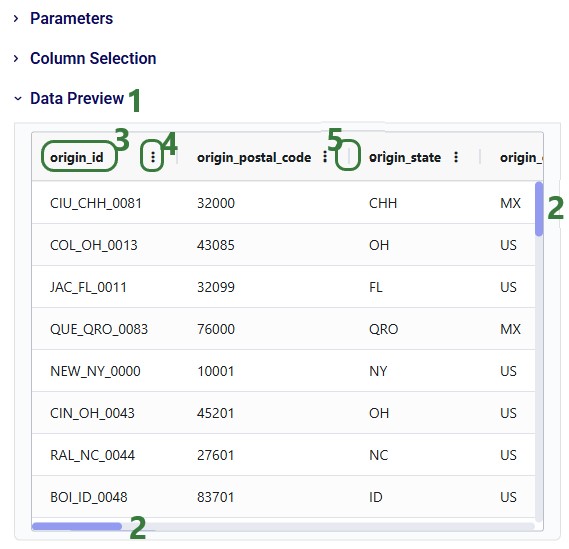
Once the configuration of the data connection is finalized, click on the blue Add Connection button, shown in the first screenshot above, to create the CSV data connection.
Learn all about DataStar from the Navigating DataStar section on Optilogic's Help Center.
We are excited to announce the upcoming release of Anura schema version 2.8.19, with enhancements to our engines and model run options. The migration rollout will start soon and is expected to be completed by the end of March.
All updates in this release are additive — there are no breaking changes.
Neo
Hopper
Other
Model Run Options
MaxNumberOfSourcesToConsiderForMultiStopRoutes DendroTimeoutCYCLO - Multi-Echelon Inventory Optimization
CompartmentConfigurationsInventorySettingsUtilityCurvesInventoryNetworkSummaryInventorySafetyStockSummaryInventoryValidationErrorReportTransportationAssets.CompartmentConfigurationNameTransportationPolicies.MaximumServiceTimeTransportationPolicies.MaximumServiceTimeUOMTransportationPolicies.MinimumServiceTimeTransportationPolicies.MinimumServiceTimeUOMOptimizationProcessSummary.DisposalBehaviorTransportationShipmentSummary.CompartmentNameIf you have any questions or concerns about this upcoming Anura upgrade, please reach out to Optilogic Support at support@optilogic.com.
When a scenario run is infeasible, it means that the solver cannot find any solutions that satisfy all the specified constraints simultaneously. In other words, the defined constraints are too restrictive or they contradict each other, making it impossible to satisfy all of them at once. Examples are:
If a Neo (network optimization) scenario run is infeasible, a user can tell from within Cosmic Frog and also by looking at the run's logs in the Run Manager application. Within Cosmic Frog, the Optimization Network Summary output table will show Solve Status = Infeasible and many other output columns, such as Solve Type and Solve Time, will be blank:
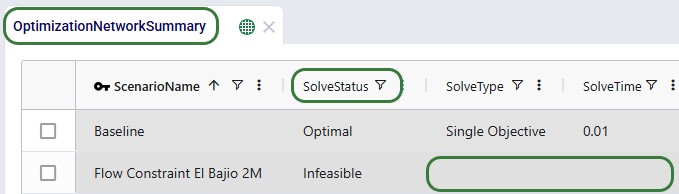
In the Run Manager application, also on the Optilogic Platform, users can select the scenario run, which will have Status = Error, and look at the run's logs on the right-hand side:
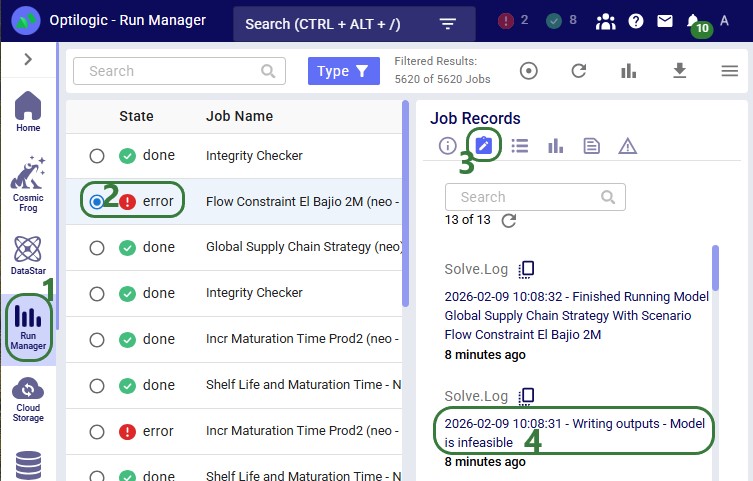
Running the check infeasibility tool is a great first step in identifying why a scenario is infeasible. It can allow the scenario to optimize even if the current constraints cause infeasibility. Generally, the tool will loosen constraints in the scenario, which allow it to solve. This means that the check infeasibility tool is solving an optimization problem focused on feasibility, not cost. The goal of this augmented model is to minimize how much the constraints are loosened, and therefore the tool can often find:
The Check Infeasibility tool is accessed via the model run options on the Run Settings screen:
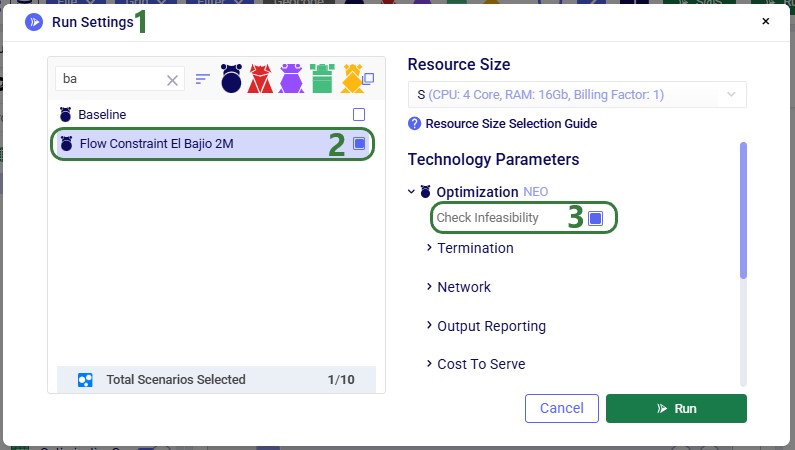
When running the Check Infeasibility tool in this default manner, all constraints will be relaxed. Additional run parameters can be used to selectively choose which constraints can be relaxed during a Check Infeasibility run and which need to be enforced, see the "Infeasibility Parameters" section in the "Running Models & Scenarios" help center article. Especially in models where many different types of constraints are applied, this can help in determining which constraint(s) cause the infeasibility and how constraints interact with each other. An approach can be to run the Check Infeasibility tool a few times with different constraints enforced and then compare the results. It also lets users indicate to the solver which constraints are most important to satisfy by keeping those enforced, while others are allowed to be relaxed.
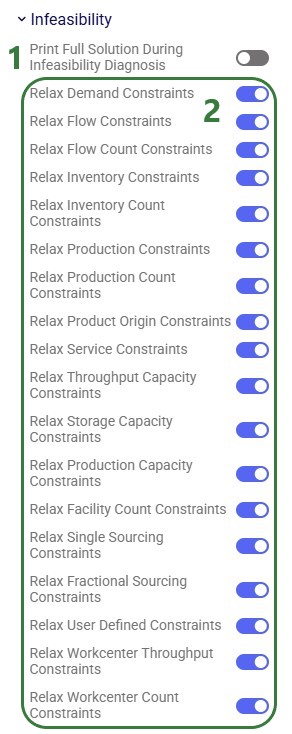
Once a Check Infeasibility run completes successfully, the results that are likely most helpful for identifying the infeasibility are found in the Optimization Constraint Summary output table. Users may need to filter for the scenario name in case this table contains results of multiple check infeasibility scenario runs. The following 2 screenshots show the 1 record in this table for the scenario called "Flow Constraint El Bajio 2M" scenario that returns infeasible as shown above. This first screenshot shows that the constraint in question is a Flow constraint that is applied on the lanes from the El Bajio Factory to a group of DCs named DCs Con:
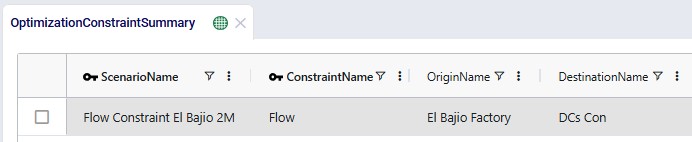
Scrolling right in the table, we can see additional fields which indicate why this constraint leads to infeasibility in the scenario:

In this example, the check infeasibility tool can pinpoint the infeasibility exactly. At other times, the outcomes will be more general, see for example the following screenshots of results of a check infeasibility run on a different scenario:


Here the constraint that cannot be fulfilled is the demand for 1,000 units of Product_2 in Period_6. The output in the Constraint Summary output table is telling us that a way to make this feasible is to change the demand quantity to be 0. We will need to investigate the model inputs further to understand why this is. On further inspection, the infeasibility cause is found to be that the maturation time of Product_2 is set to 50 days. This is longer than the model horizon of 42 days (6 weekly periods). So, if no or not enough initial inventory is present in the model, Product_ 2 cannot be made and mature in time to fulfill demand in Period_ 6.
If the user has turned on the "Print Full Solution During Infeasibility Diagnosis" option, see above, the outputs in the other output tables can possibly also help to determine the cause of the infeasibility.
When a Cosmic Frog model has been built and scenarios of interest have been created, it is usually time to run 1 or multiple scenarios. This documentation covers how scenarios can be kicked off, and which run parameters can be configured by users.
When ready to run scenarios, users can click on the green Run button at the right top of the Cosmic Frog screen:
This will bring up the Run Settings screen:
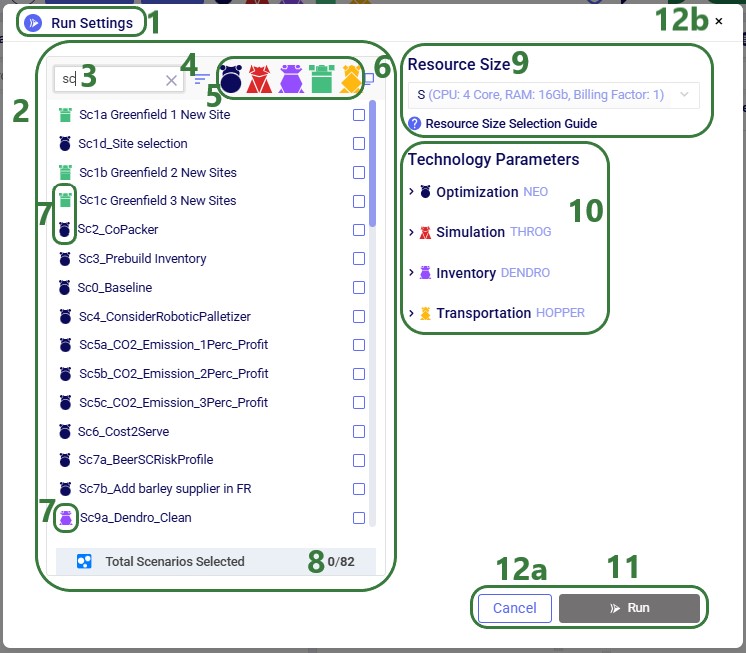
Please note that:
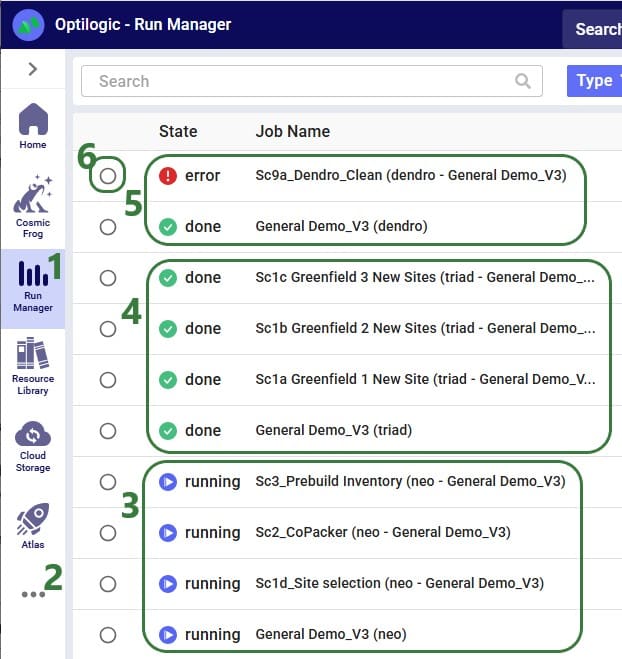
While we will discuss all parameters for each technology in the next sections of the documentation, please note that you can also find short explanations for each of them within Cosmic Frog: when hovering over a parameter, a tooltip explaining the parameter will be shown. In the next screenshot, the user has expanded the Termination section within the Optimization (Neo) technology parameters section and is hovering with the mouse over the "MIP Relative Gap Percentage" parameter, which brings up the tooltip explaining this parameter:
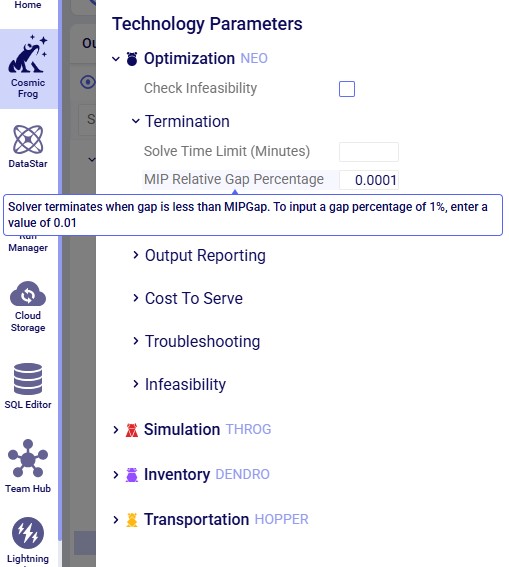
When selecting one or multiple scenarios to be run with the same engine, the corresponding technology parameters are automatically expanded in the Technology Parameters part of the Run Settings screen:
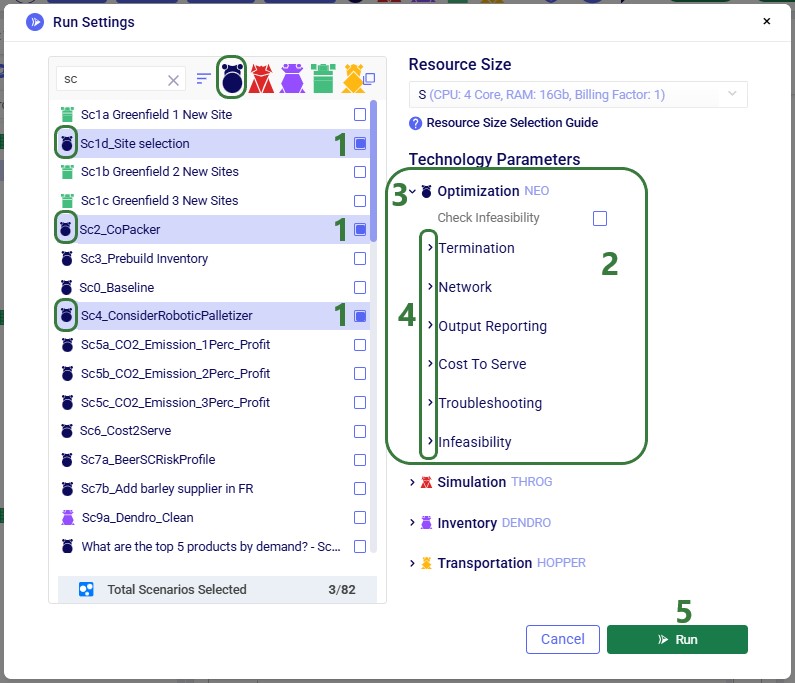

When enabled, the Check Infeasibility tool will run an infeasibility diagnostic on the model in order to identify any cause(s) of the scenario being infeasible rather than optimizing the scenario for minimal cost. For more information on using the check infeasibility tool, please see this Help Center article.
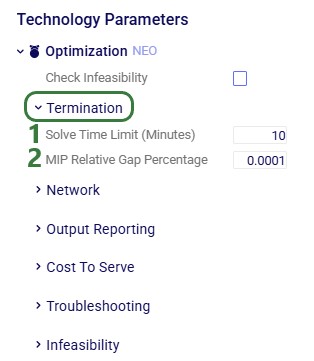
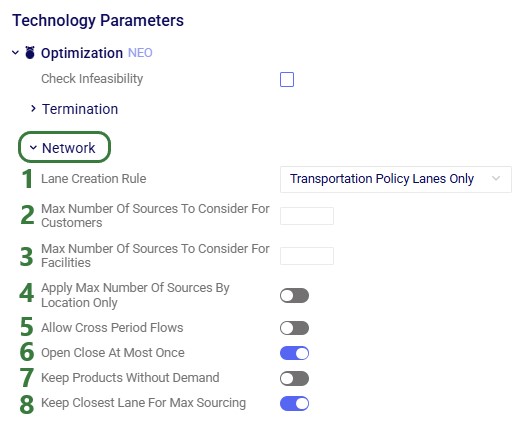
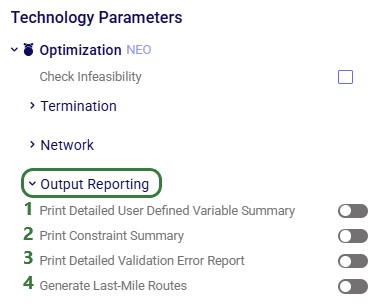
For more details on the Cost To Serve output tables that are populated by turning the options discussed below on, please see this "Cost to Serve Outputs (Optimization)" Help Center article.
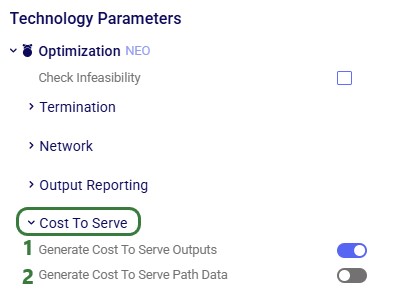

The following screenshot shows where the NEO.lp file can be found when running a scenario with the Write LP File parameter (bullet 2 under the above screenshot) turned on:
As more types of constraints are added to the Neo engine on an ongoing basis, not all may be captured by one of the above "Relax … Constraints" buckets. Any such constraints, like for example shelf life, are always relaxed when running the Infeasibility Check and, if they are the cause of infeasibility, reported in the Optimization Constraint Summary output table.
The following screenshot shows part of a Job Log of a simulation run, see also bullet 3 above:
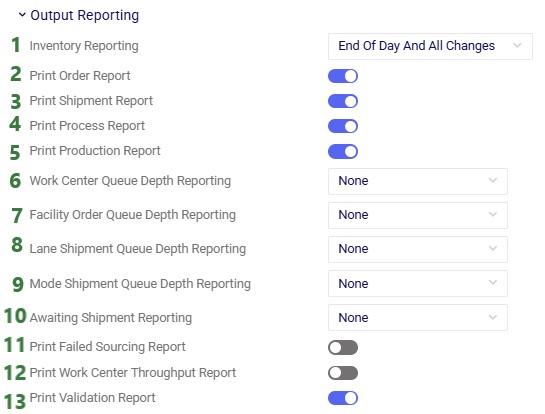
The inventory engine in Cosmic Frog (called Dendro) uses a genetic algorithm to evaluate possible solutions in a successive manner. The parameters that can be set dictate how deep the search space is and how solutions can evolve from one generation to the next. Using the parameter defaults will suffice for most inventory problems, they are however available to change as needed for experienced users.
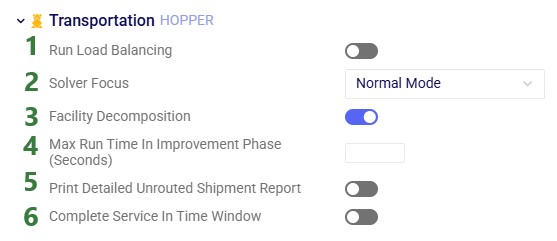
As always, please feel free to contact Optilogic Support at support@optilogic.com in case of questions or feedback.
DataStar users typically will want to use data from a variety of sources in their projects. This data can be in different locations and systems and there are multiple methods available to get the required data into the DataStar application. In this documentation we will describe the main categories of data sources users may want to use and the possible ways of making these available in DataStar for usage.
If you would first like to learn more about DataStar before diving into data integration specifics, please see the Navigation DataStar articles on the Optilogic Help Center.
The following diagram shows different data sources and the data transfer pathways to make them available for use in DataStar:

We will dive a bit deeper into making local data available for use in DataStar building upon what was covered under bullets 5a-5c in the previous screenshot. First, we will familiarize ourselves with the layout of the Optilogic platform:
Next, we will cover the 3 steps to go from data sitting on a user’s computer locally to being able to use it in DataStar in detail through the next set of screenshots. At a high-level the steps are:
To get local data onto the Opitlogic platform, we can use the file / folder upload option:
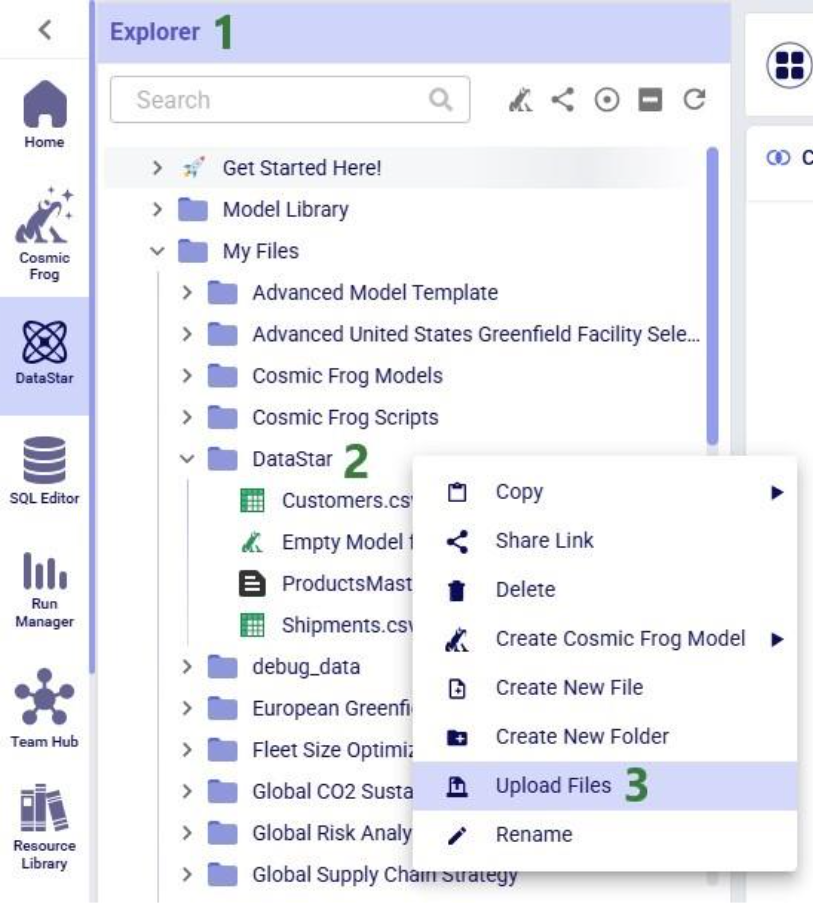

Select either the file(s) or folder you want to upload by browsing to it/them. After clicking on Open, the File Upload form will be shown again:
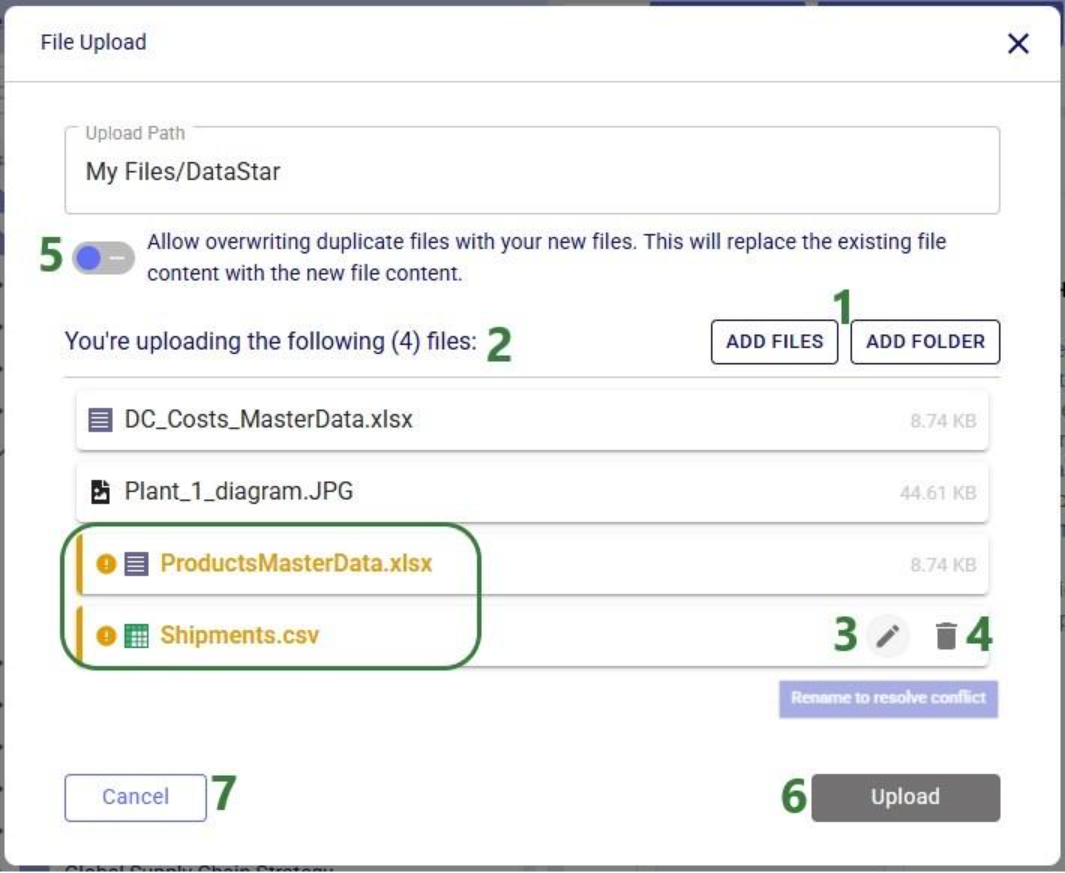
Note that files in the upload list that will not cause name conflicts can also be renamed or removed from the list if so desired. This can for example be convenient when wanting to upload most files in a folder, except for a select few. In that case use the Add Folder option and in the list that will be shown, remove the few that should not be uploaded rather than using Add Files and then manually selecting almost all files in a folder.
Once the files are uploaded, you will be able to see them in the Explorer by expanding the folder they were uploaded to or searching for (part of) their name using the Search box.
The second step is to then make these files visible to DataStar by setting up Data Connections to them:
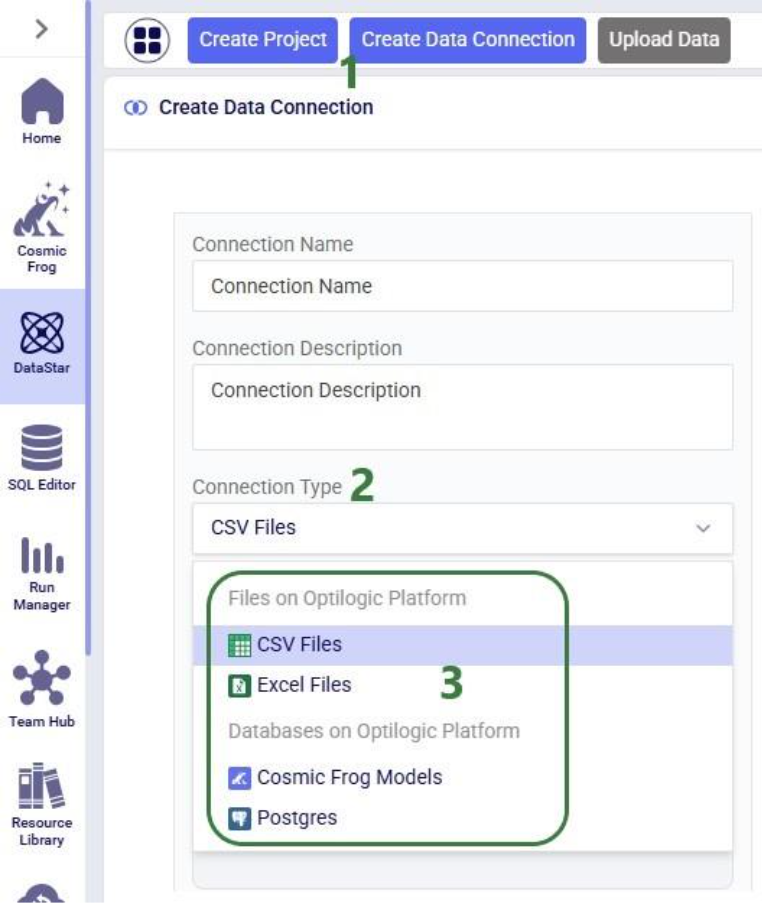
After setting up a Data Connection to a Cosmic Frog model and to a CSV file, we can see the source files in the Explorer, and the Data Connections pointing to these in DataStar side-by-side:
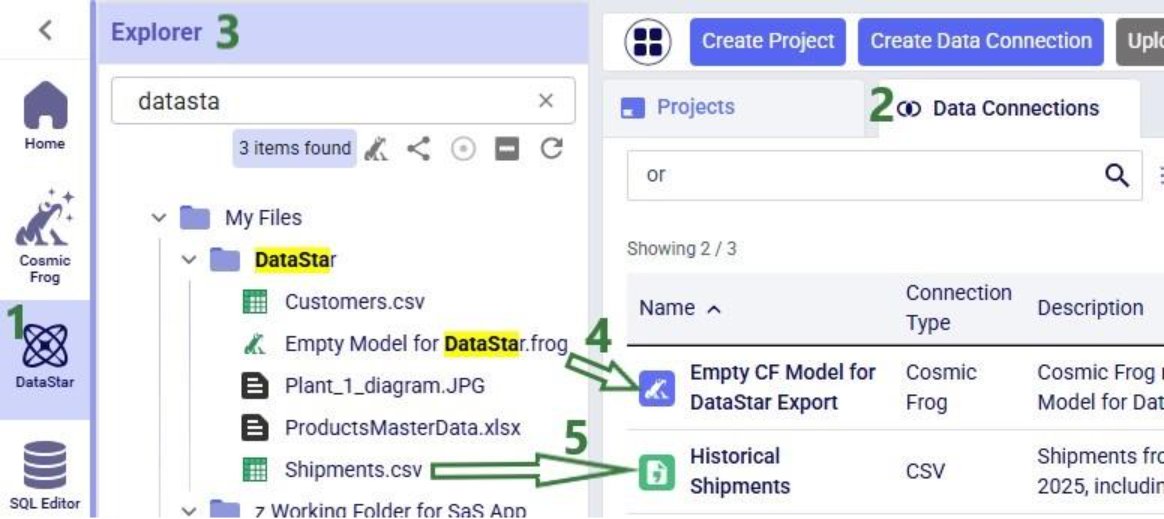
To start using the data in DataStar, we need to take the third step of importing the data from the data connections into a project. Typically, the data will be imported into the Project Sandbox, but this could also be into another Postgres database, including a Cosmic Frog model. Importing data is done using Import tasks; the Configuration tab of one is shown in this next screenshot:
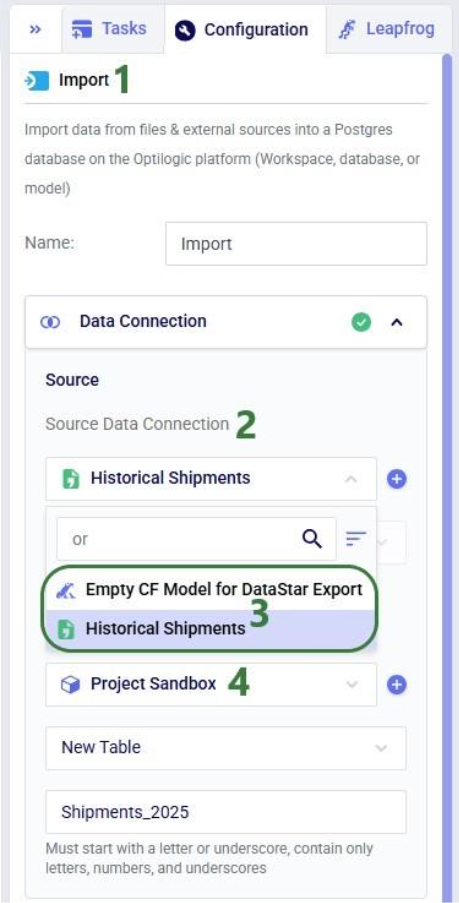
The 3 steps described above are summarized in the following sequence of screenshots:
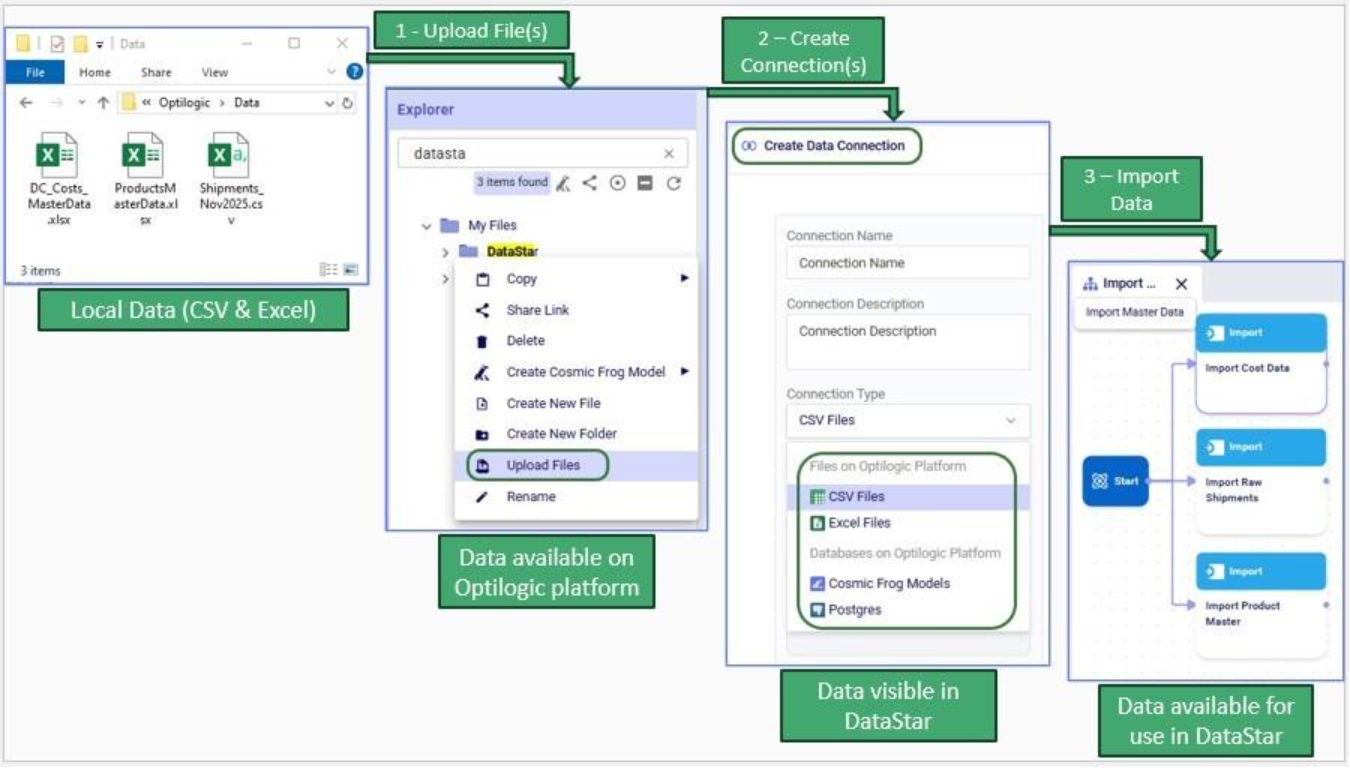
For a data workflow that is used repeatedly and needs to be re-run using the latest data regularly, users do not need to go through all 3 steps above of uploading data, creating/re-configuring data connections, and creating/re-configuring Import tasks to refresh local data. If the new files to be used have the same name and same data structure as the current ones, replacing the files on the Optilogic platform with the newer ones will suffice (so only step 1 is needed); the data connections and Import tasks do not need to be updated or re-configured. Users can do this manually or programmatically:
This section describes how to bring external data into DataStar using supported integration patterns where the data transfer is started from an external system, e.g. the data is “pushed” onto the Optilogic platform.
External systems such as ETL tools, automation platforms, or custom scripts can load data into DataStar through the Optilogic Pioneer API (please see the Optilogic REST API documentation for details). This approach is ideal when you want to programmatically upload files, refresh datasets, or orchestrate transformations without connecting directly to the underlying database.
Key points:
Please note that Optilogic has developed a Python library to facilitate scripting for DataStar. If your external system is Python based, you can leverage this library as a wrapper for the API. For more details on working with the library and a code example of accessing a DataStar project’s sandbox, see this “Using the DataStar Python Library” help center article.
Every DataStar project is backed by a PostgreSQL database. You can connect directly to this database using any PostgreSQL-compatible driver, including:
This enables you to write or update data using SQL, query the sandbox tables, or automate recurring loads. The same approach applies to both DataStar projects and Cosmic Frog models since both use PostgreSQL under the hood. Please see this help center article on how to retrieve connection strings for Cosmic Frog model and DataStar project databases; these will need to be passed into the database connection to gain access to the model / project database.
Several scripts and utilities to connect to common external data sources, including Databricks, Google Big Query, Google Drive, and Snowflake, are available on Optilogic’s Resource Library:

These utilities and scripts can function as a starting point to modify into your own desired script for connecting to and retrieving data from a certain data source. You will need to update authentication and connection information in the scripts and configure the user settings to your needs. For example, this is the User Input section of the “Databricks Data Import Script”:
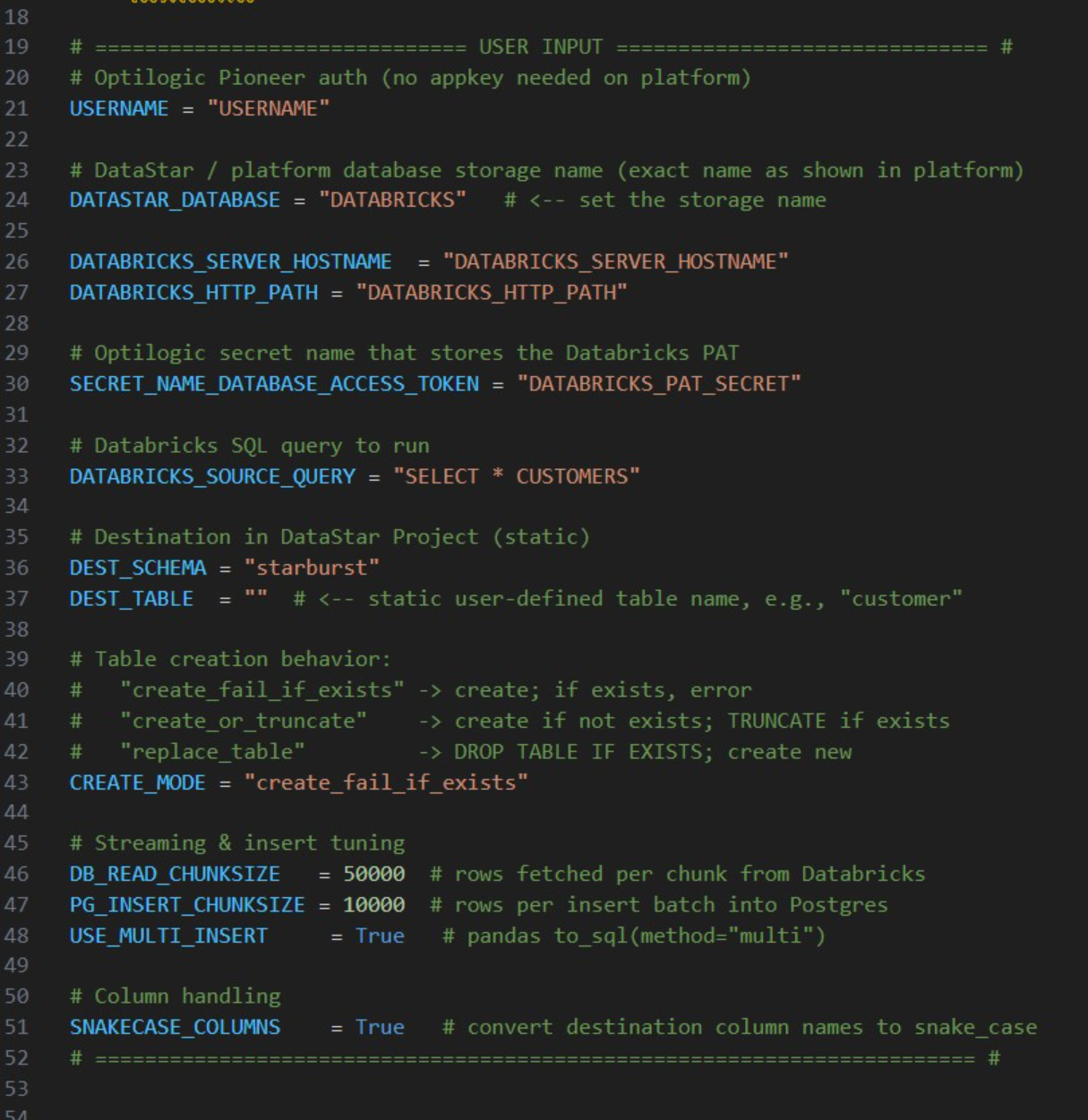
The user needs to update following lines; others can be left at defaults and only updated if desired/required:
For any questions or feedback, please feel free to reach out to the Optilogic support team on support@optilogic.com.
In this quick start guide we will show how Leapfrog AI can be used in DataStar to generate tasks from natural language prompts, no coding necessary!
This quick start guide builds upon the previous one where a CSV file was imported into the Project Sandbox, please follow the steps in there first if you want to follow along with the steps in this quick start. The starting point for this quick start is therefore a project named Import Historical Shipments that has a Historical Shipments data connection of type = CSV, and a table in the Project Sandbox named rawshipments, which contains 42,656 records.
The Shipments.csv file that was imported into the rawshipments table has following data structure (showing 5 of the 42,656 records):

Our goal in this quick start is to create a task using Leapfrog that will use this data (from the rawshipments table in the Project Sandbox) to create a list of unique customers, where the destination stores function as the customers. Ultimately, this list of customers will be used to populate the Customers input table of a Cosmic Frog model. A few things to consider when formulating the prompt are:
Within the Import Historical Shipments DataStar project, click on the Import Shipments macro to open it in the macro canvas, you should see the Start and Import Raw Shipments tasks on the canvas. Then open Leapfrog by clicking on the Ask Leapfrog AI button to the right in the toolbar at the top of DataStar. This will open the Leapfrog tab where a welcome message will be shown. Next, we can write our prompt in the “Write a message…” textbox.
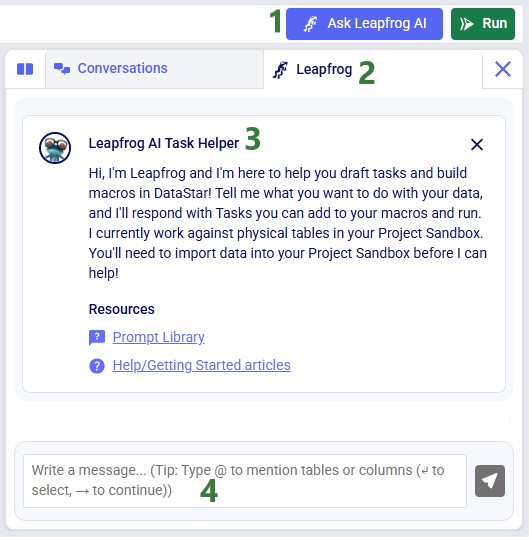
Keeping in mind the 5 items mentioned above, the prompt we use is the following: “Use the @rawshipments table to create unique customers (use the @rawshipments.destination_store column); average the latitudes and longitudes. Only use records with the @rawshipments.ship_date between July 1 2024 and June 30 2025. Match to the anura schema of the Customers table”. Please note that:
After clicking on the send icon to submit the prompt, Leapfrog will take a few seconds to consider the prompt and formulate a response. The response will look similar to the following screenshot, where we see from top to bottom:
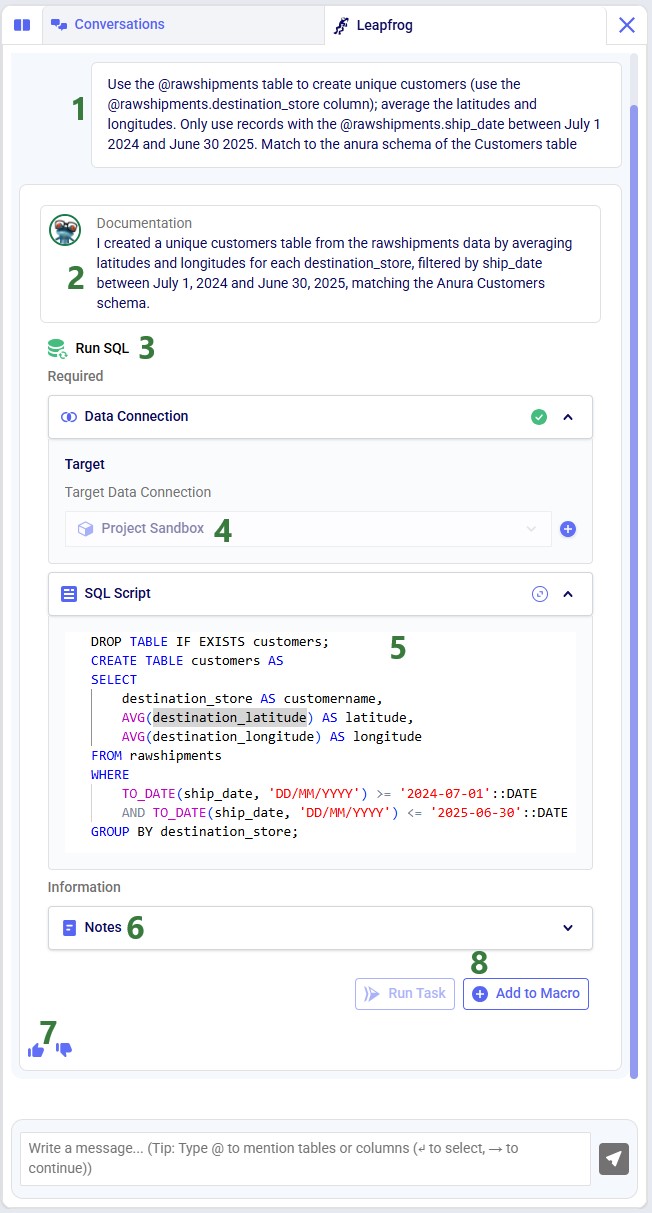
For copy-pasting purposes, the resulting SQL Script is repeated here:
DROP TABLE IF EXISTS customers;
CREATE TABLE customers AS
SELECT
destination_store AS customername,
AVG(destination_latitude) AS latitude,
AVG(destination_longitude) AS longitude
FROM rawshipments
WHERE
TO_DATE(ship_date, 'DD/MM/YYYY') >= '2024-07-01'::DATE
AND TO_DATE(ship_date, 'DD/MM/YYYY') <= '2025-06-30'::DATE
GROUP BY destination_store;
Those who are familiar with SQL, will be able to tell that this will indeed achieve our goal. Since that is the case, we can click on the Add to Macro button at the bottom of Leapfrog’s response to add this as a Run SQL task to our Import Shipments macro. When hovering over this button, you will see Leapfrog suggests where to put it on the macro canvas and to connect it to the Import Raw Shipments task, which is what we want. When next clicking on the Add to Macro button it will be added.
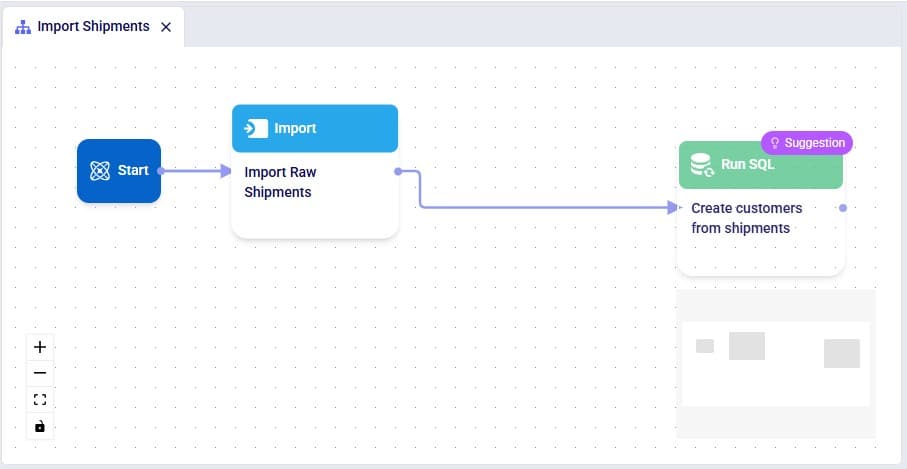
We can test our macro so far, by clicking on the green Run button at the right top of DataStar. Please note that:
Once the macro is done running, we can check the results. Go to the Data Connections tab, expand the Project Sandbox connection and click on the customers table to open it in the central part of DataStar:
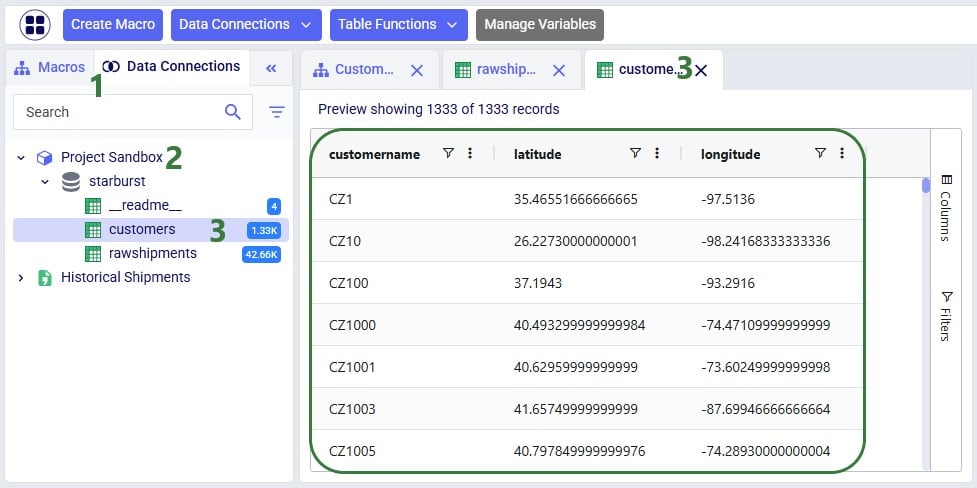
We see that the customers table resulting from running the Leapfrog-created Run SQL task contains 1,333 records. Also notice that its schema matches that of the Customers table of Cosmic Frog models, which includes columns named customername, latitude, and longitude.
Writing prompts for Leapfrog that will create successful responses (e.g. the SQL Script generated will achieve what the prompt-writer intended) may take a bit of practice. This Mastering Leapfrog for SQL Use Cases: How to write Prompts that get Results post on the Frogger Pond community portal has some great advice which applies to Leapfrog in DataStar too. It is highly recommended to give it a read; the main points of advice follow here too:
As an example, let us look at variations of the prompt we used in this quick start guide, to gauge the level of granularity needed for a successful response. In this table, the prompts are listed from least to most granular:
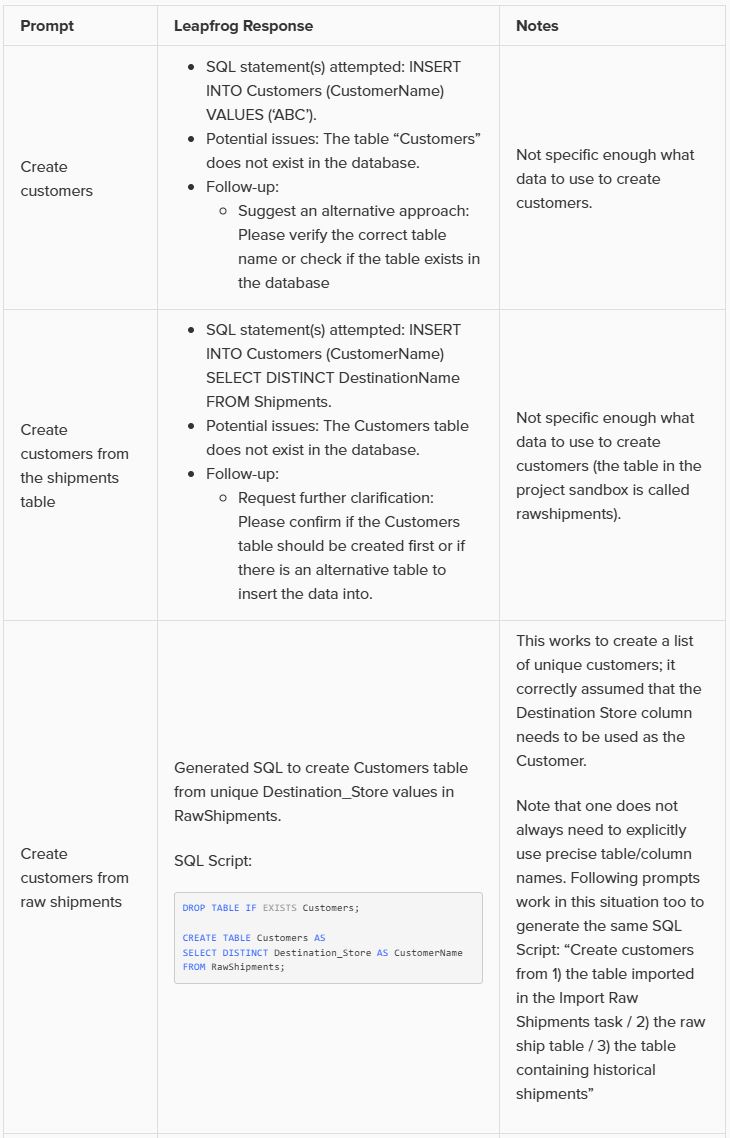
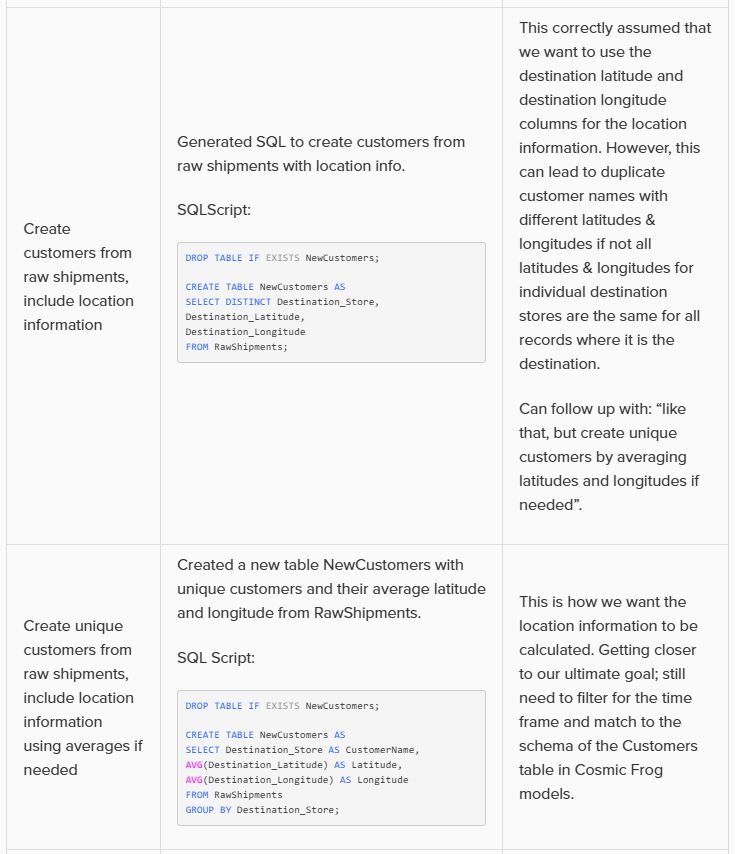

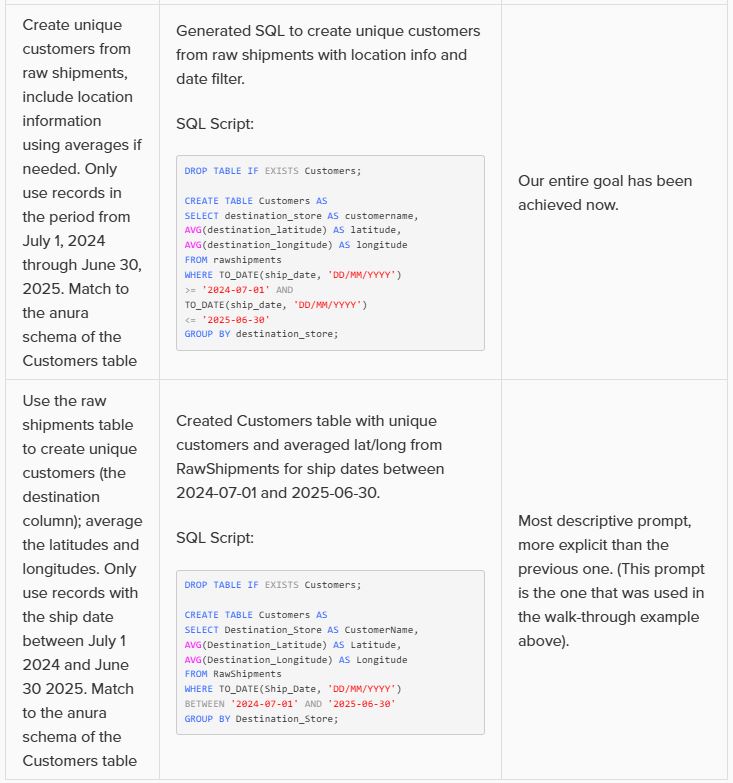
Note that in the above prompts, we are quite precise about table and column names and no typos are made by the prompt writer. However, Leapfrog can generally manage well with typos and often also pick up table and column names when not explicitly used in the prompt. So while generally being more explicit results in higher accuracy, it is not necessary to always be extremely explicit and we just recommend to be as explicit as you can be.
In addition, these example prompts do not use the @ character to specify tables and columns to use, but they could to facilitate prompt writing further.
In this quick start guide we will walk through the steps of exporting data from a table in the Project Sandbox to a table in a Cosmic Frog model.
This quick start guide builds upon a previous one where unique customers were created from historical shipments using a Leapfrog-generated Run SQL task. Please follow the steps in that quick start guide first if you want to follow along with the steps in this one. The starting point for this quick start is therefore a project named Import Historical Shipments, which contains a macro called Import Shipments. This macro has an Import task and a Run SQL task. The project has a Historical Shipments data connection of type = CSV, and the Project Sandbox contains 2 tables named rawshipments (42,656 records) and customers (1,333 records).
The steps we will walk through in this quick start guide are:
First, we will create a new Cosmic Frog model which does not have any data in it. We want to use this model to receive the data we export from the Project Sandbox.
As shown with the numbered steps in the screenshot below: while on the start page of Cosmic Frog, click on the Create Model button at the top of the screen. In the Create Frog Model form that comes up, type the model name, optionally add a description, and select the Empty Model option. Click on the Create Model button to complete the creation of the new model:
Next, we want to create a connection to the just created empty Cosmic Frog model in DataStar. To do so: open your DataStar application, then click on the Create Data Connection button at the top of the screen. In the Create Data Connection form that comes up, type the name of the connection (we are using the same name as the model, i.e. “Empty CF Model for DataStar Export”),optionally add a description, select Cosmic Frog Models in the Connection Type drop-down list, click on the name of the newly created empty model in the list of models, and click on Add Connection. The new data connection will now be shown in the list of connections on the Data Connections tab (shown in list format here):
Now, go to the Projects tab, and click on the “Import Historical Shipments” project to open it. We will first have a look at the Project Sandbox and the empty Cosmic Frog model connections, so click on the Data Connections tab:

The next step is to add and configure an Export Task to the Import Shipments macro. Click on the Macros tab in the panel on the left-hand side, and then on the Import Shipments macro to open it. Click on the Export task in the Tasks panel on the right-hand side and drag it onto the Macro Canvas. If you drag it close to the Run SQL task, it will automatically connect to it once you drop the Export task:
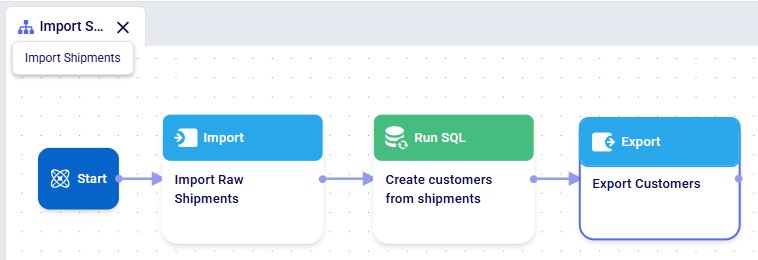
The Configuration panel on the right has now become the active panel:
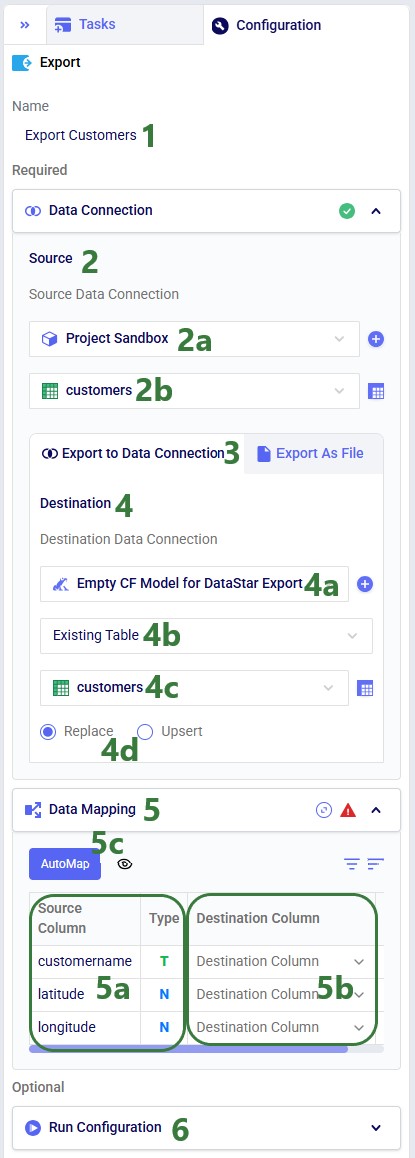
Click on the AutoMap button, and in the message that comes up, select either Replace Mappings or Add New Mappings. Since we have not mapped anything yet, the result will be the same in this case. After using the AutoMap option, the mapping looks as follows:

We see that each source column is now mapped to a destination column of the same name. This is what we expect, since in the previous quick start guide, we made sure to tell Leapfrog when generating the Run SQL task for creating unique customers to match the schema of the customers table in Cosmic Frog models (“the Anura schema”).
If the Import Shipments macro has been run previously, we can just run the new Export Customers task by itself (hover over the task in the Macro Canvas and click on the play button that comes up), otherwise we can choose to run the full macro by clicking on the green Run button at the right top. Once completed, click on the Data Connections tab to check the results:
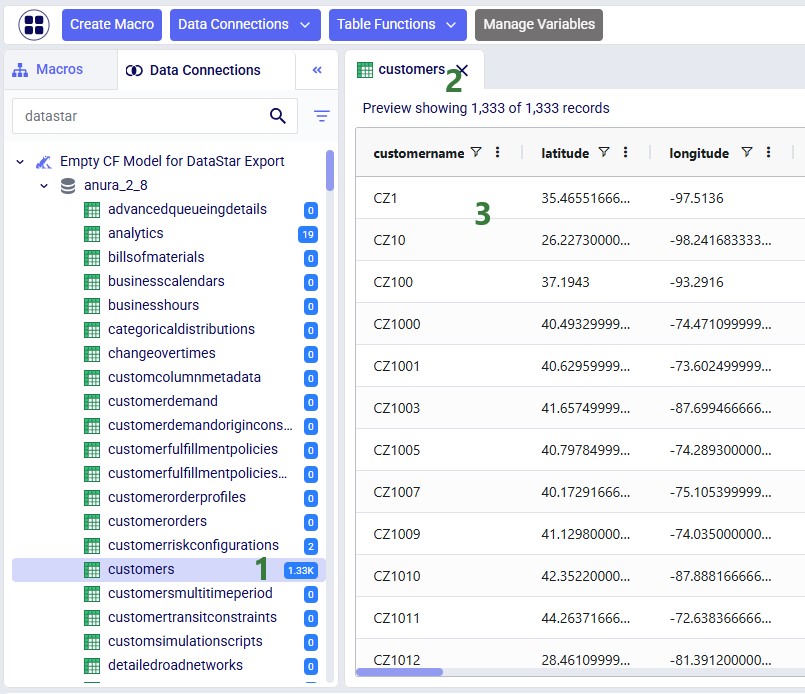
Above, the AutoMap functionality was used to map all 3 source columns to the correct destination columns. Here, we will go into some more detail on manually mapping and additional options users have to quickly sort and filter the list of mappings.
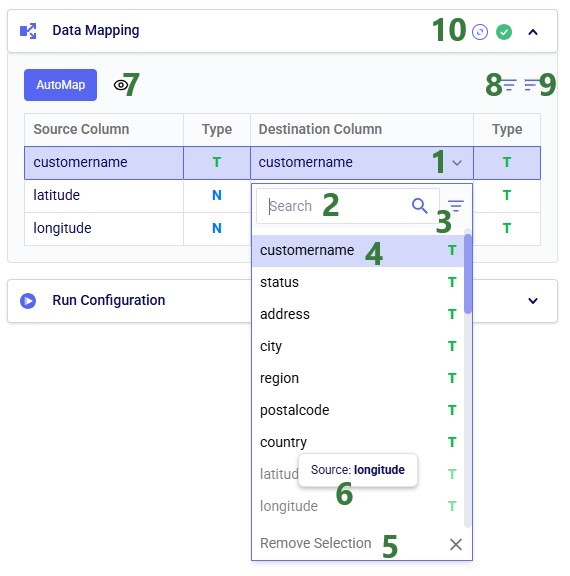
In this quick start guide we will walk through the steps of modifying data in a table in the Project Sandbox using Update tasks. These changes can either be made to all records in a table or a subset based on a filtering condition. Any PostgreSQL function can be used when configuring the update statements and conditions of Update tasks.
This quick start guide builds upon a previous one where unique customers were created from historical shipments using a Leapfrog-generated Run SQL task. Please follow the steps in that quick start guide first if you want to follow along with the steps in this one. The starting point for this quick start is therefore a project named “Import Historical Shipments”, which contains a macro called Import Shipments. This macro has an Import task and a Run SQL task. The project has a Historical Shipments data connection of type = CSV, and the Project Sandbox contains 2 tables named rawshipments (42,656 records) and customers (1,333 records). Note that if you also followed one of the other quick start guides on exporting data to a Cosmic Frog model (see here), your project will also contain an Export task, and a Cosmic Frog data connection; you can still follow along with this quick start guide too.
The steps we will walk through in this quick start guide are:
We have a look at the customers table which was created from the historical shipment data in the previous 2 quick start guides, see the screenshot below. Sorting on the customername column, we see that they are ordered in alphabetical order. This is because the customer name column is of type text as it starts with the string “CZ”. This leads to them not being ordered based on the number part that follows the “CZ” prefix.

If we want ordering customer names alphabetically to result in an order that is the same as sorting the number part of the customer name, we need to make sure each customer name has the same number of digits. We will use Update tasks to change the format of the number part of the customer names so that they are all 4 digits by adding leading 0’s to those that have less than 4 digits. While we are at it, we will also replace the “CZ” prefix with “Cust_” to make the data consistent with other data sources that contain customer names. We will break the updates to the customer name column up into 3 steps using 3 Update tasks initially. At the end, we will see how they can be combined into a single Update task. The 3 steps are:
Let us add the first Update task to our Import Shipments macro:
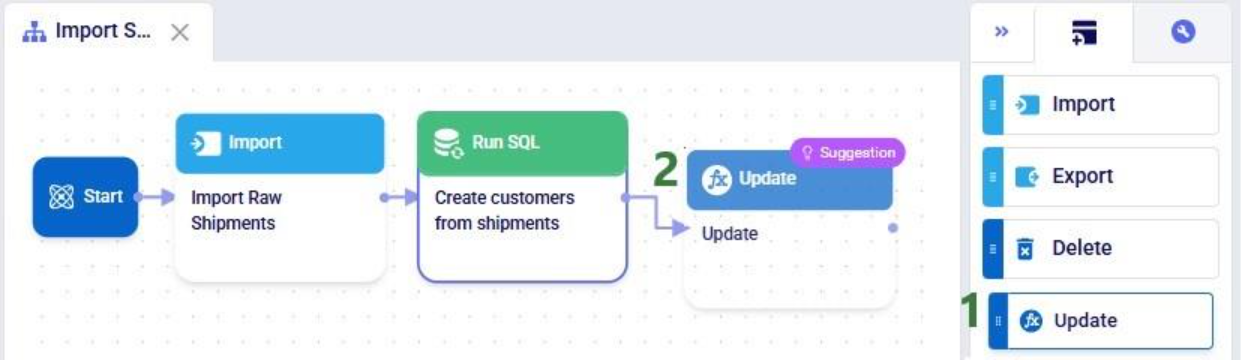
After dropping the Update task onto the macro canvas, its configuration tab will be opened automatically on the right-hand side:

If you have not already, click on the plus button to add your first update statement:
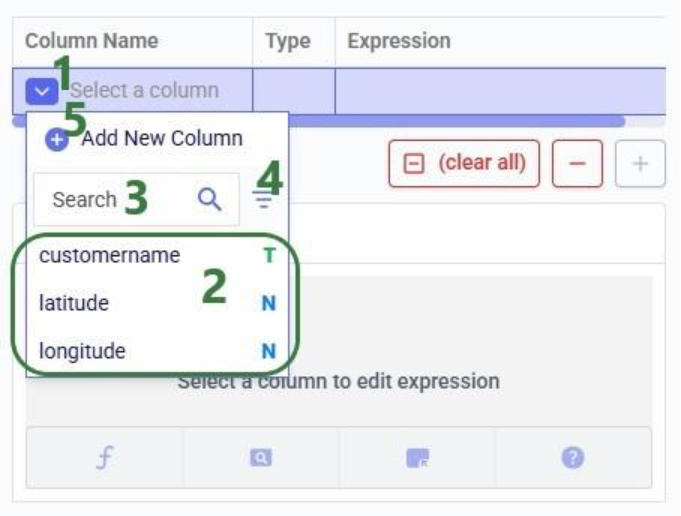
Next, we will write the expression for which we can use the Expression Builder area just below the update statements table. What we type there will also be added to the Expression column of the selected Update Statement. These expressions can use any PostgreSQL function, also those which may not be pre-populated in the helper lists. Please see the PostgreSQL documentation for all available functions.
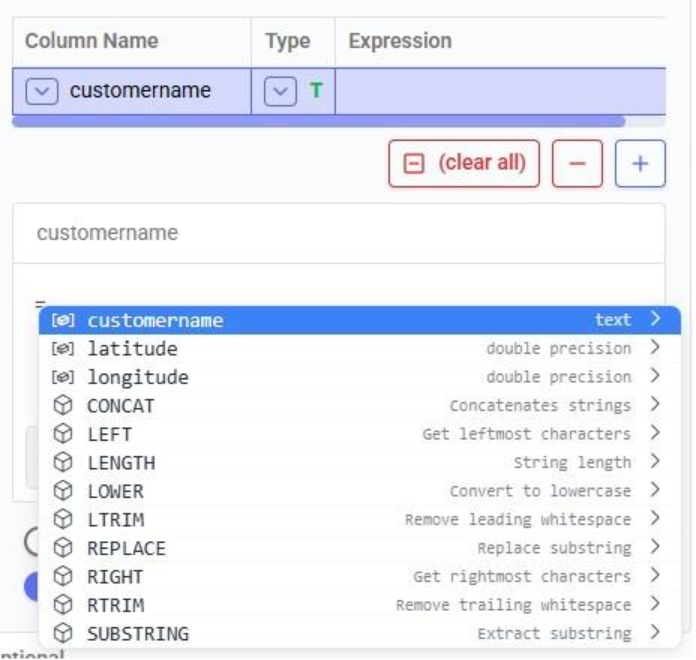
When clicking in the Expression Builder, an equal sign is already there, and a list of items comes up. At the top are the columns that are present in the target table and below those is a list of string functions which we can select to use. Here, the functions shown are string functions, since we are working on a text type column, when working on column with a different data type, other functions, those relevant to the data type, will be shown. We will select the last option shown in the screenshot, the substring function, since we want to first remove the “CZ” from the start of the customer names:
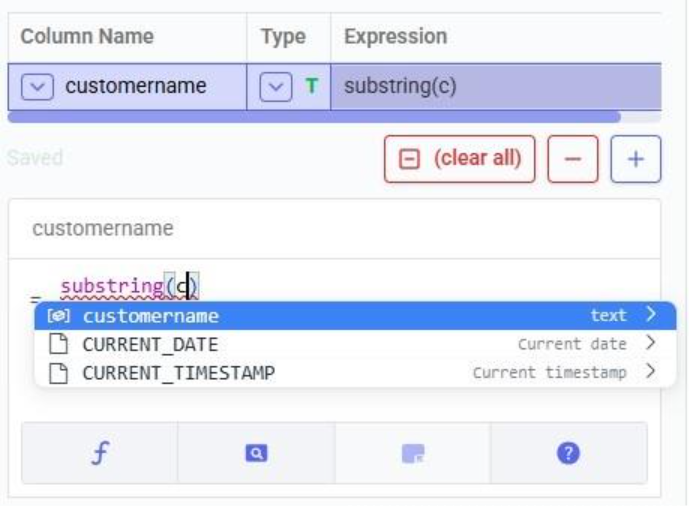
The substring function needs at least 2 arguments, which will be specified in the parentheses. The first argument needs to be the customername column in our case, since that is the column containing the string values we want manipulate. After typing a “c”, the customername column and 2 functions starting with “c” are suggested in the pop-up list. We choose the customername column. The second argument specifies the start location from where we want to start the substring. Since we want to remove the “CZ”, we specify 3 as the start location, leaving characters number 1 and 2 off. The third argument is optional; it indicates the end location of the substring. We do not specify it, meaning we want to keep all characters starting from character number 3:

We can run this task now without specifying a Condition (see section further below) in which case the expression will be applied to all records in the customers table. After running the task, we open the customers table to see the result:

We see that our intended change was made. The “CZ” is removed from the customer names. Sorted alphabetically, they still are not in increasing order of the number part of their name. Next, we use the lpad (left pad) function to add leading zeroes so all customer names consist of 4 digits. This function has 3 arguments: the string to apply the left padding to (the customername column), the number of characters the final string needs to have (4), and the padding character (‘0’).

After running this task, the customername column values are as follows:
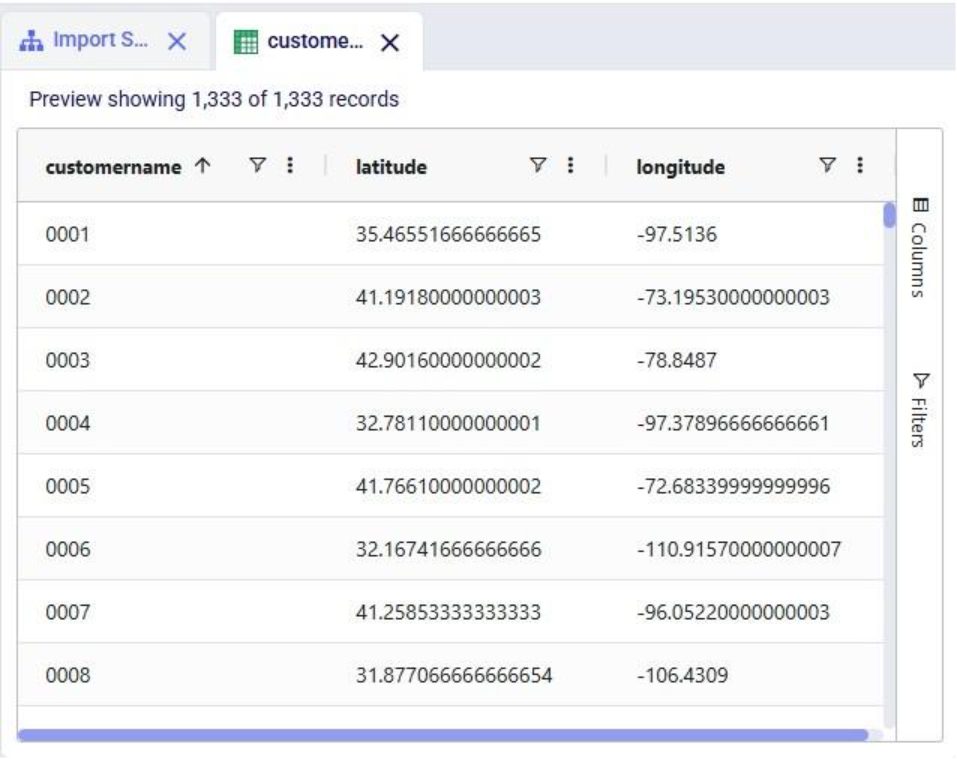
Now with the leading zeroes and all customer names being 4 characters long, sorting alphabetically results in the same order as sorting by the number part of the customer name.
Finally, we want to add the prefix “Cust_”. We use the concat (concatenation) function for this. At first, we type Cust_ with double quotes around it, but the squiggly red line below the expression in the expression builder indicates this is not the right syntax. Hovering over the expression in the expression builder explains the problem:

The correct syntax for using strings in these functions is to use single quotes:
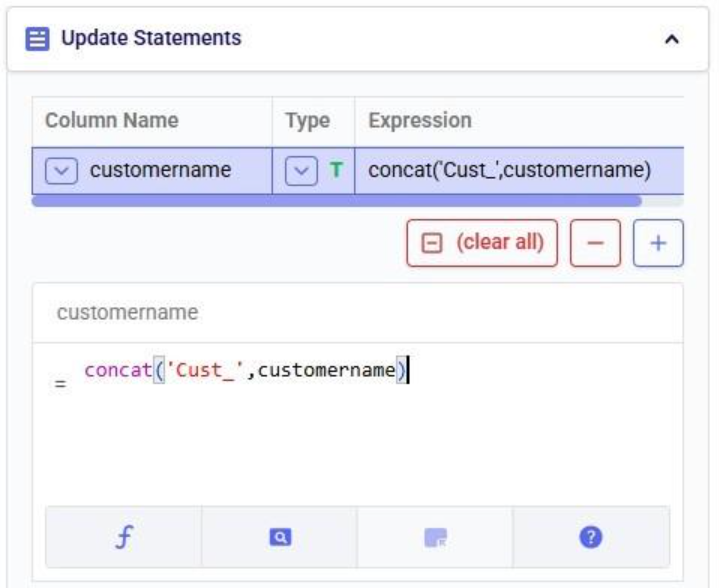
Instead of concat we can also use “= ‘Cust_’ || customername” as the expression. The double pipe symbol is used in PostgreSQL as the concatenation operator.
Running this third update task results in the following customer names in the customers table:
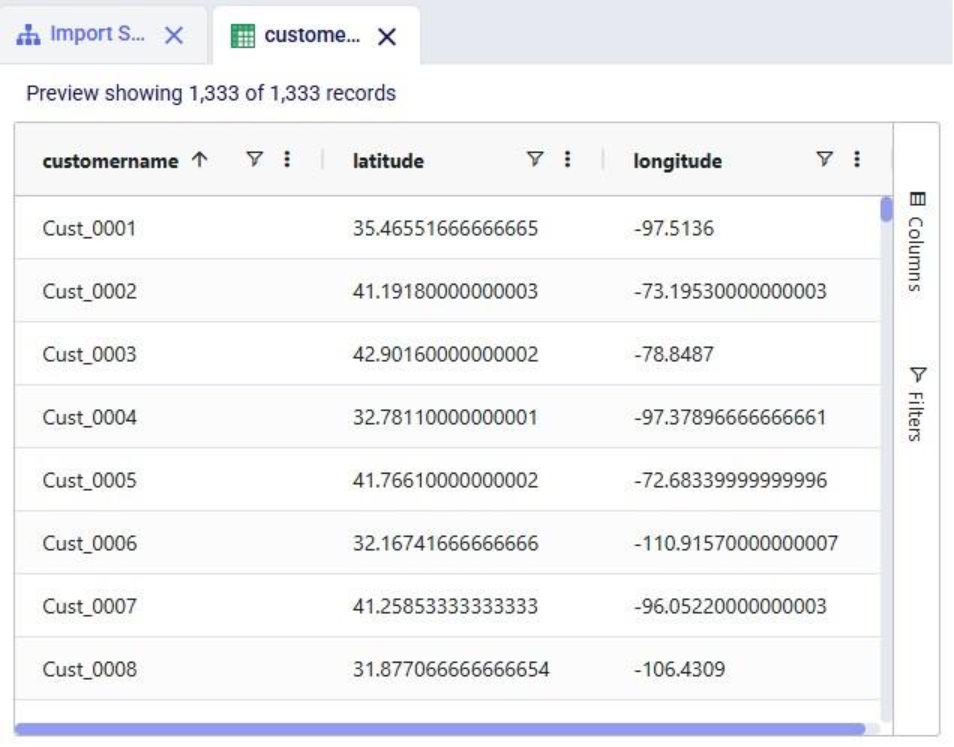
Our goal of how we wanted to update the customername column has been achieved. Our macro now looks as follows with the 3 Update tasks added:
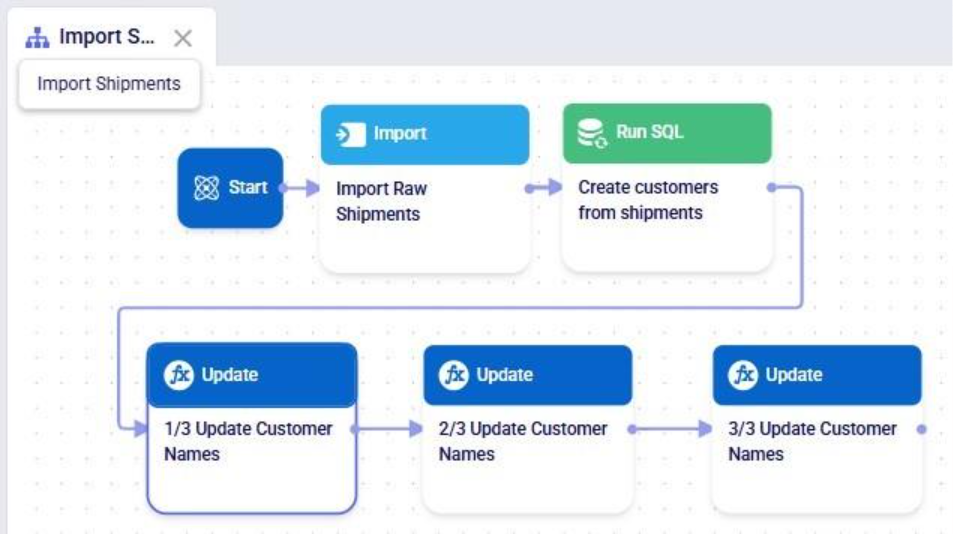
The 3 tasks described above can be combined into 1 Update task by nesting the expressions as follows:

Running this task instead of the 3 above will result in the same changes to the customername column in the customers table.
Please note that in the above we only specified one update statement in each Update task. You can add more than one update statement per update task, in which case:
As mentioned above, the list of suggested functions is different depending on the data type of the column being updated. This screenshot shows part of the suggested functions for a number column:
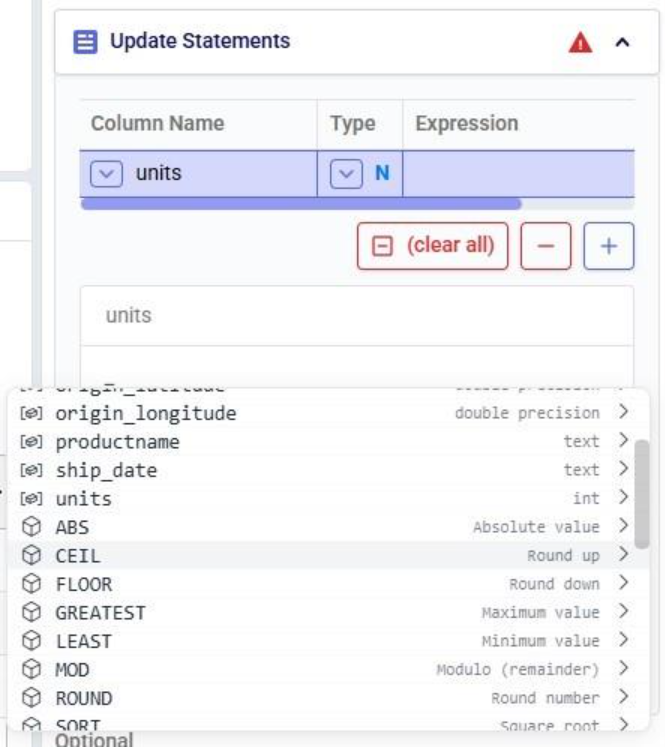
At the bottom of Expression Builder are multiple helper tabs to facilitate quickly building your desired expressions. The first one is the Function Helper which lists the available functions. The functions are listed by category: string, numeric, date, aggregate, and conditional. At the top of the list user has search, filter and sort options available to quickly find a function of interest. Hovering over a function in the list will bring up details of the function, from top to bottom: a summary of the format and input and output data types of the function, a description of what the function does, its input parameter(s), what it returns, and an example:
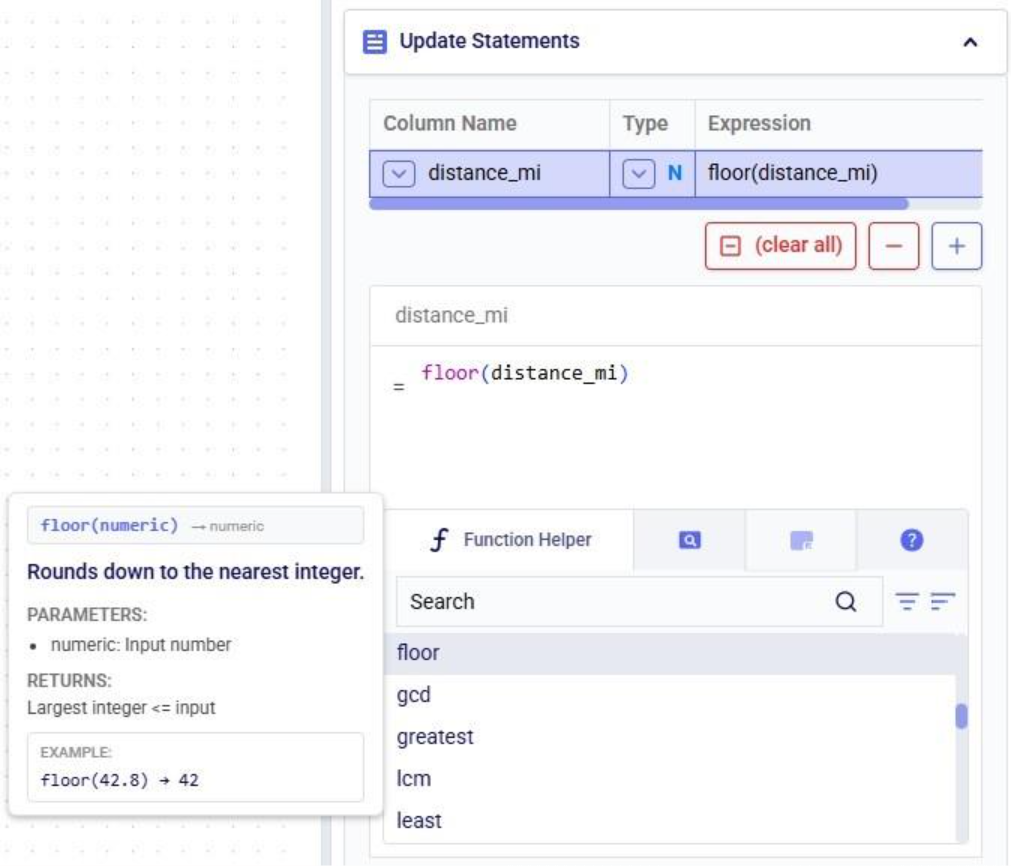
The next helper tab contains the Field Helper. This lists all the columns of the target table, sorted by their data type. Again, to quickly find the desired field, users can search, filter, and sort the list using the options at the top of the list:
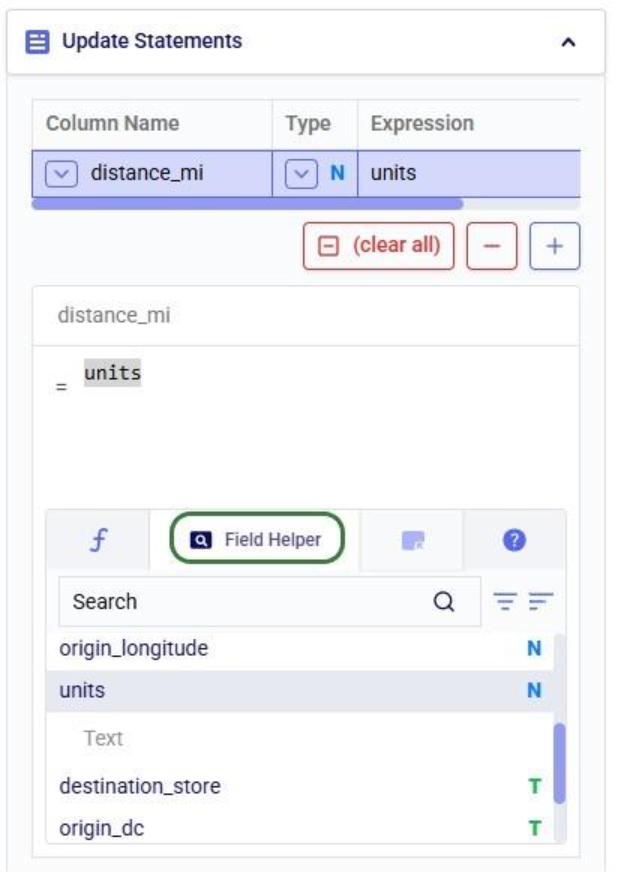
The fourth tab is the Operator Helper, which lists several helpful numerical and string operators. This list can be searched too using the Search box at the top of the list:
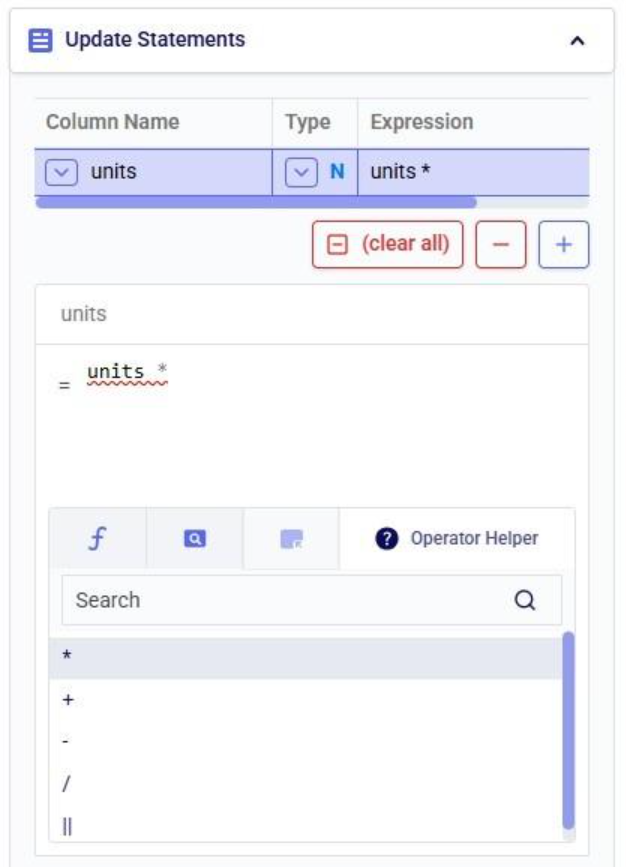
There is another optional configuration section for Update tasks, the Condition section. In here, users can specify an expression to filter the target table on before applying the update(s) specified in the Update Statements section. This way, the updates are only applied to the subset of records that match the condition.
In this example, we will look at some records of the rawshipments table in the project sandbox of the same project (“Import Historical Shipments). We have opened this table in a grid and filtered for origin_dc Salt Lake City DC and destination_store CZ103.

What we want to do is update the “units” column and increase the values by 50% for the Table product. The Update Statements section shows that we set the units field to its current value multiplied by 1.5, which will achieve the 50% increase:

However, if we run the Update task as is, all values in the units field will be increased by 50%, for both the Table and the Chair product. To make sure we only apply this increase to the Table product, we configure the Condition section as follows:
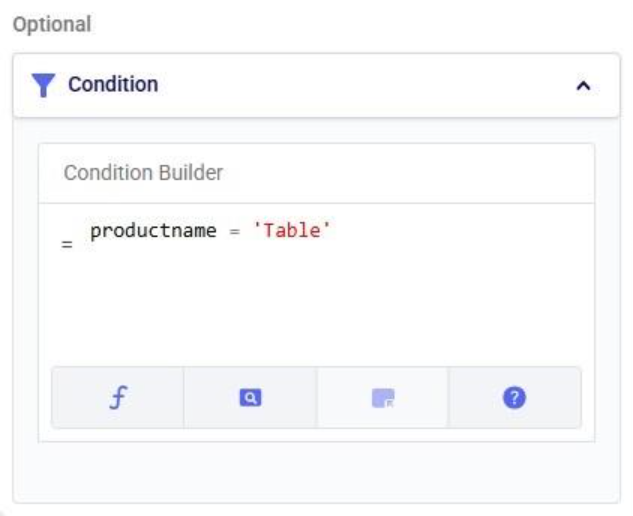
The condition builder has the same function, field, and operator helper tabs at the bottom as the expression builder in the update statements section to enable users to quickly build their conditions. Building conditions works in the same way as building expressions.
Running the task and checking the updated rawshipments table for the same subset of records as we saw above, we can check that it worked as intended. The values in the units column for the Table records are indeed 1.5 times their original value, while the Chair units are unchanged.
It is important to note that opening tables in DataStar currently shows a preview of 10,000 records. When filtering a table by clicking on the filter icons to the right of a column name, only the resulting subset of records from those first 10,000 records will be included. While an Update task will be applied to all records in a table, due to this limit on the number of records in the preview you may not always be able to see (all) results of your Update task in the grid. In addition, an Update task can also change the order of the records in the table. This can lead to a filter showing a different set of records after running an update task as compared to the filtered subset that was shown prior to running it. Users can use the SQL Editor application on the Optilogic platform to see the full set of records for any tables.
Finally, if you want to apply multiple conditions you can use logical AND and OR statements to combine them in the Expression Builder. You would for example specify the condition as follows if you want to increase the units for the Table product by 50% only for the records where the origin_dc value is either “Dallas DC” or “Detroit DC”:
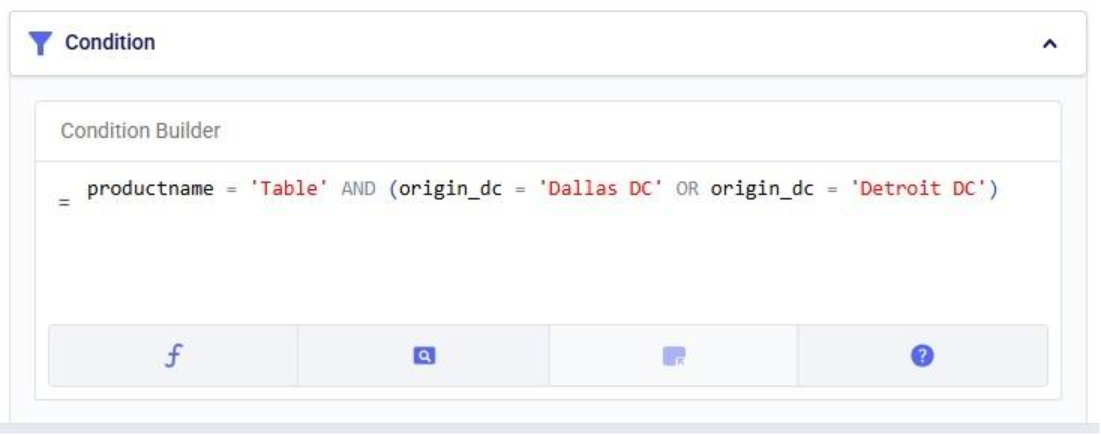
In this quick start guide we will show how users can seamlessly go from using the Resource Library, Cosmic Frog and DataStar applications on the Optilogic platform to creating visualizations in Power BI. The example covers cost to serve analysis using a global sourcing model. We will run 2 scenarios in this Cosmic Frog model with the goal to visualize the total cost difference between the scenarios by customer on a map. We do this by coloring the customers based on the cost difference.
The steps we will walk through are:
We will first copy the model named “Global Sourcing – Cost to Serve” from the Resource Library to our Optilogic account (learn more about the Resource Library in this help center article):
On the Optilogic platform, go to the Resource Library application by clicking on its icon in the list of applications on the left-hand side; note that you may need to scroll down. Should you not see the Resource Library icon here, then click on the icon with 3 horizontal dots which will then show all applications that were previously hidden too.
Now that the model is in the user’s account, it can be opened in the Cosmic Frog application:


We will only have a brief look at some high-level outputs in Cosmic Frog in this quick start guide, but feel free to explore additional outputs. You can learn more about Cosmic Frog through these help center articles. Let us have a quick look at the Optimization Network Summary output table and the map:

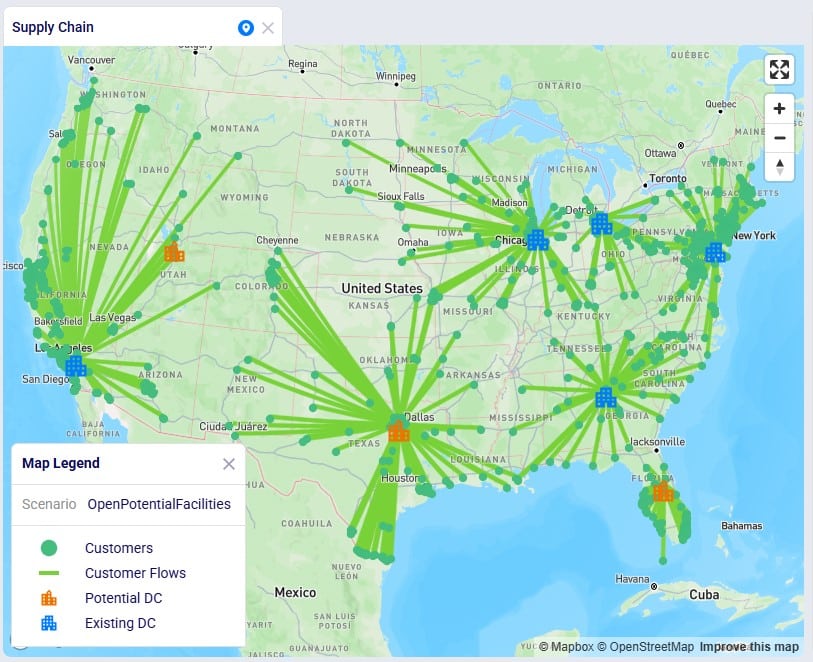
Our next step is to import the needed input table and output table of the Global Sourcing – Cost to Serve model into DataStar. Open the DataStar application on the Optilogic platform by clicking on its icon in the applications list on the left-hand side. In DataStar, we first create a new project named “Cost to Serve Analysis” and set up a data connection to the Global Sourcing – Cost to Serve model, which we will call “Global Sourcing C2S CF Model”. See the Creating Projects & Data Connections section in the Getting Started with DataStar help center article on how to create projects and data connections. Then, we want to create a macro which will calculate the increase/decrease in total cost by customer between the 2 scenarios. We build this macro as follows:

The configuration of the first import task, C2S Path Summary, is shown in this screenshot:

The configuration of the other import task, Customers, uses the same Source Data Connection, but instead of the optimizationcosttoservepathsummary table, we choose the customers table as the table to import. Again, the Project Sandbox is the Destination Data Connection, and the new table is simply called customers.
Instead of writing SQL queries ourselves to pivot the data in the cost to serve path summary table to create a new table where for each customer there is a row which has the customer name and the total cost for each scenario, we can use Leapfrog to do it for us. See the Leapfrog section in the Getting Started with DataStar help center article and this quick start guide on using natural language to create DataStar tasks to learn more about using Leapfrog in DataStar effectively. For the Pivot Total Cost by Scenario by Customer task, the 2 Leapfrog prompts that were used to create the task are shown in the following screenshot:

The SQL Script reads:
DROP TABLE IF EXISTS total_cost_by_customer_combined;
CREATE TABLE total_cost_by_customer_combined AS
SELECT
pathdestination AS customer,
SUM(CASE WHEN scenarioname = 'Baseline' THEN pathcost ELSE 0 END)
AS total_cost_baseline,
SUM(CASE WHEN scenarioname = 'OpenPotentialFacilities' THEN pathcost ELSE 0 END)
AS total_cost_openpotentialfacilities
FROM c2s_path_summary
WHERE scenarioname IN ('Baseline', 'OpenPotentialFacilities')
GROUP BY pathdestination
ORDER BY pathdestination;
To create the Calculate Cost Savings by Customer task, we gave Leapfrog the following prompt: “Use the total cost by customer table and add a column to calculate cost savings as the baseline cost minus the openpotentalfacilities cost”. The resulting SQL Script reads as follows:
ALTER TABLE total_cost_by_customer_combined
ADD COLUMN cost_savings DOUBLE PRECISION;
UPDATE total_cost_by_customer_combined
SET
cost_savings = total_cost_baseline - total_cost_openpotentialfacilities;
This task is also added to the macro; its name is "Calculate Cost Savings by Customer".
Lastly, we give Leapfrog the following prompt to join the table with cost savings (total_cost_by_customer_combined) and the customers table to add the coordinates from the customers table to the cost savings table: “Join the customers and total_cost_by_customer_combined tables on customer and add the latitude and longitude columns from the customers table to the total_cost_by_customer_combined table. Use an inner join and do not create a new table, add the columns to the existing total_cost_by_customer_combined table”. This is the resulting SQL Script, which was added to the macro as the "Add Coordinates to Cost Savings" task:
ALTER TABLE total_cost_by_customer_combined ADD COLUMN latitude VARCHAR;
ALTER TABLE total_cost_by_customer_combined ADD COLUMN longitude VARCHAR;
UPDATE total_cost_by_customer_combined SET latitude = c.latitude
FROM customers AS c
WHERE total_cost_by_customer_combined.customer = c.customername;
UPDATE total_cost_by_customer_combined SET longitude = c.longitude
FROM customers AS c
WHERE total_cost_by_customer_combined.customer = c.customername;We can now run the macro, and once it is completed, we take a look at the tables present in the Project Sandbox:
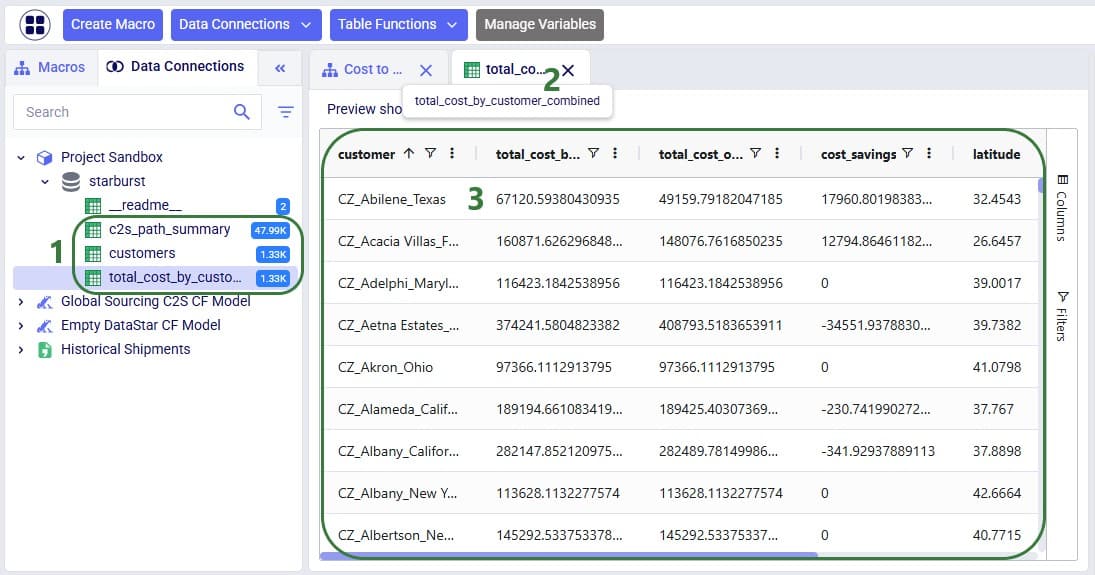
We will use Microsoft Power BI to visualize the change in total cost between the 2 scenarios by customer on a map. To do so, we first need to set up a connection to the DataStar project sandbox from within Power BI. Please follow the steps in the “Connecting to Optilogic with Microsoft Power BI” help center article to create this connection. Here we will just show the step to get the connection information for the DataStar Project Sandbox, which underneath is a PostgreSQL database (next screenshot) and selecting the table(s) to use in Power BI on the Navigator screen (screenshot after this one):
After selecting the connection within Power BI and providing the credentials again, on the Navigator screen, choose to use just the total_cost_by_customer_combined table as this one has all the information needed for the visualization:
We will set up the visualization on a map using the total_cost_by_customer_combined table that we have just selected for use in Power BI using the following steps:
With the above configuration, the map will look as follows:
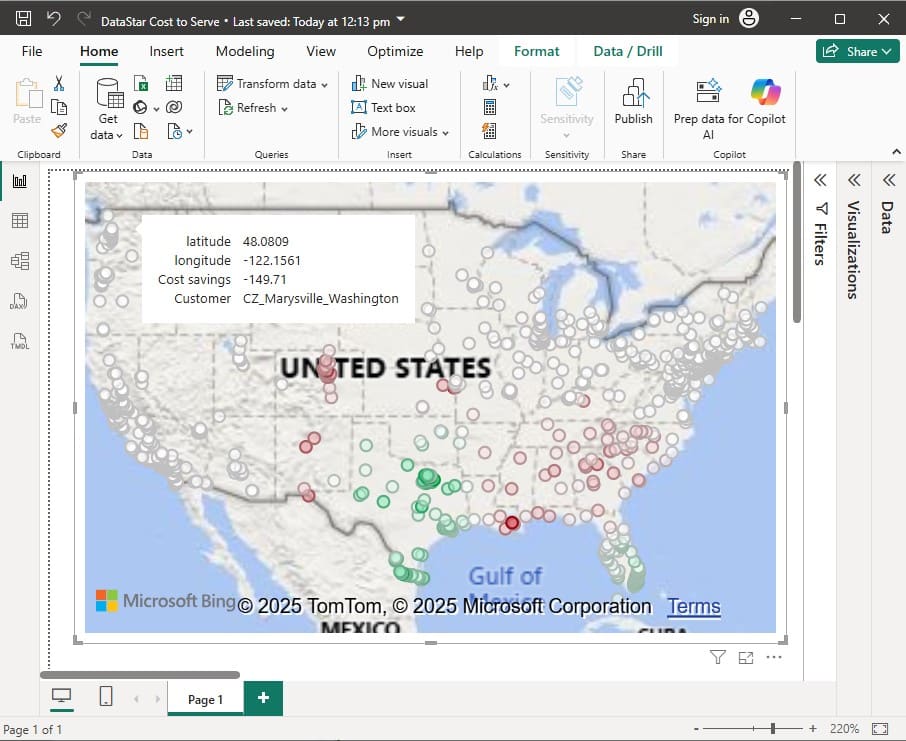
Green customers are those where the total cost went down in the OpenPotentialFacilities scenario, i.e. there are savings for this customer. The darker the green, the higher the savings. White customers did not see a lot of difference in their total costs between the 2 scenarios. The one that is hovered over, in Marysville in Washington state, has a small increase of $149.71 in total costs in the OpenPotentialFacilities scenario as compared to the Baseline scenario. Red customers are those where the total cost went up in the OpenPotentialFacilities scenario (i.e. the cost savings are a negative number); the darker the red, the higher the increase in total costs. As expected, the customers with the highest cost savings (darkest green) are those located in Texas and Florida, as they are now being served from DCs closer to them.
To give users an idea of what type of visualization and interactivity is possible within Power BI, we will briefly cover the 2 following screenshots. These are of a different Cosmic Frog model for which a cost to serve analysis is performed too. Two scenarios were run in this model: Baseline DC and Blue Sky DC. In the Baseline scenario, customers are assigned to their current DCs and in the Blue Sky scenario, they can be re-assigned to other DCs. The chart on the top left shows the cost savings by region (= US state) that are identified in the Blue Sky DC scenario. The other visualizations on the dashboard are all on maps: the top right map shows the customers which are colored based on which DC serves them in the Baseline scenario, the bottom 2 maps shows the DCs used in the Baseline (left) and the DCs used in the Blue Sky scenario.
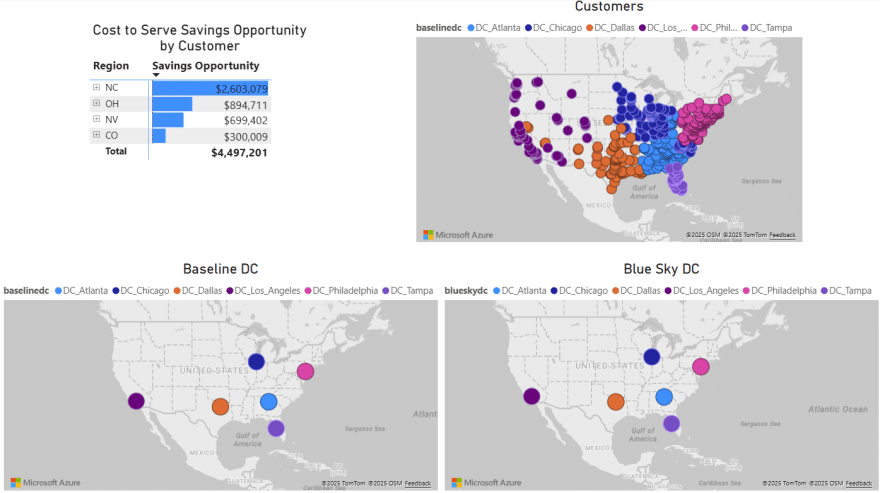
To drill into the differences between the 2 scenarios, users can expand the regions in the top left chart and select 1 or multiple individual customers. This is an interactive chart, and the 3 maps are then automatically filtered for the selected location(s). In the below screenshot, the user has expanded the NC region and then selected customer CZ_593_NC in the top left chart. In this chart, we see that the cost savings for this customer in the Blue Sky DC scenario as compared to the Baseline scenario amount to $309k. From the Customers map (top right) and Baseline DC map (bottom left) we see that this customer was served from the Chicago DC in the Baseline. We can tell from the Blue Sky DC map (bottom right) that this customer is re-assigned to be served from the Philadelphia DC in the Blue Sky DC scenario.
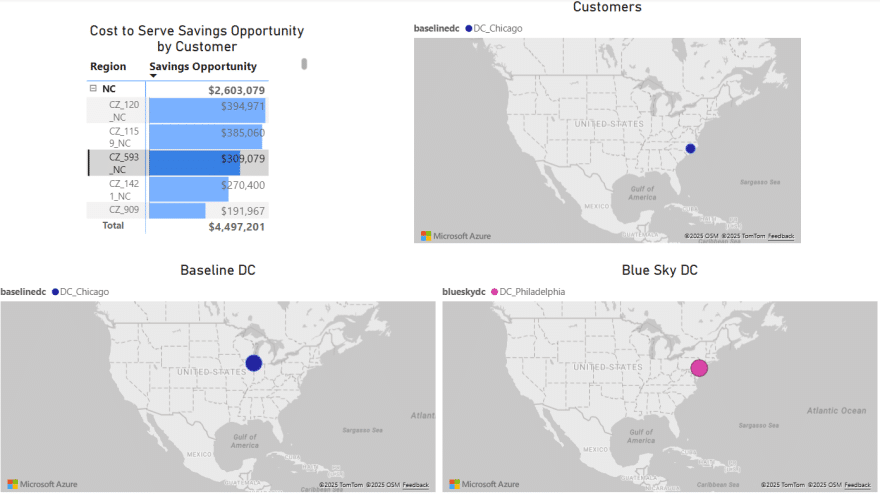
Optilogic has developed Python libraries to facilitate scripting for 2 of its flagship applications: Cosmic Frog, the most powerful supply chain design tool on the market, and DataStar, its just released AI-powered data product where users can create flexible, accessible and repeatable workflows with zero learning curve.
Instead of going into the applications themselves to build and run supply chain models and data workflows, these libraries enable users to programmatically access their functionality and underlying data. Example use cases for such scripts are:
In this documentation we cover the basics of getting yourself set up so you can take advantage of these Python scripting libraries, both on a local computer and on the Optilogic platform leveraging the Lightning Editor application. More specific details for the cosmicfrog and datastar libraries, including examples and end-to-end scripts, are detailed in the following Help Center articles and library specifications:
Working locally with Python scripts has the advantage that you can make use of code completion features which may include text auto-completion, showing what arguments functions need, catching incorrect syntax/names, etc. An example set up to achieve this is for example one where Python, Visual Studio Code, and an IntelliSense extension package for Python for Visual Studio Code are installed locally:
Once you are set up locally and are starting to work with Python scripts in Visual Studio Code, you will need to install the Python libraries you want to use to have access to their functionality. You do this by typing following in a terminal in Visual Studio Code (if no terminal is open yet: click on the View menu at the top and select Terminal, or the keyboard shortcut Ctrl + ` can be used):
When installing these libraries, multiple external libraries (dependencies) are installed too. These are required to run the packages successfully and/or make working with them easier. These include the optilogic, pandas, and SQLAlchemy packages (among others) for both libraries. You can find out which packages are installed with the cosmicfrog / ol-datastar libraries by typing “pip show cosmicfrog” or “pip show ol-datastar" in a terminal.
To use other Python libraries in addition, you will usually need to install them using “pip install” too before you can leverage them.
If you want to access certain items on the Optilogic platform (like Cosmic Frog models, DataStar project sandboxes) while working locally, you will need to whitelist your IP address on the platform, so the connections are not blocked by a firewall. You can do this yourself on the Optilogic platform:

Please note that for working with DataStar, the whitelisting of your IP address is only necessary if you want to access the Project Sandbox of projects directly through scripts. You do not need to whitelist your IP address to leverage other functions while scripting, like creating projects, adding macros and their tasks, and running macros.
App Keys are used to authenticate the user from the local environment on the Optilogic platform. To create an App Key, see this Help Center Article on Generating App and API Keys. Copy the generated App Key and paste it into an empty Notepad window. Save this file as app.key and place it in the same folder as your local Python script.
It is important to emphasize that App Keys and app.key files should not be shared with others, e.g. remove them from folders / zip-files before sharing. Individual users need to authenticate with their own App Key.
The next set of screenshots will show an example Python script named testing123.py on our local set-up. Here it uses the cosmicfrog library, using the ol-datastar library works similarly. The first screenshot shows a list of functions available from the cosmicfrog Python library:
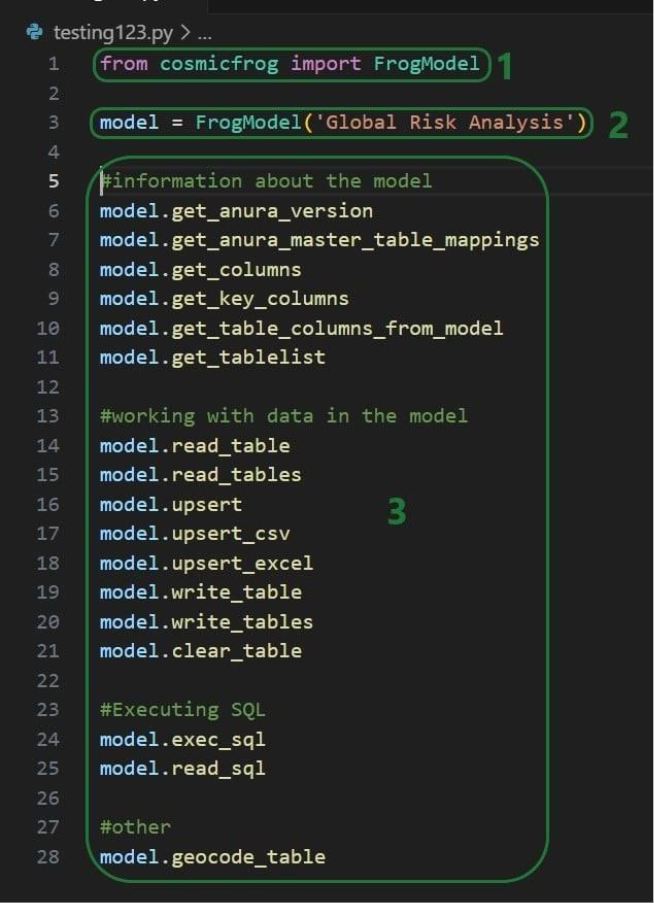
When you continue typing after you have typed “model.” the code completion feature will auto-generate a list of functions you may be getting at. In the next screenshot ones that start with or contain a “g” as I have only typed a “g” so far. This list will auto-update the more you type. You can select from the list with your cursor or arrow up/down keys and hitting the Tab key to select and auto-complete:
When you have completed typing the function name and next type a parenthesis ‘(‘ to start entering arguments, a pop-up will come up which contains information about the function and its arguments:
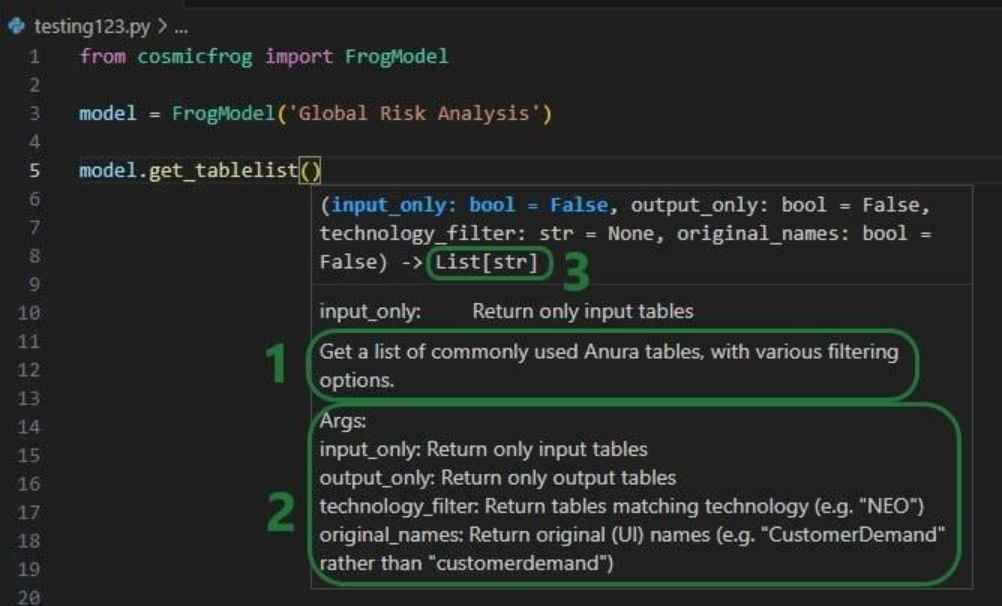
As you type the arguments for the function, the argument that you are on and the expected format (e.g. bool for a Boolean, str for string, etc.) will be in blue font and a description of this specific argument appears above the function description (e.g. above box 1 in the above screenshot). In the screenshot above we are on the first argument input_only which requires a Boolean as input and will be set to False by default if the argument is not specified. In the screenshot below we are on the fourth argument (original_names) which is now in blue font; its default is also False, and the argument description above the function description has changed now to reflect the fourth argument:
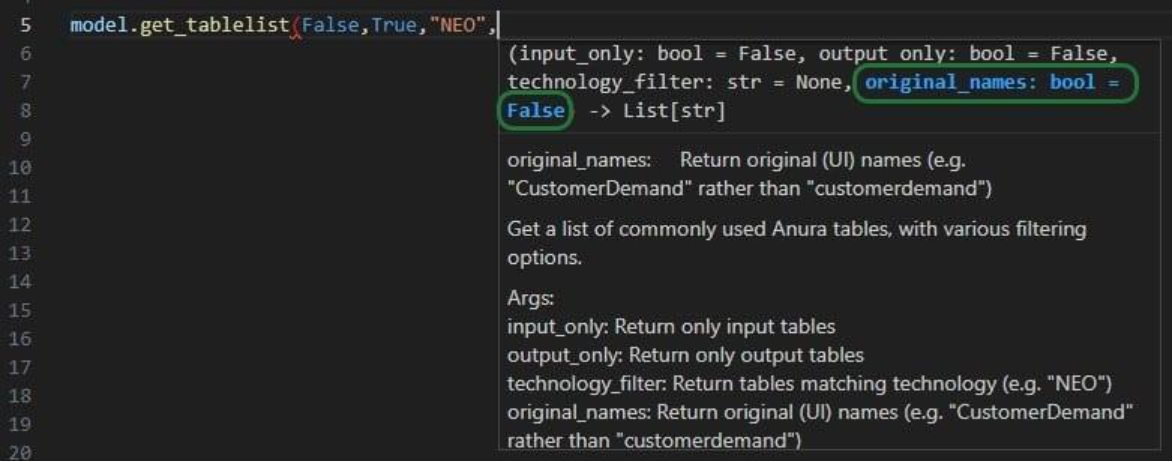
Once you are ready to run a script, you can click on the play button at the top right of the screen:
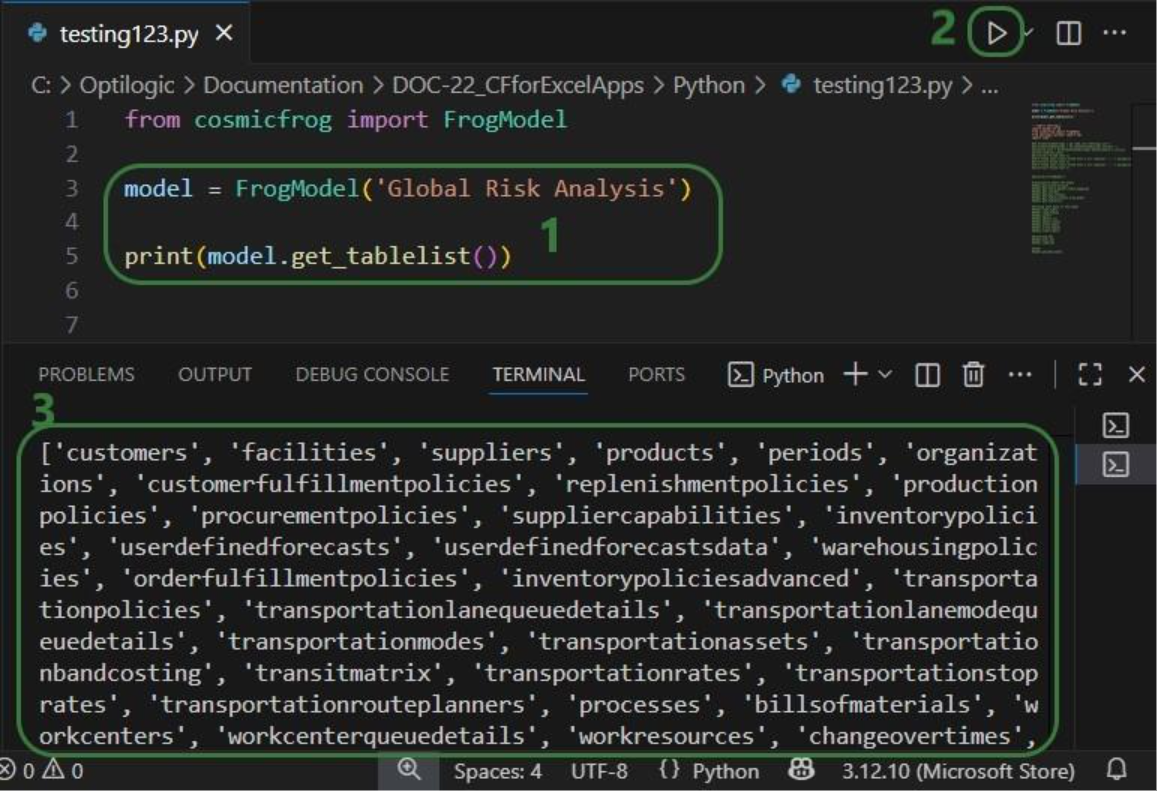
As mentioned above, you can also use the Lightning Editor application on the Optilogic platform to create and run Python scripts. Lightning Editor is an Integrated Development Environment (IDE) which has some code completion features, but these are not as extensive and complete as those in Visual Studio Code when used with an IntelliSense extension package.
When working on the Optilogic platform, you are already authenticated as a user, and you do not need to generate / provide an App Key or app.key file nor whitelist your IP address.
When using the datastar library in scripts, users need to place a requirements.txt file in the same folder on the Optilogic platform as the script. This file should only contain the text “ol-datastar” (without the quotes). No requirements.txt files is required when using the cosmicfrog library.
The following simple test.py Python script on Lightning Editor will print the first Hopper output table name and its column names:
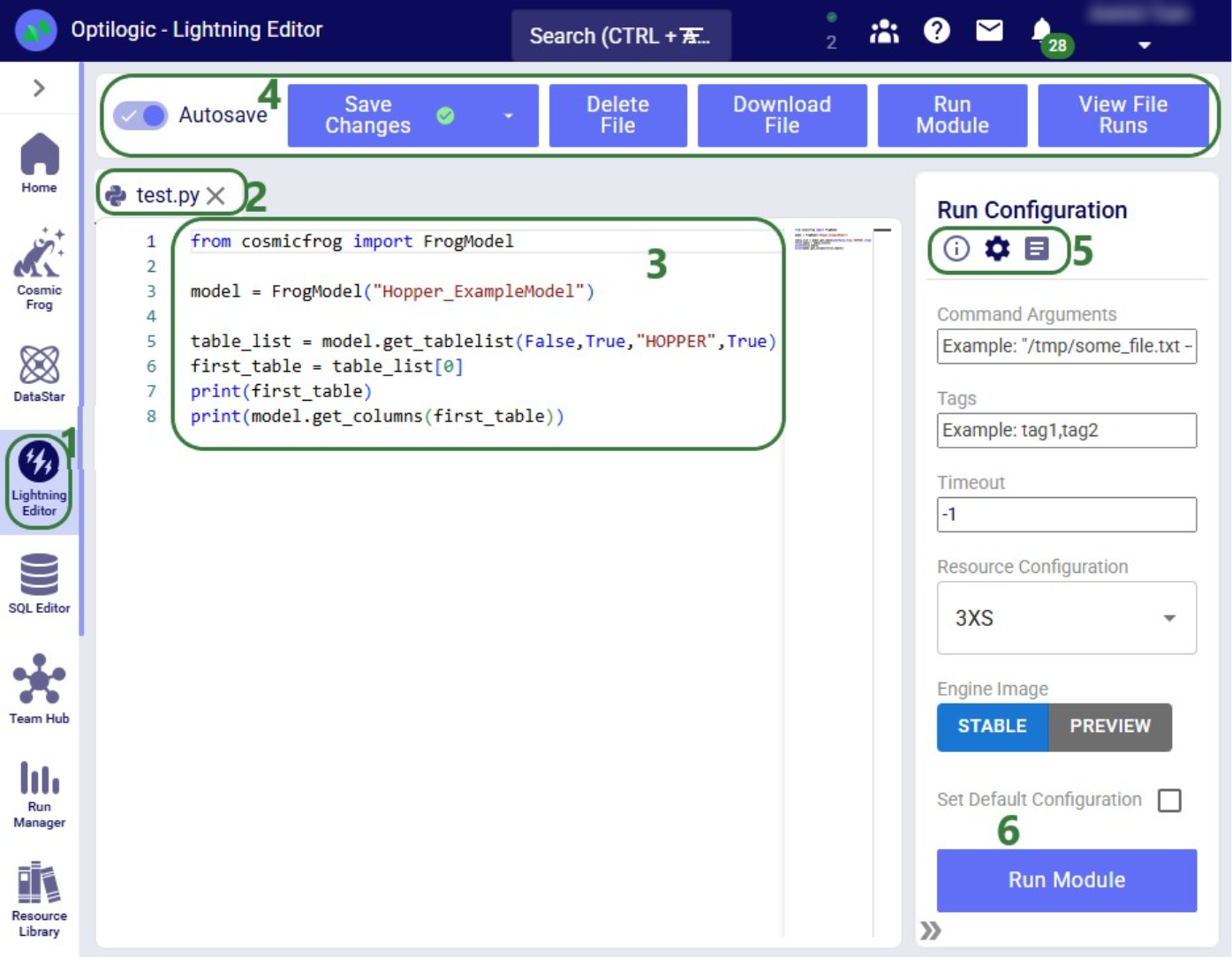

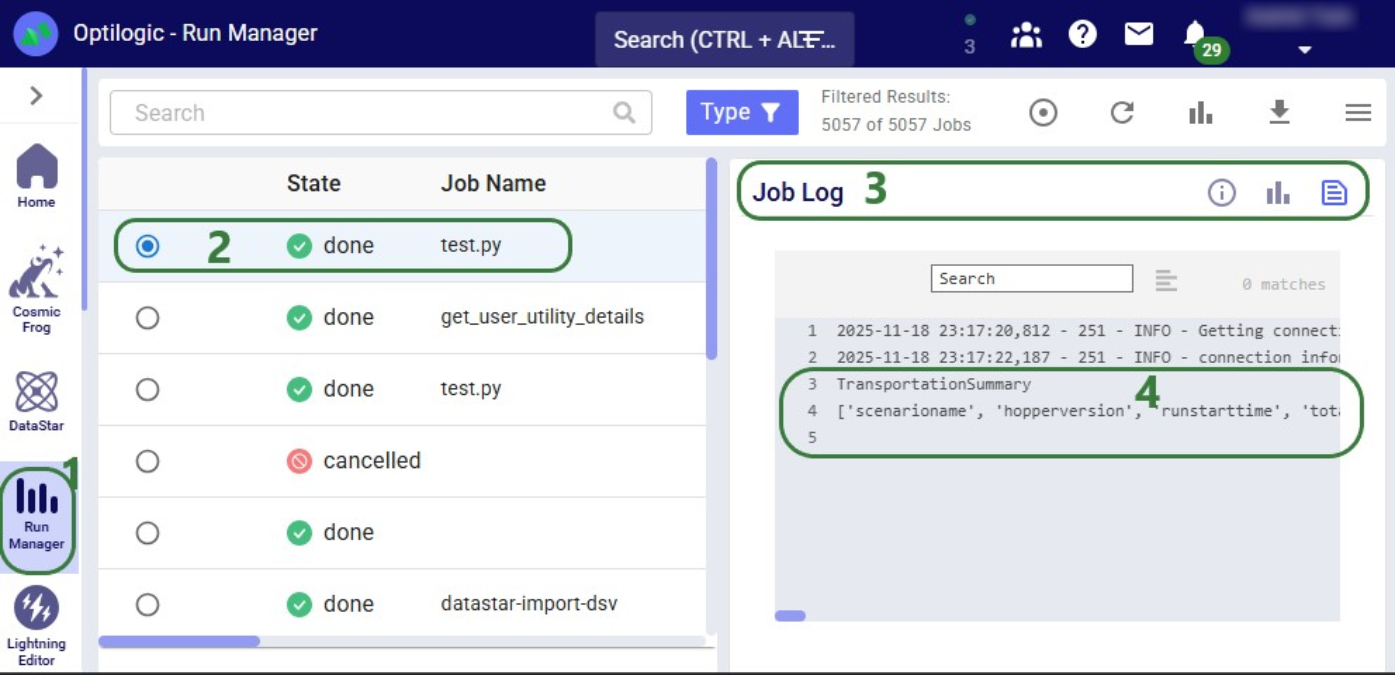
DataStar users can take advantage of the datastar Python library, which gives users access to DataStar projects, macros, tasks, and connections through Python scripts. This way users can build, access, and run their DataStar workflows programmatically. The library can be used in a user’s own Python environment (local or on the Optilogic platform), and it can also be used in Run Python tasks in a DataStar macro.
In this documentation we will cover how to use the library through multiple examples. At the end, we will step through an end-to-end script that creates a new project, adds a macro to the project, and creates multiple tasks that are added to the macro. The script then runs the macro while giving regular updates on its progress.
Before diving into the details of this article, it is recommended to read this “Setup: Python Scripts for Cosmic Frog and DataStar” article first; it explains what users need to do in terms of setup before they can run Python scripts using the datastar library. To learn more about the DataStar application itself, please see these articles on Optilogic’s Help Center.
Succinct documentation in PDF format of all datastar library functionality can be downloaded here (please note that the long character string at the beginning of the filename is expected). This includes a list of all available properties and methods for the Project, Macro, Task, and Connection classes at the end of the document.
All Python code that is shown in the screenshots throughout this documentation is available in the Appendix, so that you can copy-paste from there if you want to run the exact same code in your own Python environment and/or use these as jumping off points for your own scripts.
If you have reviewed the “Setup: Python Scripts for Cosmic Frog and DataStar” article and are set up with your local or online Python environment, we are ready to dive in! First, we will see how we can interrogate existing projects and macros using Python and the datastar library. We want to find out which DataStar projects are already present in the user’s Optilogic account.

Once the parentheses are typed, hover text comes up with information about this function. It tells us that the outcome of this method will be a list of strings, and the description of the method reads “Retrieve all project names visible to the authenticated user”. Most methods will have similar hover text describing the method, the arguments it takes and their default values, and the output format.
Now that we have a variable that contains the list of DataStar projects in the user account, we want to view the value of this variable:
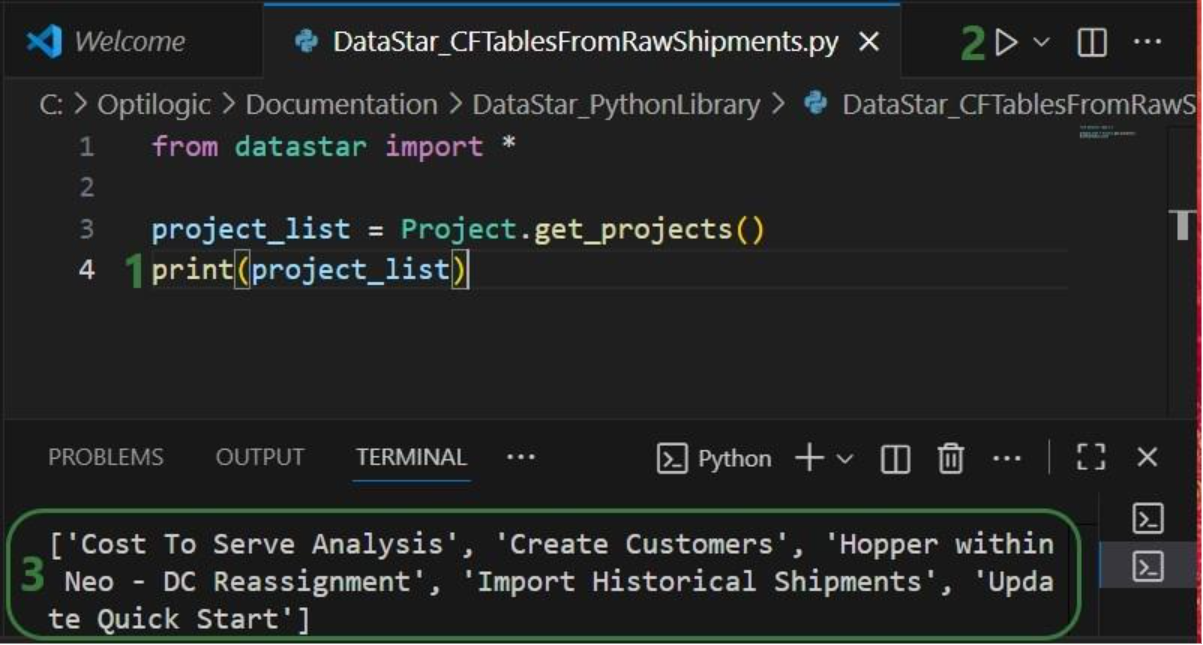
Next, we want to dig one level deeper and for the “Import Historical Shipments” project find out what macros it contains:

Finally, we will retrieve the tasks this “Import Shipments” macro contains in a similar fashion:
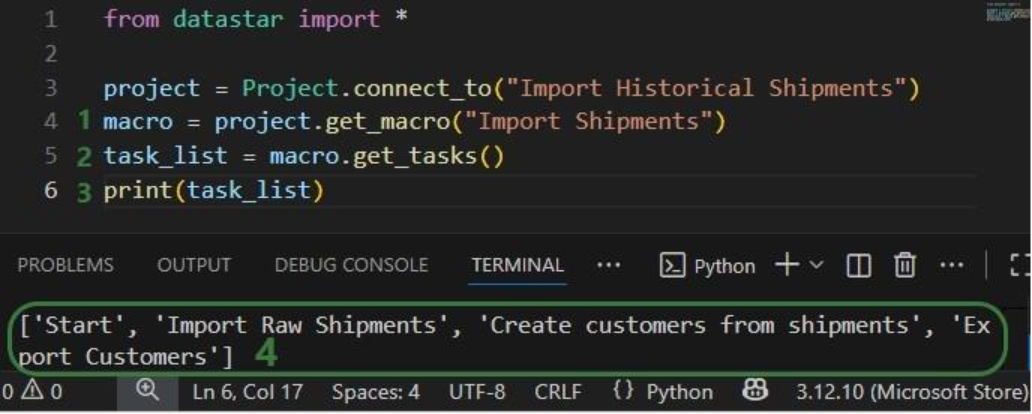
In addition, we can have a quick look in the DataStar application to see that the information we are getting from the small scripts above matches what we have in our account in terms of projects (first screenshot below), and the “Import Shipments” macro plus its tasks in the “Import Historical Shipments” project (second screenshot below):

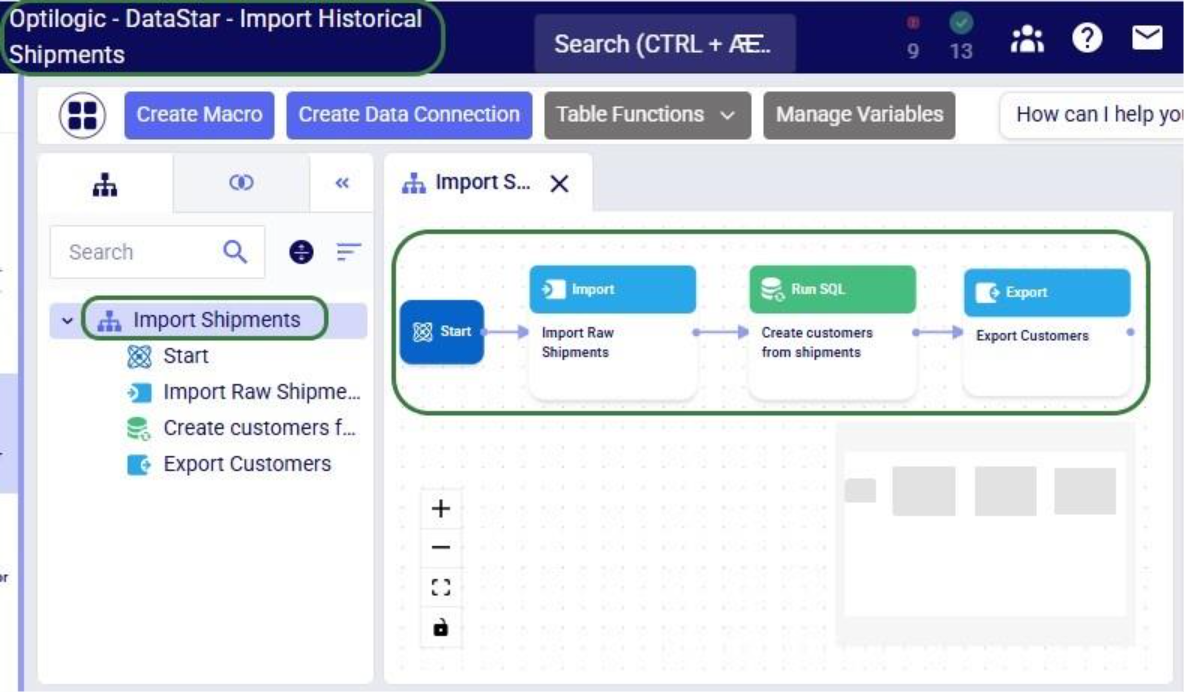
Besides getting information about projects and macros, other useful methods for projects and macros include:
Note that when creating new objects (projects, macros, tasks or connections) these are automatically saved. If existing objects are modified, their changes need to be committed by using the save method.
Macros can be copied, either within the same project or into a different project. Tasks can also be copied, either within the same macro, between macros in the same project, or between macros of different projects. If a task is copied within the same macro, its name will automatically be suffixed with (Copy).
As an example, we will consider a macro called “Cost Data” in a project named “Data Cleansing and Aggregation NA Model”, which is configured as follows:

The North America team shows this macro to their EMEA counterparts who realize that they could use part of this for their purposes, as their transportation cost data has the same format as that of the NA team. Instead of manually creating a new macro with new tasks that duplicate the 3 transportation cost related ones, they decide to use a script where first the whole macro is copied to a new project, and then the 4 tasks which are not relevant for the EMEA team are deleted:

After running the script, we see in DataStar that there is indeed a new project named “Data Cleansing and Aggregation EMEA” which has a “Cost Data EMEA” macro that contains the 3 transportation cost related tasks that we wanted to keep:
Note that another way we could have achieved this would have been to copy the 3 tasks from the macro in the NA project to the new macro in the EMEA project. The next example shows this for one task. Say that after the Cost Data EMEA macro was created, the team finds they also have a use for the “Import General Ledger” task that was deleted as it was not on the list of “tasks to keep”. In an extension of the previous script or a new one, we can leverage the add_task method of the Macro class to copy the “Import General Ledger” task from the NA project to the EMEA one:
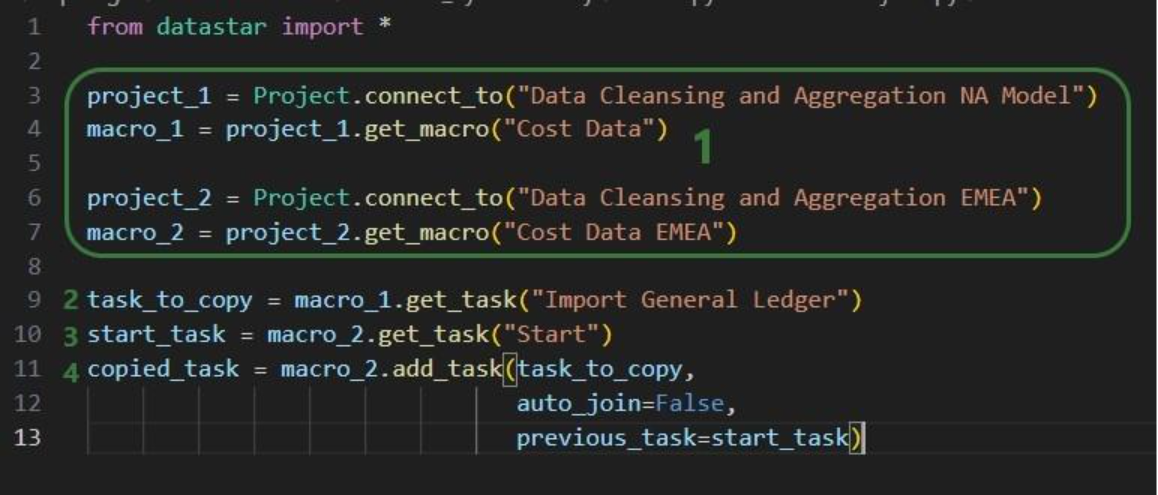
After running the script, we see that the “Import General Ledger” task is now part of the “Cost Data EMEA” macro and is connected to the Start task:
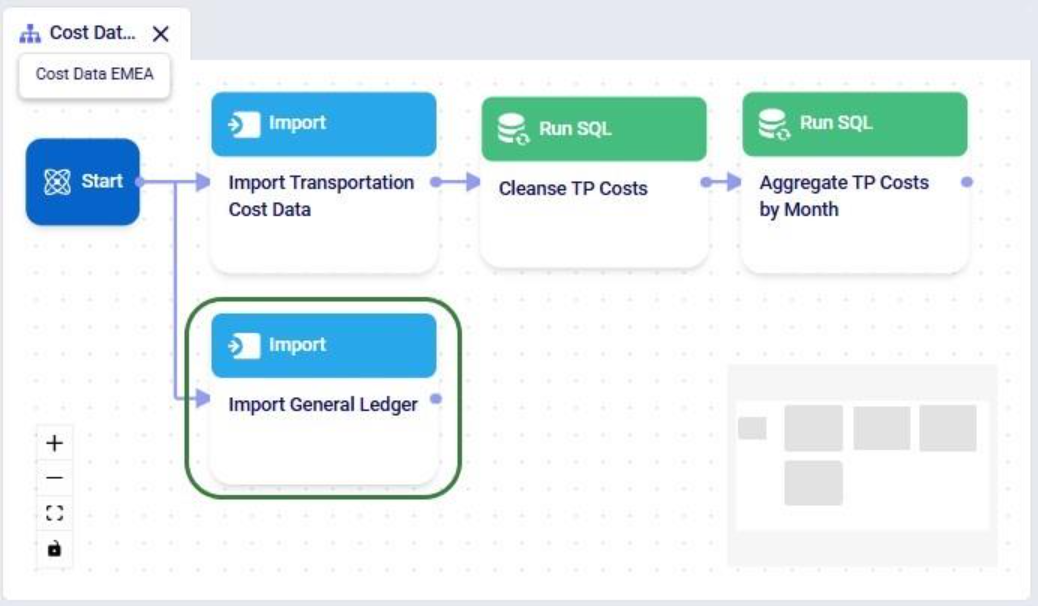
Several additional helpful features on chaining tasks together in a macro are:
DataStar connections allow users to connect to different types of data sources, including CSV-files, Excel files, Cosmic Frog models, and Postgres databases. These data sources need to be present on the Optilogic platform (i.e. visible in the Explorer application). They can then be used as sources / destinations / targets for tasks within DataStar.
We can use scripts to create data connections:
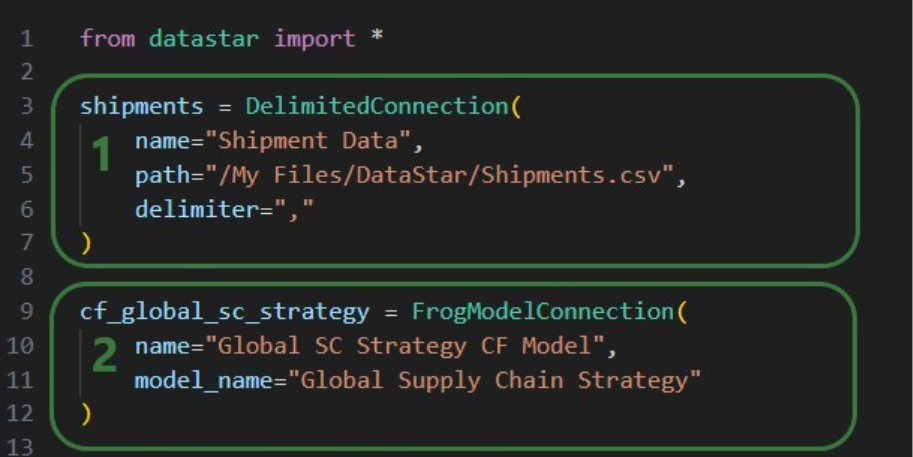
After running this script, we see the connections have been created. In the following screenshot, the Explorer is on the left, and it shows the Cosmic Frog model “Global Supply Chain Strategy.frog” and the Shipments.csv file. The connections using these are listed in the Data Connections tab of DataStar. Since we did not specify any description, an auto-generated description “Created by the Optilogic Datastar library” was added to each of these 2 connections:
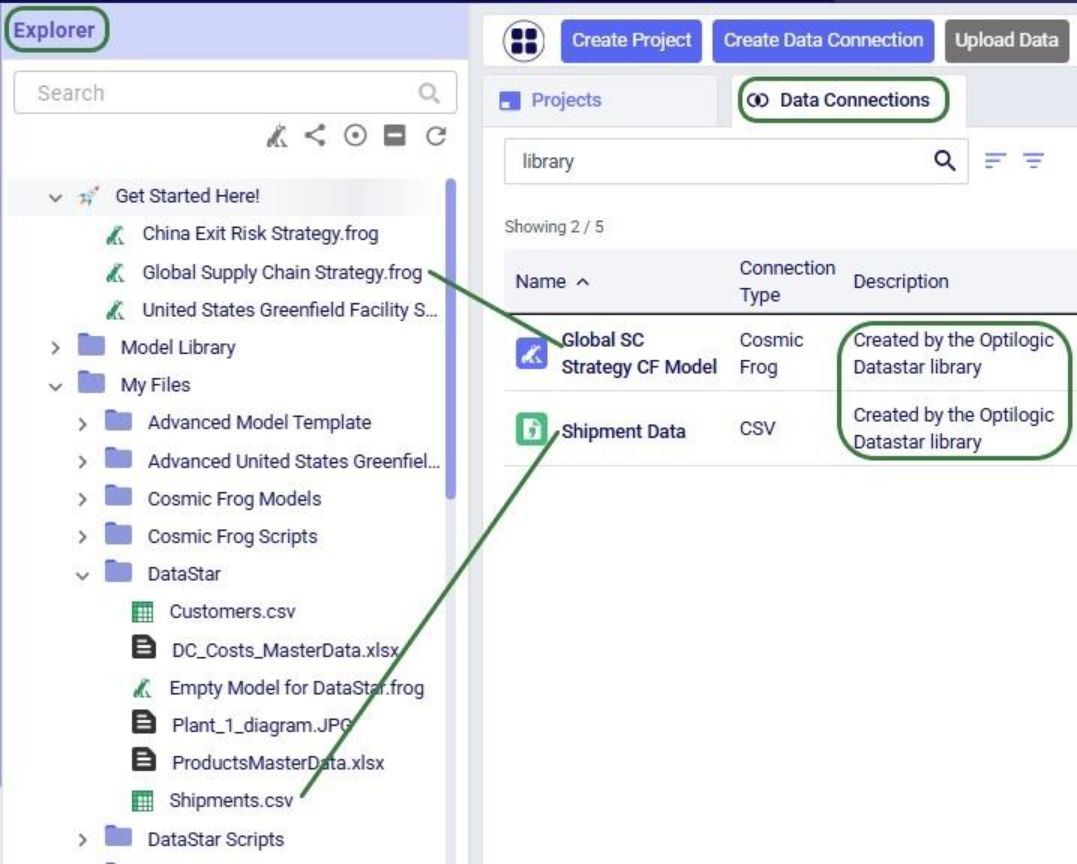
In addition to the connections shown above, data connections to Excel files (.xls and .xlsx) and PostgreSQL databases which are stored on the Optilogic platform can be created too. Use the ExcelConnection and OptiConnection classes to set up such these types of connections up.
Each DataStar project has its own internal data connection, the project sandbox. This is where users perform most of the data transformations after importing data into the sandbox. Using scripts, we can access and modify data in this sandbox directly instead of using tasks in macros to do so. Note that if you have a repeatable data workflow in DataStar which is used periodically to refresh a Cosmic Frog model where you update your data sources and re-run your macros, you need to be mindful of making one-off changes to the project sandbox through a script. When you change data in the sandbox through a script, macros and tasks are not updated to reflect these modifications. When running the data workflow the next time, the results may be different if that change the script made is not made again. If you want to include such changes in your macro, you can add a Run Python task to your macro within DataStar.
Our “Import Historical Shipments” project has a table named customers in its project sandbox:

To make the customers sort in numerical order of their customer number, our goal in the next script is to update the number part of the customer names with left padded 0’s so all numbers consist of 4 digits. And while we are at it, we are also going to replace the “CZ” prefix with a “Cust_” prefix.
First, we will show how to access data in the project sandbox:
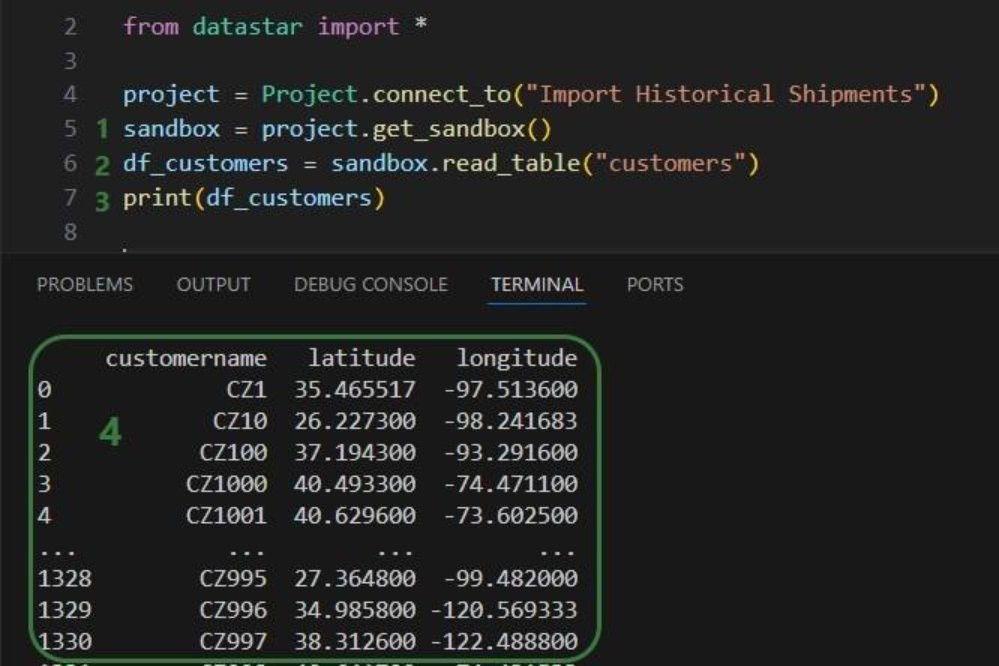
Next, we will use functionality of the pandas Python library (installed as a dependency when installing the datastar library) to transform the customer names to our desired Cust_xxxx format:
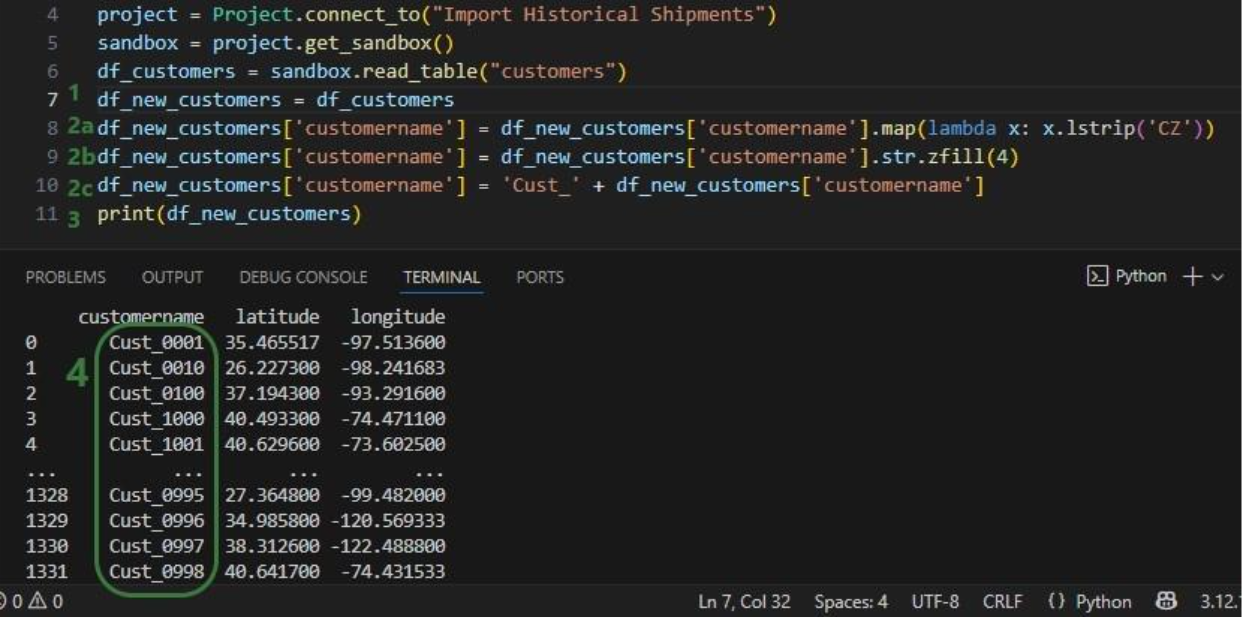
As a last step, we can now write the updated customer names back into the customers table in the sandbox. Or, if we want to preserve the data in the sandbox, we can also write to a new table as is done in the next screenshot:
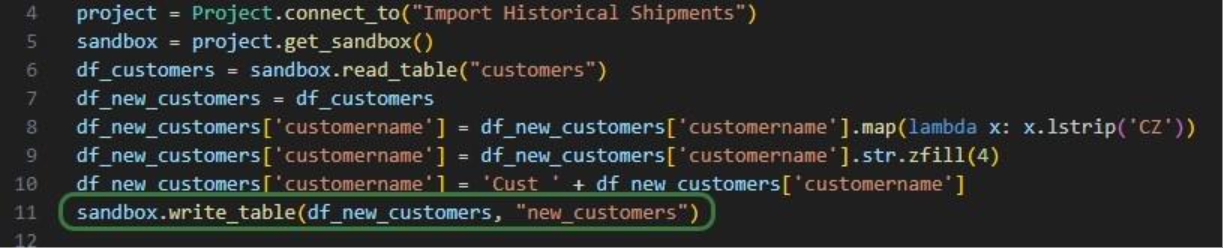
We use the write_table method to write the dataframe with the updated customer names into a new table called “new_customers” in the project sandbox. After running the script, opening this new table in DataStar shows us that the updates worked:
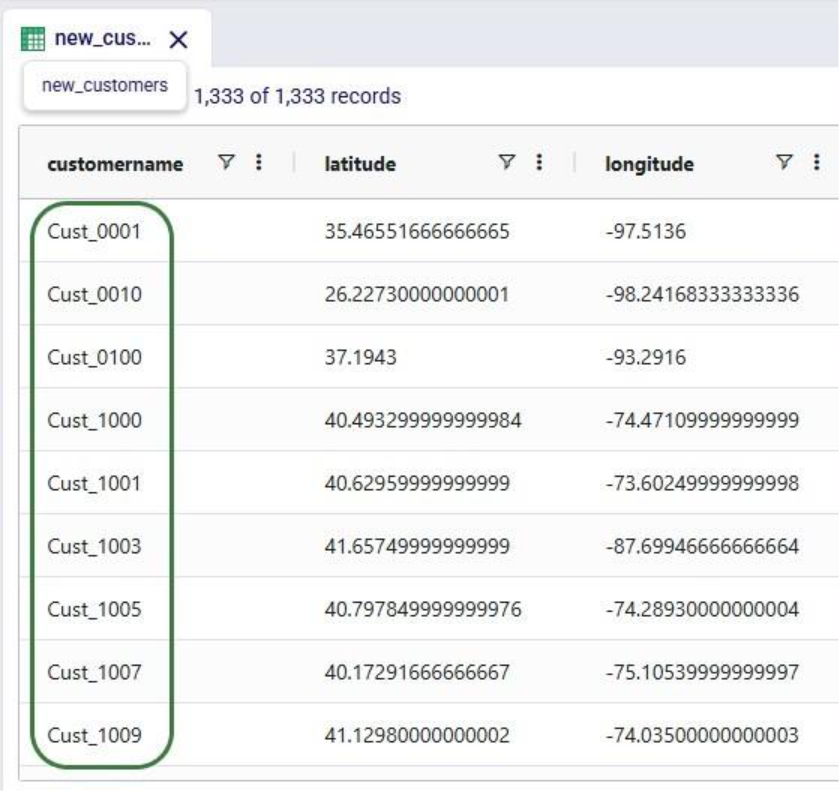
Finally, we will put everything we have covered above together in one script which will:
We will look at this script through the next set of screenshots. For those who would like to run this script themselves, and possibly use it as a starting point to modify into their own script:

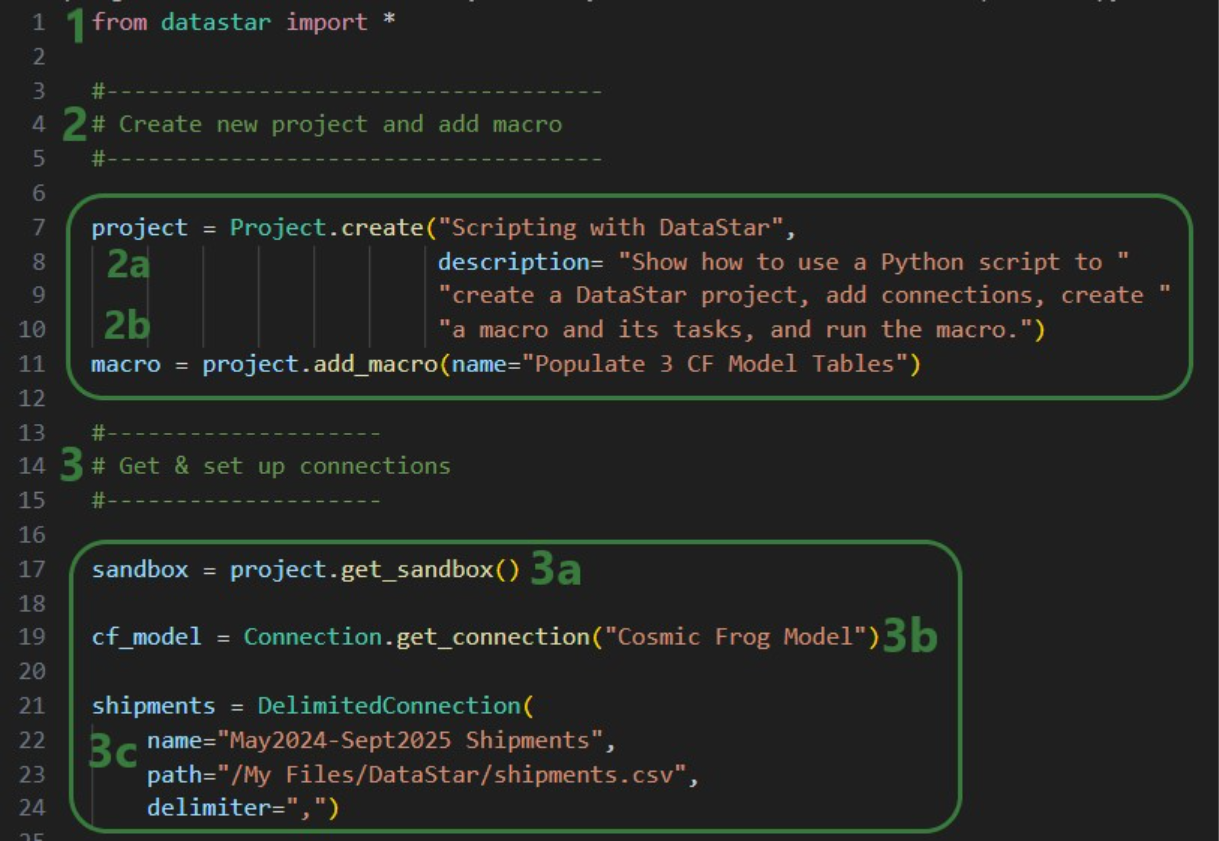
Next, we will create 7 tasks to add to the “Populate 3 CF Model Tables” macro, starting with an Import task:
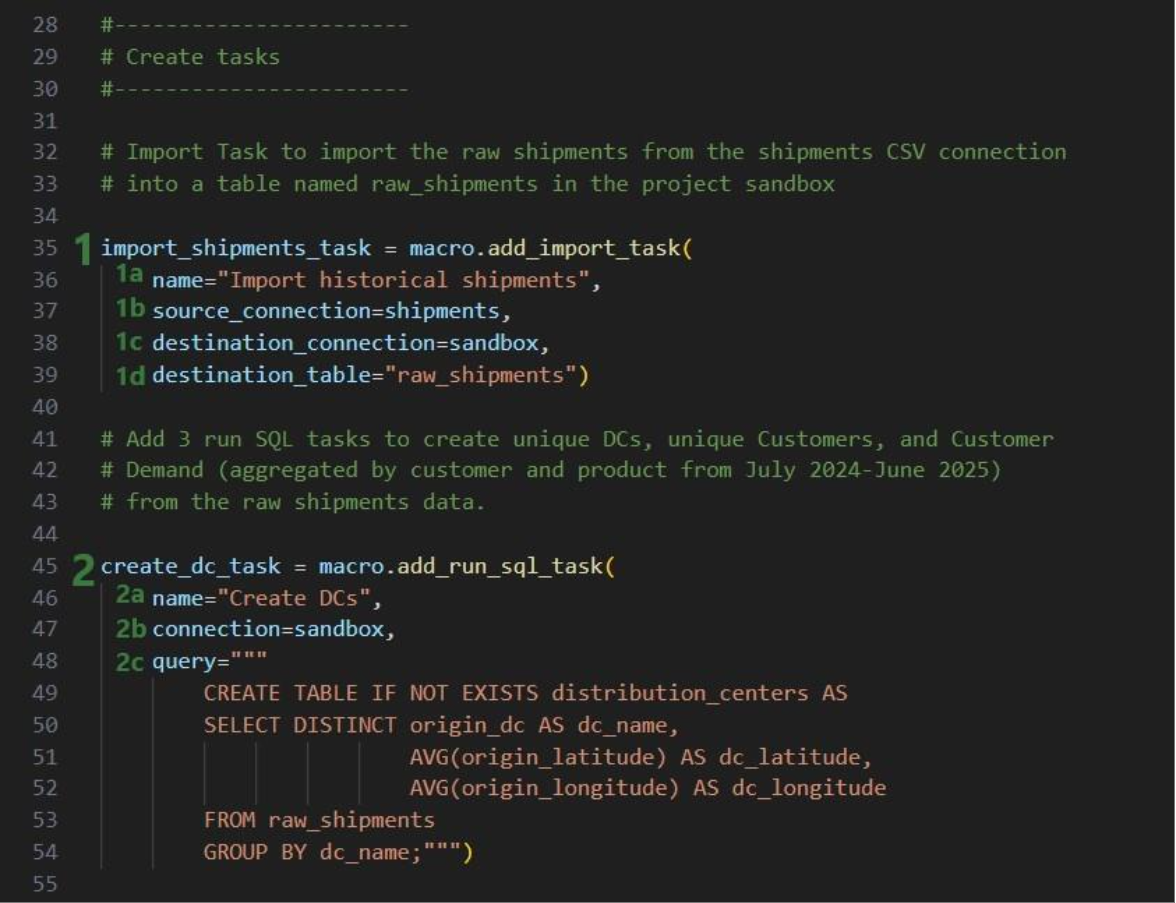
Similar to the “create_dc_task” Run SQL task, 2 more Run SQL tasks are created to create unique customers and aggregated customer demand from the raw_shipments table:
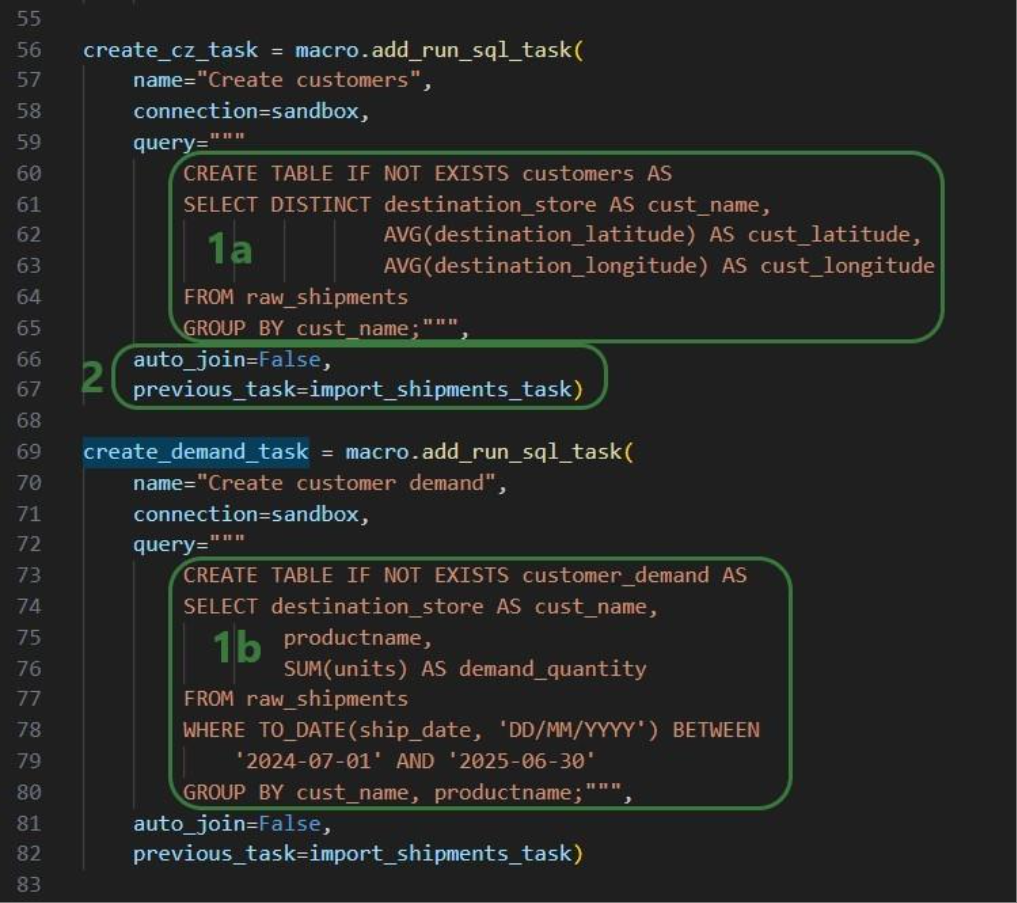
Now that we have generated the distribution_centers, customers, and customer_demand tables in the project sandbox using the 3 SQL Run tasks, we want to export these tables into their corresponding Cosmic Frog tables (facilities, customers, and customerdemand) in the empty Cosmic Frog model:
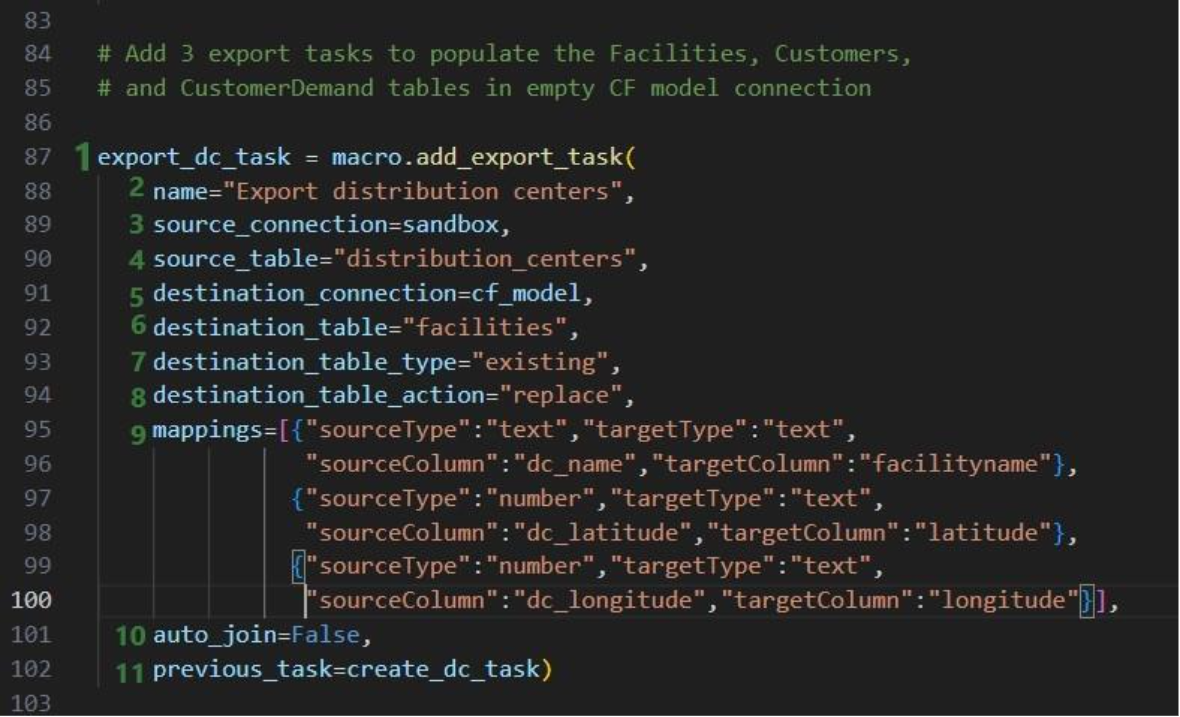
The following 2 Export tasks are created in a very similar way:
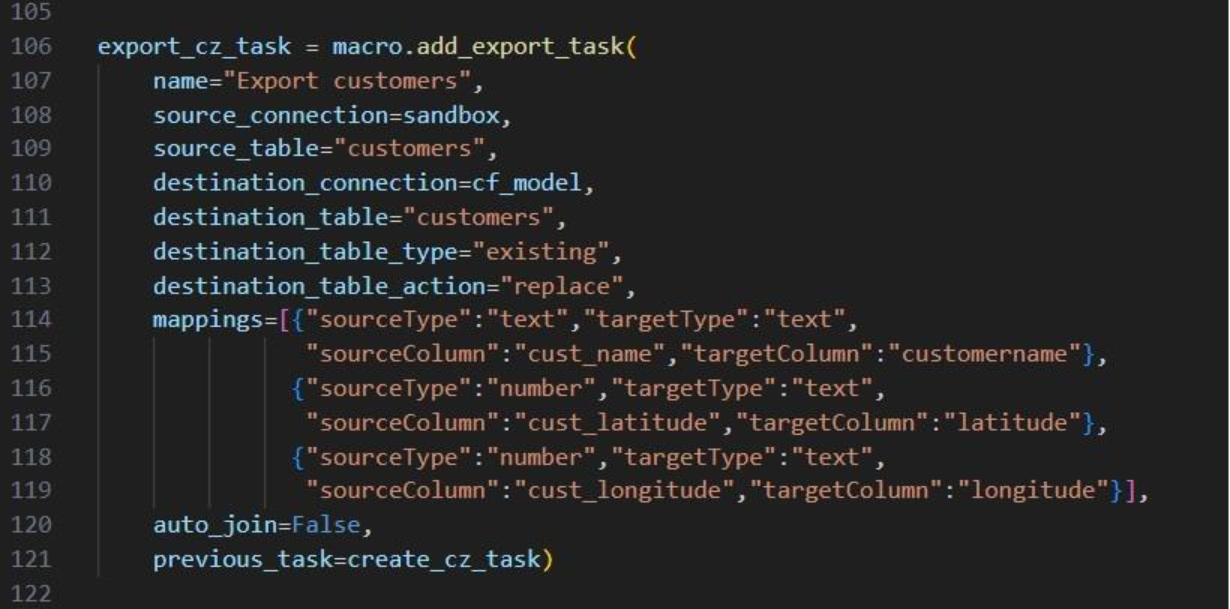
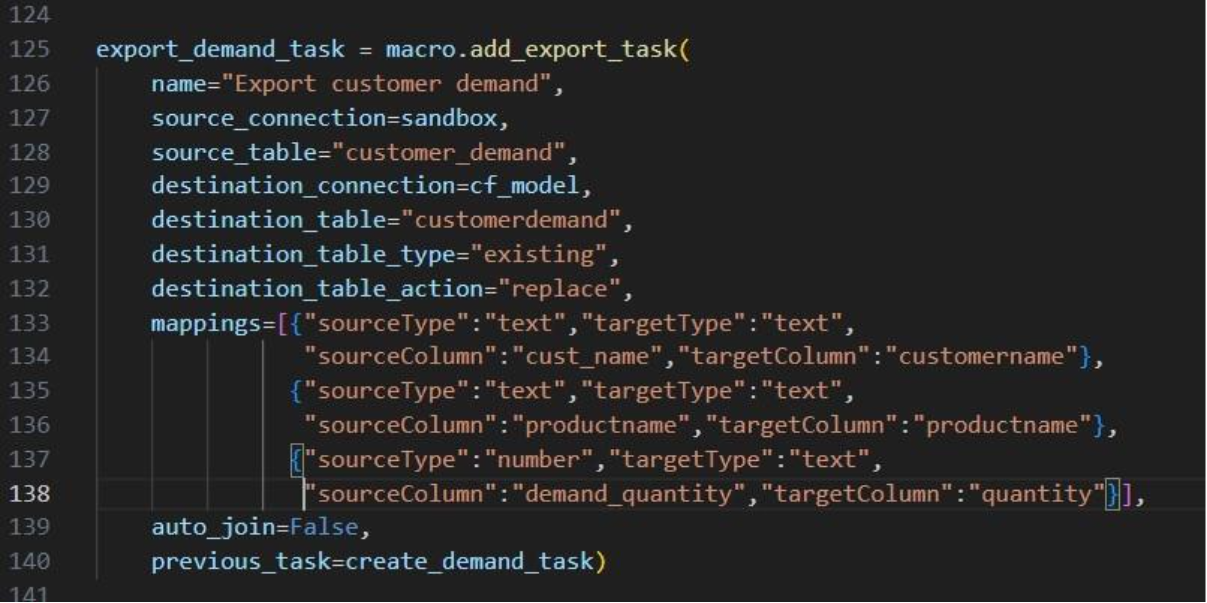
This completes the build of the macro and its tasks.
If we run it like this, the tasks will be chained in the correct way, but they will be displayed on top of each other on the Macro Canvas in DataStar. To arrange them nicely and prevent having to reposition them manually in the DataStar UI, we can use the “x” and “y” properties of tasks. Note that since we are now changing existing objects, we need to use the save method to commit the changes:
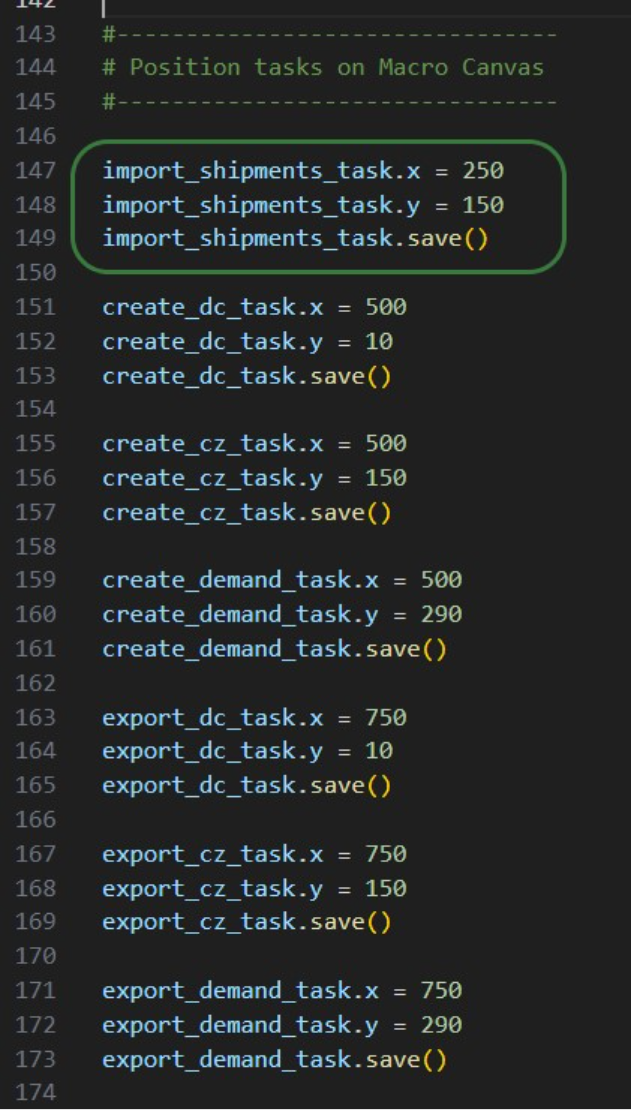
In the green outlined box, we see that the x-coordinate on the Macro Canvas for the import_shipments_task is set to 250 (line 147) and its y-coordinate to 150 (line 148). In line 149 we use the save method to persist these values.
Now we can kick off the macro run and monitor its progress:
While the macro is running, messages written to the terminal by the wait_for_done method will look similar to following:
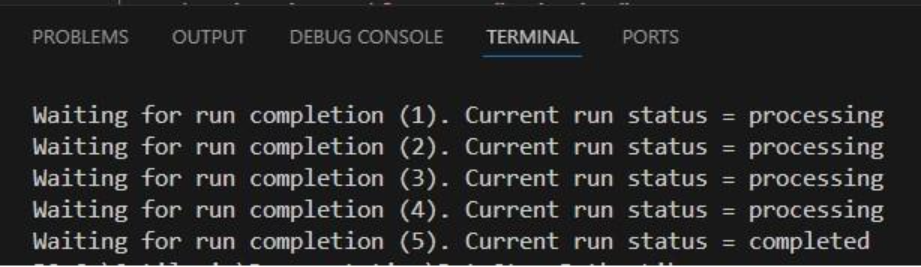
We see 4 messages where the status was “processing” and then a final fifth one stating the macro run has completed. Other statuses one might see are pending when the macro has not yet started and errored in case the macro could not finish successfully.
Opening the DataStar application, we can check the project and CSV connection were created on the DataStar startpage. They are indeed there, and we can open the “Scripting with DataStar” project to check the “Populate 3 CF Model Tables” macro and the results of its run:

The macro contains the 7 tasks we expect and checking their configurations shows they are set up the way we intended to.
Next, we have a look at the Data Connections tab to see the results of running the macro:
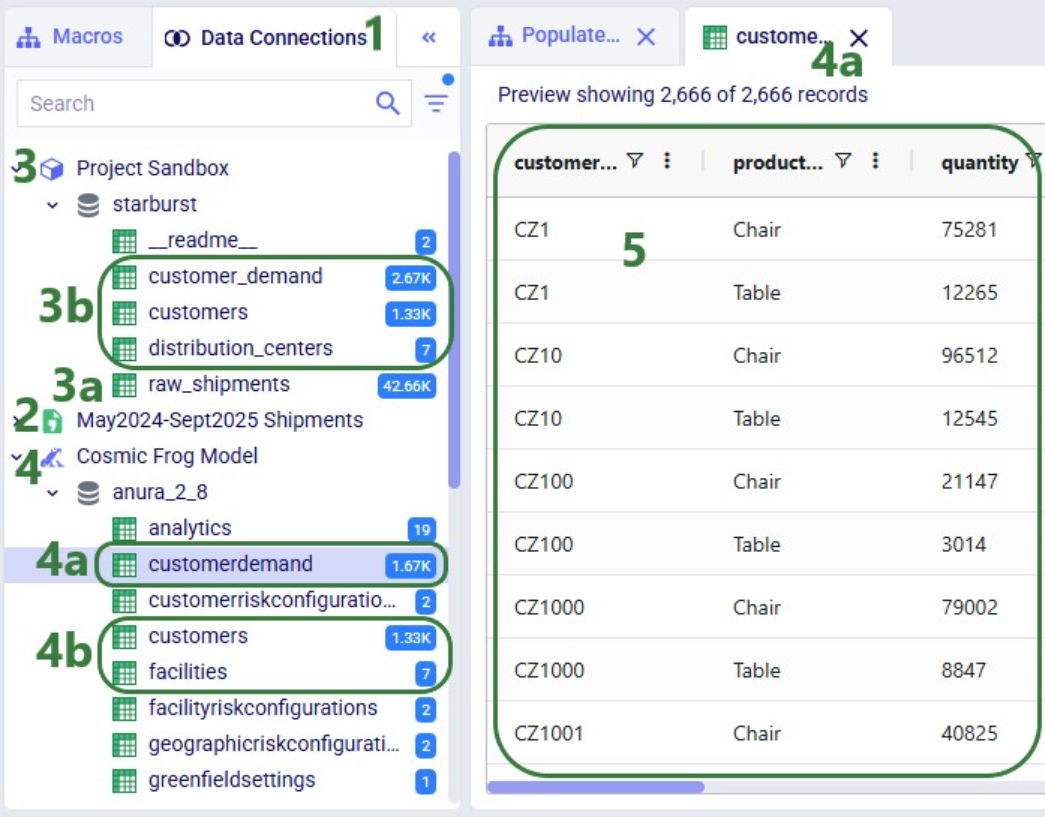
Here follows the code of each of the above examples. You can copy and paste this into your own scripts and modify them to your needs. Note that whenever names and paths are used, you may need to update these to match your own environment.
Get list of DataStar projects in user's Optilogic account and print list to terminal:
from datastar import *
project_list = Project.get_projects()
print(project_list)
Connect to the project named "Import Historical Shipments" and get the list of macros within this project. Print this list to the terminal:
from datastar import *
project = Project.connect_to("Import Historical Shipments")
macro_list = project.get_macros()
print(macro_list)
In the same "Import Historical Shipments" project, get the macro named "Import Shipments", and get the list of tasks within this macro. Print the list with task names to the terminal:
from datastar import *
project = Project.connect_to("Import Historical Shipments")
macro = project.get_macro("Import Shipments")
task_list = macro.get_tasks()
print(task_list)
Copy 3 of the 7 tasks in the "Cost Data" macro in the "Data Cleansing and Aggregation NA Model" project to a new macro "Cost Data EMEA" in a new project "Data Cleansing and Aggregation EMEA". Do this by first copying the whole macro and then removing the tasks that are not required in this new macro:
from datastar import *
# connect to project and get macro to be copied into new project
project = Project.connect_to("Data Cleansing and Aggregation NA Model")
macro = project.get_macro("Cost Data")
# create new project and clone macro into it
new_project = Project.create("Data Cleansing and Aggregation EMEA")
new_macro = macro.clone(new_project,name="Cost Data EMEA",
description="Cloned from NA project; \
keep 3 transportation tasks")
# list the transportation cost related tasks to be kept and get a list
# of tasks present in the copied macro in the new project, so that we
# can determine which tasks to delete
tasks_to_keep = ["Start",
"Import Transportation Cost Data",
"Cleanse TP Costs",
"Aggregate TP Costs by Month"]
tasks_present = new_macro.get_tasks()
# go through tasks present in the new macro and
# delete if the task name is not in the "to keep" list
for task in tasks_present:
if task not in tasks_to_keep:
new_macro.delete_task(task)
Copy specific task "Import General Ledger" from the "Cost Data" macro in the "Data Cleansing and Aggregation NA Model" project to the "Cost Data EMEA" macro in the "Data Cleansing and Aggregation EMEA" project. Chain this copied task to the Start task:
from datastar import *
project_1 = Project.connect_to("Data Cleansing and Aggregation NA Model")
macro_1 = project_1.get_macro("Cost Data")
project_2 = Project.connect_to("Data Cleansing and Aggregation EMEA")
macro_2 = project_2.get_macro("Cost Data EMEA")
task_to_copy = macro_1.get_task("Import General Ledger")
start_task = macro_2.get_task("Start")
copied_task = macro_2.add_task(task_to_copy,
auto_join=False,
previous_task=start_task)
Creating a CSV file connection and a Cosmic Frog Model connection:
from datastar import *
shipments = DelimitedConnection(
name="Shipment Data",
path="/My Files/DataStar/Shipments.csv",
delimiter=","
)
cf_global_sc_strategy = FrogModelConnection(
name="Global SC Strategy CF Model",
model_name="Global Supply Chain Strategy"
)
Connect directly to a project's sandbox, read data into a pandas dataframe, transform it, and write the new dataframe into a new table "new_customers":
from datastar import *
# connect to project and get its sandbox
project = Project.connect_to("Import Historical Shipments")
sandbox = project.get_sandbox()
# use pandas to raed the "customers" table into a dataframe
df_customers = sandbox.read_table("customers")
# copy the dataframe into a new dataframe
df_new_customers = df_customers
# use pandas to change the customername column values format
# from CZ1, CZ20, etc to Cust_0001, Cust_0020, etc
df_new_customers['customername'] = df_new_customers['customername'].map(lambda x: x.lstrip('CZ'))
df_new_customers['customername'] = df_new_customers['customername'].str.zfill(4)
df_new_customers['customername'] = 'Cust_' + df_new_customers['customername']
# write the updates customers table with the new customername
# values to a new table "new_customers"
sandbox.write_table(df_new_customers, "new_customers")
End-to-end script - create a new project and add a new macro to it; add 7 tasks to the macro to import shipments data; create unique customers, unique distribution centers, and demand aggregated by customer and product from it. Then export these 3 tables to a Cosmic Frog model:
from datastar import *
#------------------------------------
# Create new project and add macro
#------------------------------------
project = Project.create("Scripting with DataStar",
description= "Show how to use a Python script to "
"create a DataStar project, add connections, create "
"a macro and its tasks, and run the macro.")
macro = project.add_macro(name="Populate 3 CF Model Tables")
#--------------------
# Get & set up connections
#--------------------
sandbox = project.get_sandbox()
cf_model = Connection.get_connection("Cosmic Frog Model")
shipments = DelimitedConnection(
name="May2024-Sept2025 Shipments",
path="/My Files/DataStar/shipments.csv",
delimiter=",")
#-----------------------
# Create tasks
#-----------------------
# Import Task to import the raw shipments from the shipments CSV connection
# into a table named raw_shipments in the project sandbox
import_shipments_task = macro.add_import_task(
name="Import historical shipments",
source_connection=shipments,
destination_connection=sandbox,
destination_table="raw_shipments")
# Add 3 run SQL tasks to create unique DCs, unique Customers, and Customer
# Demand (aggregated by customer and product from July 2024-June 2025)
# from the raw shipments data.
create_dc_task = macro.add_run_sql_task(
name="Create DCs",
connection=sandbox,
query="""
CREATE TABLE IF NOT EXISTS distribution_centers AS
SELECT DISTINCT origin_dc AS dc_name,
AVG(origin_latitude) AS dc_latitude,
AVG(origin_longitude) AS dc_longitude
FROM raw_shipments
GROUP BY dc_name;""")
create_cz_task = macro.add_run_sql_task(
name="Create customers",
connection=sandbox,
query="""
CREATE TABLE IF NOT EXISTS customers AS
SELECT DISTINCT destination_store AS cust_name,
AVG(destination_latitude) AS cust_latitude,
AVG(destination_longitude) AS cust_longitude
FROM raw_shipments
GROUP BY cust_name;""",
auto_join=False,
previous_task=import_shipments_task)
create_demand_task = macro.add_run_sql_task(
name="Create customer demand",
connection=sandbox,
query="""
CREATE TABLE IF NOT EXISTS customer_demand AS
SELECT destination_store AS cust_name,
productname,
SUM(units) AS demand_quantity
FROM raw_shipments
WHERE TO_DATE(ship_date, 'DD/MM/YYYY') BETWEEN
'2024-07-01' AND '2025-06-30'
GROUP BY cust_name, productname;""",
auto_join=False,
previous_task=import_shipments_task)
# Add 3 export tasks to populate the Facilities, Customers,
# and CustomerDemand tables in empty CF model connection
export_dc_task = macro.add_export_task(
name="Export distribution centers",
source_connection=sandbox,
source_table="distribution_centers",
destination_connection=cf_model,
destination_table="facilities",
destination_table_type="existing",
destination_table_action="replace",
mappings=[{"sourceType":"text","targetType":"text",
"sourceColumn":"dc_name","targetColumn":"facilityname"},
{"sourceType":"number","targetType":"text",
"sourceColumn":"dc_latitude","targetColumn":"latitude"},
{"sourceType":"number","targetType":"text",
"sourceColumn":"dc_longitude","targetColumn":"longitude"}],
auto_join=False,
previous_task=create_dc_task)
export_cz_task = macro.add_export_task(
name="Export customers",
source_connection=sandbox,
source_table="customers",
destination_connection=cf_model,
destination_table="customers",
destination_table_type="existing",
destination_table_action="replace",
mappings=[{"sourceType":"text","targetType":"text",
"sourceColumn":"cust_name","targetColumn":"customername"},
{"sourceType":"number","targetType":"text",
"sourceColumn":"cust_latitude","targetColumn":"latitude"},
{"sourceType":"number","targetType":"text",
"sourceColumn":"cust_longitude","targetColumn":"longitude"}],
auto_join=False,
previous_task=create_cz_task)
export_demand_task = macro.add_export_task(
name="Export customer demand",
source_connection=sandbox,
source_table="customer_demand",
destination_connection=cf_model,
destination_table="customerdemand",
destination_table_type="existing",
destination_table_action="replace",
mappings=[{"sourceType":"text","targetType":"text",
"sourceColumn":"cust_name","targetColumn":"customername"},
{"sourceType":"text","targetType":"text",
"sourceColumn":"productname","targetColumn":"productname"},
{"sourceType":"number","targetType":"text",
"sourceColumn":"demand_quantity","targetColumn":"quantity"}],
auto_join=False,
previous_task=create_demand_task)
#--------------------------------
# Position tasks on Macro Canvas
#--------------------------------
import_shipments_task.x = 250
import_shipments_task.y = 150
import_shipments_task.save()
create_dc_task.x = 500
create_dc_task.y = 10
create_dc_task.save()
create_cz_task.x = 500
create_cz_task.y = 150
create_cz_task.save()
create_demand_task.x = 500
create_demand_task.y = 290
create_demand_task.save()
export_dc_task.x = 750
export_dc_task.y = 10
export_dc_task.save()
export_cz_task.x = 750
export_cz_task.y = 150
export_cz_task.save()
export_demand_task.x = 750
export_demand_task.y = 290
export_demand_task.save()
#-----------------------------------------------------
# Run the macro and write regular progress updates
#-----------------------------------------------------
macro.run()
macro.wait_for_done(verbose=True)Dendro is Optilogic's simulation-optimization engine. A prime use case for Dendro is inventory policy optimization.
Simulation-optimization is a method in which simulation is leveraged to intelligently explore alternative configurations of a system. Dendro accomplishes this data-driven search by layering a genetic algorithm on top of simulation; simulation is the core of a Dendro model. Before a Dendro study can begin, a simulation model (run with the Throg engine) must be built, verified, and validated.
Simulation-optimization enables us to ask and answer questions that we cannot address in traditional network optimization or simulation alone.
In this article, we will explore:
The modeling methods of network optimization (Neo), discrete event simulation (Throg), and simulation-optimization (Dendro) address different supply chain design use cases.
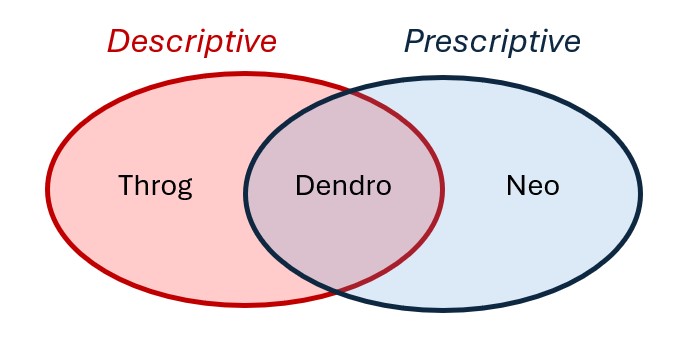
A prime use case for Dendro is inventory policy optimization: right-sizing inventory levels by changing inventory policy parameters (reorder points, reorder quantities, etc.) with the goal of balancing cost and service. Dendro's foundation in simulation minimizes the abstraction of cost accounting, service metrics, and the business rules surrounding inventory management. Dendro provides actionable inventory policy recommendations and data-driven evidence to support those changes.
Primary Focus: Determining where inventory should be positioned across the network.
Use Case: Network design decisions that include high-level inventory considerations -- such as stocking locations, target turns, and working capital trade-offs.
How It Handles Inventory:
Primary Focus: Testing and observing how specific inventory policies perform under realistic operational dynamics.
Use Case: Evaluate inventory control logic (e.g., reorder point, order quantity, order-up-to level) in a time-based simulation environment.
How It Handles Inventory:
Primary Focus: Finding better inventory policies that balance cost and service, combining Throg's simulation accuracy with an optimization engine.
Use Case: Adjust inventory policy parameters (e.g., reorder point, reorder quantity, policy type) to find configurations that deliver the best cost-service trade-offs.
How It Handles Inventory:
While this comparison highlights how each engine contributes to inventory management decisions, the specific use case covered in this article is inventory policy optimization -- using Dendro to balance total inventory carrying cost and network-level customer service (measured as quantity fill rate).
That said, Dendro's capabilities extend far beyond inventory. The same framework of input factors, output factors, and utility functions can be applied to a wide range of optimization problems -- and its utility components are not limited to just cost and service. Dendro can optimize for any measurable performance metric that matters to your business.
As stated above, a Dendro study cannot be initiated without first establishing a Throg simulation model; a Dendro project should be thought of as a simulation project with an added layer of analysis. Careful Throg model verification and validation are part of a simulation project and are therefore a prerequisite for a Dendro study. To learn how to set up a Throg simulation model, we recommend reviewing the following on-demand training content:
In addition, Throg-specific articles can be found here on the Help Center.
Throg scenario results serve as one piece of input for a Dendro run. Identification of the appropriate Throg scenario to apply Dendro to depends on the goal of the Dendro study. The network structure under which the modeler is seeking to optimize inventory policies must be represented in a Throg scenario.

Inventory policies are required to run a simulation scenario. In some cases, a modeler may not have existing inventory policies to utilize in a baseline scenario. Similarly, simulating a proposed network structure requires first setting inventory policies for new site-product combinations. To set policies, we recommend utilizing the Demand Classification utility in Cosmic Frog's Utilities module.
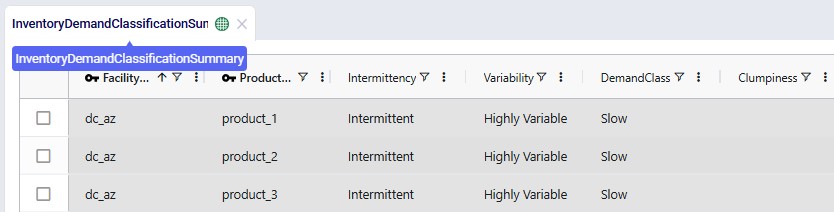

Suggested inventory policies from the Inventory Policy Data Summary output table can then be employed in the Inventory Policies input table. For the sake of testing while the Throg model is being built and verified, users may find it helpful to initially leverage simple placeholder inventory policies where policies are unknown or not yet in existence (e.g., (s,S) = (0,0)).
Note: if the modeler's goal is to set policies for a proposed network structure, it is recommended to first optimize Baseline inventory policies. This enables the modeler to compare potential performance of the existing network structure (i.e., performance under optimized policies) with performance of the proposed network structure. This is especially encouraged if the Demand Classification utility was used to set Baseline inventory policies.
Before running Dendro to optimize inventory policies, the modeler must consider
The answers to these questions will inform the design of Dendro model inputs.
Every Dendro optimization begins with a well-defined model foundation and input configuration.
This configuration tells Dendro three essential things:
Together, these define the search space and fitness criteria that drive optimization.
Dendro builds directly on your validated Throg simulation model, which serves as the environment for its optimization runs.
All Throg input tables -- facilities, customers, products, and policies -- are carried into Dendro.
For inventory-focused optimizations, the Inventory Policies input table is most critical.
It defines policy types and parameters such as reorder points and order-up-to levels. These become natural candidates for Dendro input factors.
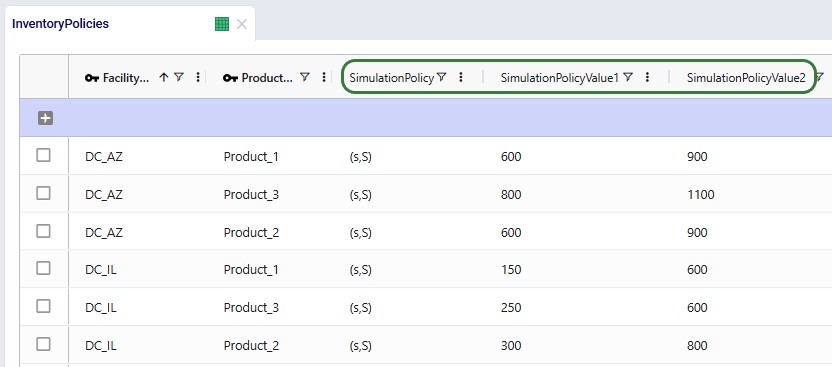
The Input Factors input table tells Dendro which parameters it can adjust during optimization. Each input factor represents a decision lever -- for instance, a reorder point or a policy type -- that Dendro will tune to seek better outcomes.

The search space defines both the breadth (how wide Dendro can explore) and the granularity (how detailed the exploration is).
The goal is a "computationally tractable search space" -- broad enough for Dendro to discover impactful alternatives but focused enough to identify patterns efficiently.
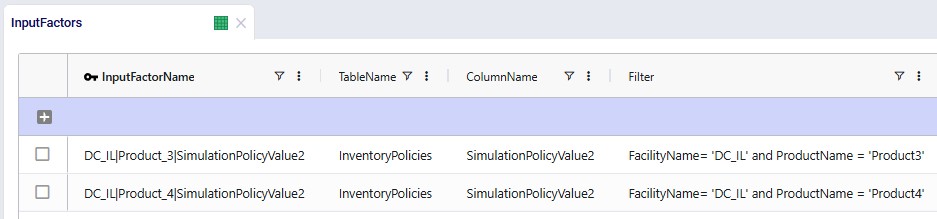

Learn all about input factors in the "Dendro: Input Factors Guide".
Once Dendro knows what it can vary, it needs to know how to judge success. The Output Factors input table defines the KPIs Dendro will use to evaluate each scenario and how they are scored.
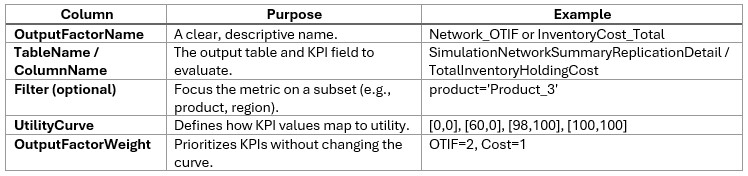
Utility curves express your business preferences:
Examples:
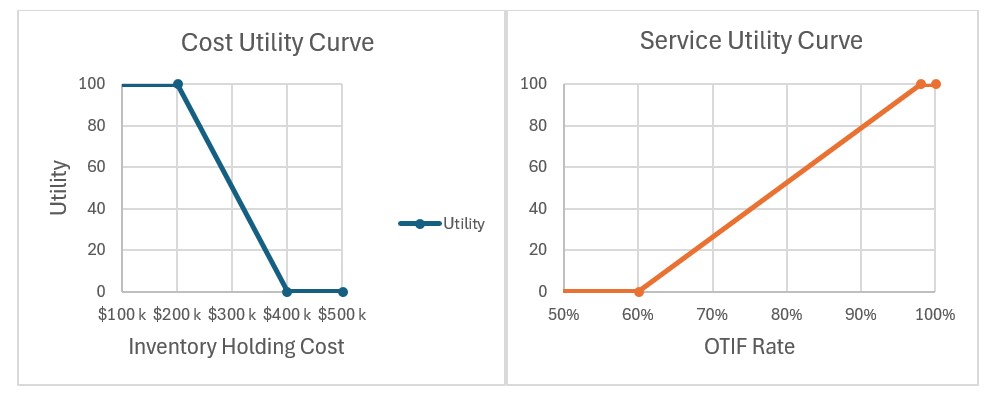
Tip: Curves should span the expected simulation range (e.g., 5th-95th percentile of early results). Dendro will stretch the utility curves if results fall outside the range, which can distort scoring.
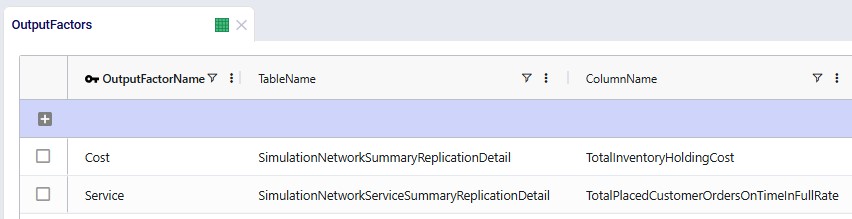
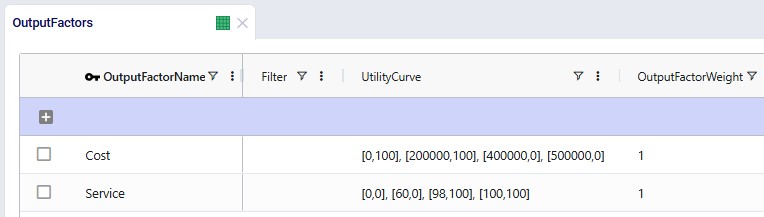
Weights dictate how much influence each KPI has in Dendro's overall fitness score calculation.
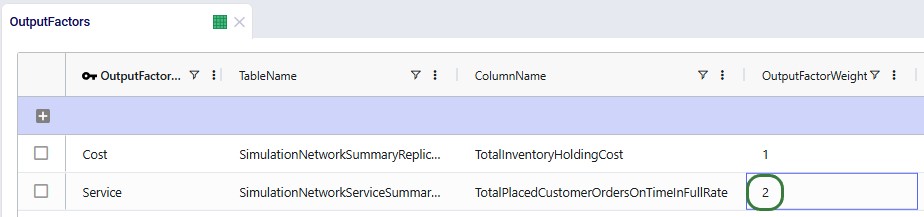
Learn more about output factors in the "Dendro: Output Factors Guide".
A well-scoped input configuration defines the playing field for Dendro's optimization.
By combining realistic input ranges, balanced KPI scoring, and robust run settings, you enable Dendro to explore intelligently finding high-performing, data-backed configurations without unnecessary computation.
Dendro is built to explore a wide range of supply chain configurations using your verified and validated Throg simulation scenario(s) as the base. Running a Dendro job is straightforward, but there are a few important steps and best practices to keep in mind to ensure smooth operation.
To get started:
INSERT INTO anura_2_8.modelrunoptions (
datatype,
description,
option,
status,
technology,
uidisplaycategory,
uidisplayname,
uidisplayorder,
uidisplaysubcategory,
value)
VALUES (
'double',
'Time limit (seconds) on individual Dendro scenarios',
'DendroTimeout',
'Include',
'[DENDRO]',
'Basic',
'Dendro Timeout',
'',
'',
'3600');
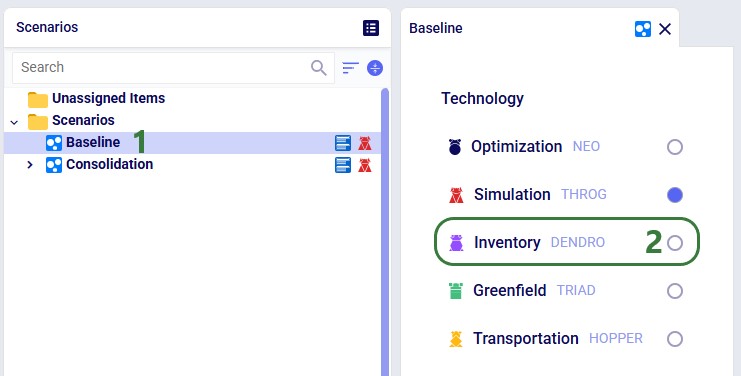
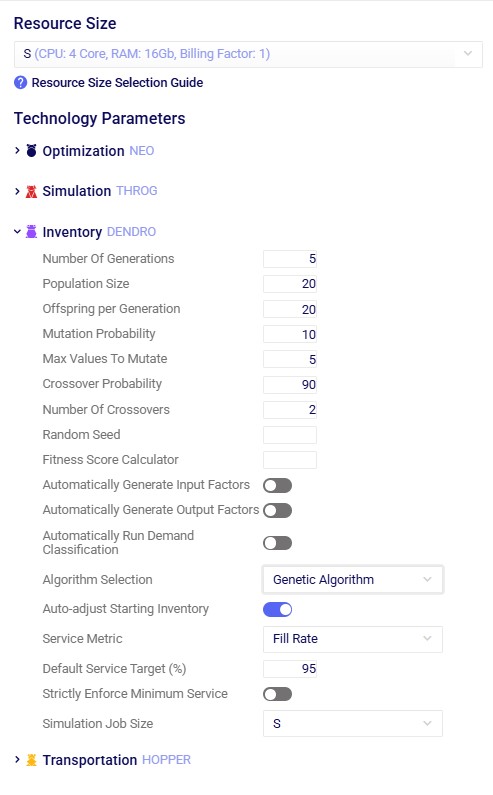
The technology parameters define how Dendro explores the solution space -- including how many scenarios to generate, how they evolve, and how long each simulation may run. As mentioned above, the default values are typically sufficient for a first run. The following are the main parameters that users may want to update in case their defaults are not suitable.
Key Settings
See also more detailed explanations of all Dendro technology parameters here.
Tuning Guidance
Use these principles to fine-tune your technology parameters:
In the course of a Dendro run, the system launches many scenarios for each generation. This is the expected behavior for the genetic algorithm.
Key tips for tracking progress:
Running Dendro is as simple as selecting the engine and starting from a validated Throg model. From there, you can monitor progress, let the algorithm evolve scenarios, and apply best practices for canceling or troubleshooting runs. By following these guidelines, you ensure that Dendro can efficiently search for high-performing supply chain configurations.
To understand how the Dendro genetic algorithm works in detail, please see "Dendro: Genetic Algorithm Guide".
When a Dendro run completes, it produces a rich set of outputs that capture the results of the genetic algorithm's search. These outputs represent the different supply chain configurations that were explored, along with how each one performed according to the objectives you defined (e.g., cost, service level, or a balance of both).
Rather than giving you a single "right" answer, Dendro presents a spectrum of high-performing options. As the modeler, you use these results to evaluate trade-offs and select the scenarios that best align with your business goals.
During a run, Dendro evaluates each candidate scenario by:
Dendro records the input factors and output factors of every scenario it evaluates. However, only the top 20 highest-performing scenarios are saved as named scenarios in your model, making them easier to access and reuse.
After the run, the top 20 scenarios are automatically saved in your model. These represent the best balances of trade-offs Dendro discovered within your defined search space.
Each scenario has an overall fitness score, calculated as the weighted sum of its output factor utility values. A higher score means the scenario performed well according to the priorities you set (e.g., balancing low cost with high service).
Tip: The "best" scenario numerically may not always be the most practical operationally. Always interpret results in context.
Where to Find Key Results
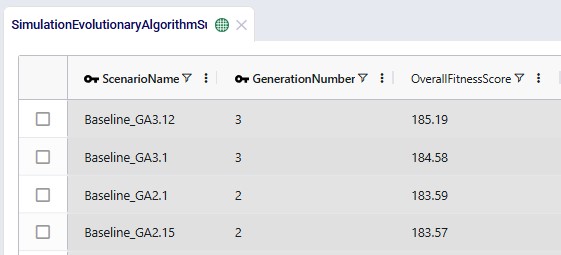
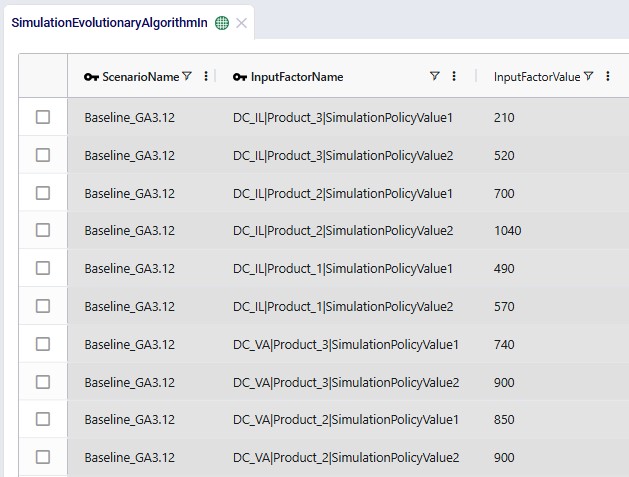

Tips for Reviewing Results
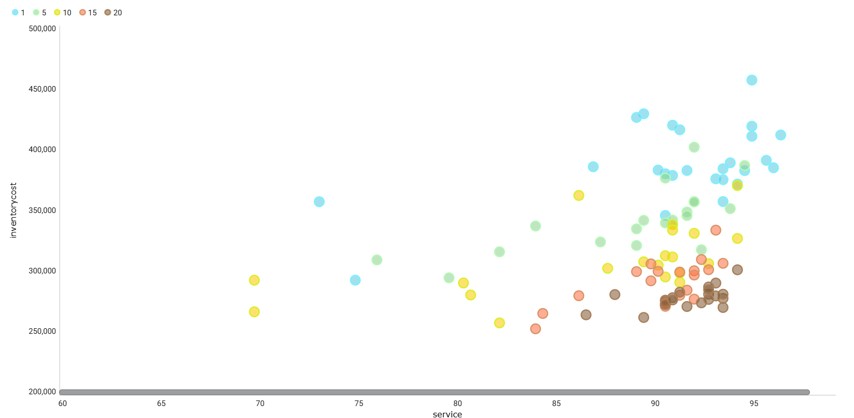
Dendro generates raw scenario outputs, but actionable recommendations come from your interpretation in the context of business goals.
In summary, Dendro does not hand you a single answer, it gives you a portfolio of high-performing options. By interpreting these scenarios in context, you can make informed decisions, balance trade-offs, and run deeper simulations where needed to guide your supply chain strategy.
You may find these links helpful, some of which have already been mentioned above:
As always, please feel free to reach out to the Optilogic Support team at support@optilogic.com in case of questions or feedback.
Dendro, Optilogic’s simulation-optimization engine, uses a sophisticated Genetic Algorithm (GA) to, for example, optimize inventory policies across your supply chain network. This guide explains how the algorithm works in business-friendly terms, helping you understand what happens when you run Dendro and how to get the best results.
The Big Picture: Dendro's Genetic Algorithm explores thousands of different inventory policy combinations, simulates each one to see how it performs, and gradually evolves toward the best possible solution - much like natural evolution produces better-adapted organisms over time.
Recommended reading prior to diving into this guide: Getting Started with Dendro, which is a higher-level overview of how Dendro works.
Genetic Algorithms are inspired by biological evolution. Just as species evolve to become better adapted to their environment through:
Dendro evolves inventory policies to become better adapted to your business objectives through:
Traditional optimization methods struggle with inventory networks due to:
Genetic Algorithms excel at this type of problem because they:
Dendro's implementation uses three fundamental elements: chromosomes, genes, and fitness score.
A chromosome represents one complete set of inventory policies for your entire supply chain.
Example Chromosome:
Each chromosome is essentially a complete "proposal" for how to manage inventory across your network.
Each gene within a chromosome represents the policy for one facility-product combination.
Example Gene:
Genes can mutate (change their values) to explore different policy settings.
The fitness score measures how good a chromosome is - combining costs, service levels, and other objectives.
Higher scores are better - Dendro displays scores where better solutions have higher values.
A fitness score might combine:
Whenever the below refers to an option, this is a model run option that can be set in the Dendro section of the Technology Parameters on the right-hand side of the Run Settings screen that comes up after a user clicks on the green Run button in Cosmic Frog.
What happens: Dendro creates the initial population of chromosomes (policy combinations).
Implementation details:
Business perspective: Think of this as Dendro assembling a diverse team of proposals. The first proposal is "keep doing what we are doing", while the others explore variations like "increase safety stock by 10%", "reduce order quantities", etc.
Each generation follows the same four-step cycle:
What happens: Each chromosome is evaluated by:
Implementation details:
Business perspective: Dendro tests each proposal by running it through a realistic simulation of your supply chain over time. It is like running a pilot program for each policy combination to see what would actually happen - but virtually, so you can test thousands of options without risk.
Typical duration:
What happens: Dendro ranks all chromosomes by fitness score and selects the best ones to continue to the next generation.
Implementation details:
Business perspective: After testing all proposals, Dendro keeps the most promising ones and discards the poor performers. This is like a review committee keeping the best ideas and dropping the ones that do not work well.
Example:
Generation 5 Results (20 chromosomes evaluated):
What happens: Dendro creates new chromosomes by combining parts of two successful parent chromosomes.
Implementation details:
Business perspective: Dendro creates new proposals by combining the best parts of successful proposals. If one policy set works well for East Coast facilities and another works well for high-volume products, crossover might create a policy that combines both successful approaches.
Example with 1-Point Crossover:
Parent 1: [Gene_A1, Gene_A2, Gene_A3, Gene_A4, Gene_A5]
Parent 2: [Gene_B1, Gene_B2, Gene_B3, Gene_B4, Gene_B5]
↑ Crossover point
Offspring 1: [Gene_A1, Gene_A2, Gene_A3 | Gene_B4, Gene_B5]
Offspring 2: [Gene_B1, Gene_B2, Gene_B3 | Gene_A4, Gene_A5]
When crossover is most effective:
What happens: Dendro randomly adjusts policy values in the new chromosomes to explore variations.
Implementation details:
Business perspective: Dendro introduces controlled randomness to explore new options. Even the best current policies might not be optimal, so mutation ensures the algorithm does not get stuck. It is like saying "this policy works well at 500 units, but let's try 525 and 475 too".
Example mutations:
Original Gene: Reorder Point = 500, Order-Up-To = 1000
Mutated Gene: Reorder Point = 525, Order-Up-To = 1050
Mutation strategies:
Input factors define what Dendro can change. They are the "variables" in your optimization problem. They can be specified in the Input Factors input table in your Cosmic Frog model.
Common input factors:
How they work in chromosomes: Each input factor becomes a position in the chromosome. Dendro explores different values for each position.
Example: If you have 50 facility-product combinations to optimize, and each has two policy values (reorder point and order-up-to), your chromosome has 50 genes, each with 2 values = 100 total parameters being optimized.
Input factors are covered in detail in the Dendro: Input Factors Guide.
The following 2 screenshots show 6 records in an Input Factors input table in Cosmic Frog. Both simulation policy values for Product_1 at 3 different DCs are specified in these records:
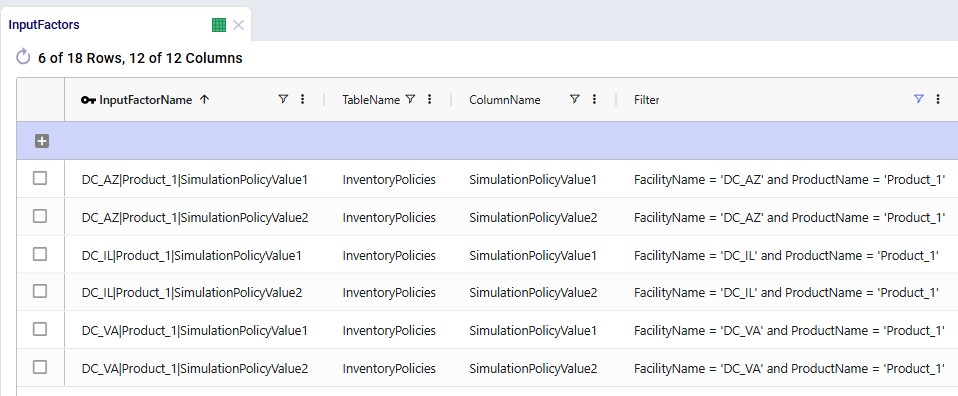
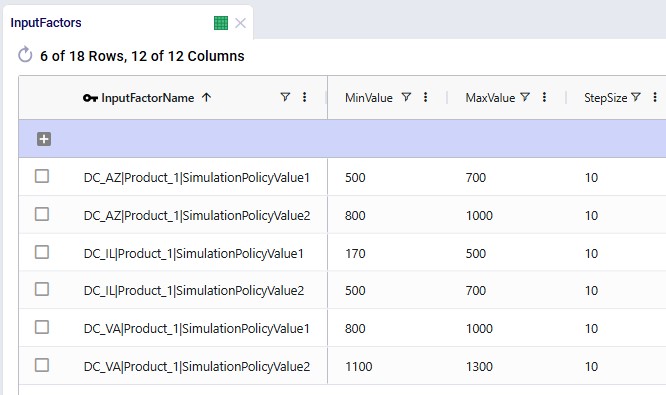
Output factors define what Dendro tries to minimize. They are the "objectives" in your optimization problem. Output factors can be set in the Output Factors input table.
Common output factors:
How they combine - each output factor has a:
The Dendro: Output Factors Guide covers output factors in more detail.
The following screenshot shows an output factors table containing 2 output factors, one measuring service and the other cost:
Utility curves convert simulation outputs into comparable fitness scores.
Why we need them:
How they work:
Example:
Holding Cost Utility Curve:
Business benefit: Utility curves let you define what "good" and "bad" mean for each metric. They translate apples-and-oranges metrics into a single comparable score.
The overall fitness score is the weighted sum of all output factors.
Formula:
Fitness Score = Σ(Weighted Score for each Output Factor)
Where for each factor:
Weighted Score = (Normalized Score from Utility Curve) × (Factor Weight)
Higher is better - Better solutions receive higher fitness scores.
Example calculation:
Output Factors:
1. Holding Cost: $75,000 → Raw Score 75 → Weighted 22.5 (weight 30%)
2. Transport Cost: $40,000 → Raw Score 60 → Weighted 15.0 (weight 25%)
3. Stockout Penalty: $10,000 → Raw Score 80 → Weighted 20.0 (weight 25%)
4. Service Level: 96% → Raw Score 90 → Weighted 18.0 (weight 20%)
Overall Fitness = 22.5 + 15.0 + 20.0 + 18.0 = 75.5 points
Important note: Scores are recalculated when new min/max values are discovered to ensure fair comparison across all generations.
After a Dendro run completes, the fitness scores of all scenarios (=chromosomes) of all generations can be found in the Simulation Evolutionary Algorithm Summary output table (showing the top 10 records here with the highest overall fitness scores):
The challenge: Early in the optimization, Dendro does not know what the best and worst possible values are for each metric. As it explores, it might find:
The solution: Dendro dynamically rescales utility curves when new extremes are discovered.
What happens:
Business perspective: This ensures that a solution that looked "good" in Generation 2 is not unfairly favored if better solutions are discovered later. Everyone is judged by the same standard.
Keeping the best results:
Small population, many generations:
Characteristics:
Large population, fewer generations:
Characteristics:
Balanced approach (recommended):
High mutation (100% probability):
Low mutation (30-50% probability):
Single-point crossover (default):
Points To Crossover = 1
Multi-point crossover:
Points To Crossover = 2 or more
When to disable crossover:
Key indicators of healthy optimization:
The Simulation Evolutionary Algorithm Summary output table can be used to assess the above 2 points as it contains the fitness scores of all scenarios (=chromosomes) that were run for all generations. See an example screenshot of this table further above in the Fitness Score Calculation section.
This last point can be assessed by reviewing the logs of the base scenario used for the Dendro run.
Logging output: Dendro logs key events. These can be found in the Run Manager application, which is another application on the Optilogic platform. The Job Log of the base scenario that Dendro is run on contains quite a lot of detailed on events, such as:
This screenshot shows part of a Job Log for a Dendro run:
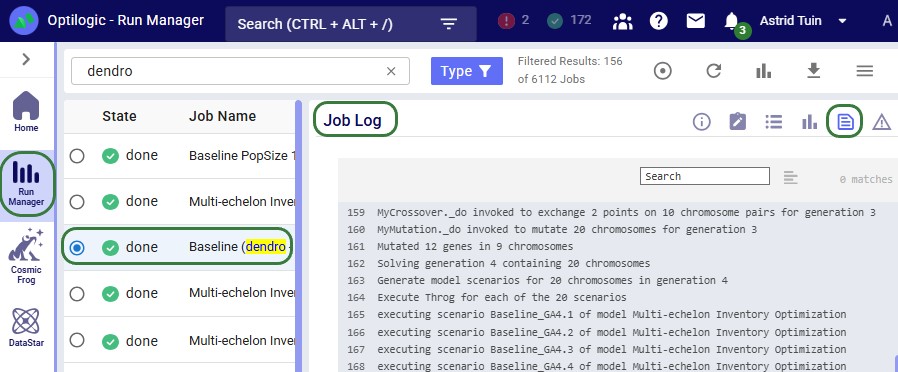
The Job Records log, which can be accessed by clicking on the second icon in the row of icons at the top right of the logs provides a higher level summary of the Dendro run, just calling out the main events:
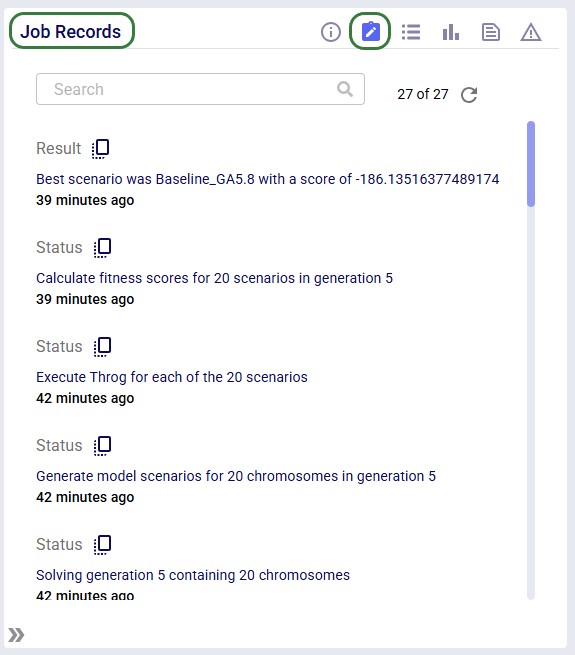
The GA excels in following situations:
The mechanism: Dendro automatically detects and eliminates duplicate chromosomes.
How it works:
Business benefit: Ensures computational resources are used efficiently - never simulating the same policy combination twice.
Challenge: Each chromosome generates a simulation scenario with potentially gigabytes of output data.
Solution:
Business benefit: You can analyze the best solutions in detail without storing data for thousands of unsuccessful experiments.
Network:
Configuration:
Process:
Generation 1:
Generations 2-10:
Generations 11-15:
Generations 16-20:
Results:
Dendro's Genetic Algorithm is a powerful, flexible optimization engine that:
By understanding how the algorithm works, you can:
The GA is not magic – it is a systematic, intelligent search process. Like any tool, it works best when used thoughtfully and configured appropriately for your specific situation.
You may find these links helpful, some of which have already been mentioned above:
Please do not hesitate to contact the Optilogic Support team on support@optilogic.com for any questions or feedback.
Input factors are at the heart of Dendro optimization - they define what Dendro can change to improve your supply chain performance. Think of input factors as the "knobs" Dendro can turn to find better inventory policies.
Key concepts:
This guide explains how to configure input factors to give Dendro the right level of control over your inventory policies. These can be specified in the Input Factors input table in Cosmic Frog.
Recommended reading prior to diving into this guide: Getting Started with Dendro, a high-level overview of how Dendro works, and Dendro: Genetic Algorithm Guide which explains the inner workings of Dendro in more detail.
An input factor tells Dendro's Genetic Algorithm:
Dendro explores these decisions systematically across your entire network to find the optimal combination.
Dendro supports three types of input factors, each suited for different kinds of optimization variables. These are all specified on the Input Factors input table, see also "The Input Factors Table" section further below.
What they are: Numeric values that can vary within a minimum and maximum range.
Best for:
Configuration fields:
InputFactorName: WH_A_Prod_1_ReorderPoint TableName: InventoryPolicies ColumnName: SimulationPolicyValue1 Filter: FacilityName='Warehouse A' AND ProductName='Product 1' MinValue: 100 MaxValue: 1000 StepSize: 10 BaseValue: 500 How it works:
Example:
Chromosome 1 (baseline): 500 Chromosome 2 (random): 730 Chromosome 3 (random): 220 Chromosome 4 (mutated from 2): 740 (increased by one step) What they are: Values selected from a predefined list of discrete options.
Best for:
Configuration fields:
InputFactorName: DC_Policy_Type TableName: InventoryPolicies ColumnName: SimulationPolicy Filter: FacilityName='Distribution Center' Enumerate: (s,S)|(R,Q)|(T,S) BaseValue: (s,S) How it works:
Example:
Chromosome 1 (baseline): (s,S) Chromosome 2 (random): (R,Q) Chromosome 3 (random): (T,S) Chromosome 4 (mutated from 2): (s,S) (switched from R,Q) What they are: Grouped input factors that manage related inventory policy parameters together as a coordinated set.
Best for:
How they work:
Example configuration:
Factor 1: InputFactorName: WH_A_Prod_1_PolicyType TableName: InventoryPolicies ColumnName: SimulationPolicy Filter: FacilityName='Warehouse A' AND ProductName='Product 1' Enumerate: (s,S)|(R,Q) Factor 2: InputFactorName: WH_A_Prod_1_Value1 TableName: InventoryPolicies ColumnName: SimulationPolicyValue1 Filter: FacilityName='Warehouse A' AND ProductName='Product 1' MinValue: 0 MaxValue: 1000 StepSize: 10 Factor 3: InputFactorName: WH_A_Prod_1_Value2 TableName: InventoryPolicies ColumnName: SimulationPolicyValue2 Filter: FacilityName='Warehouse A' AND ProductName='Product 1' MinValue: 0 MaxValue: 1500 StepSize: 10 Automatic policy conversion: When policy type changes from (R,Q) to (s,S):
When changing from (s,S) to (R,Q):
Input factors are configured in the Input Factors input table with the following columns:
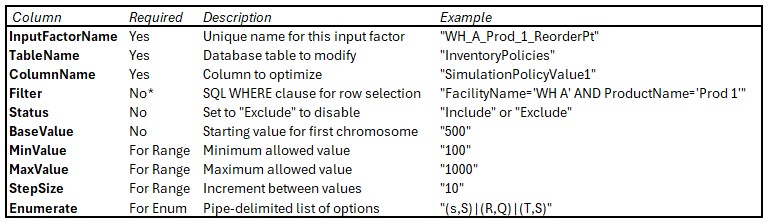
*Filter is required for inventory policy input factors to identify the specific facility-product combination.
The following 2 screenshots show the Input Factors table in Cosmic Frog. It contains 3 records which are set up the same as the example in the "Inventory Policy Sets (Advanced)" section above:
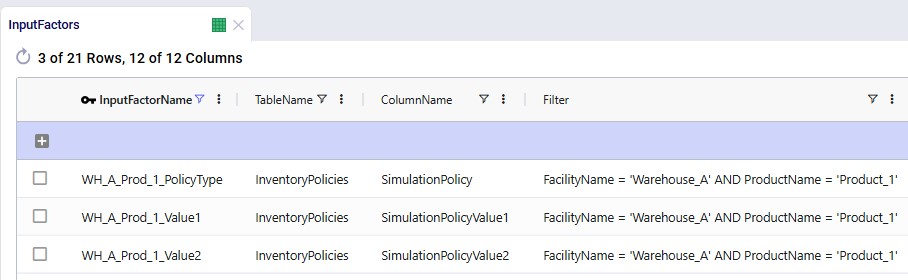
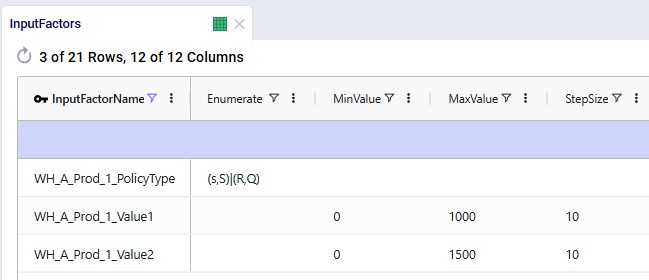
Optimize the reorder point for a single facility-product:
InputFactorName: Seattle_Widget_ReorderPoint TableName: InventoryPolicies ColumnName: SimulationPolicyValue1 Filter: FacilityName='Seattle DC' AND ProductName='Widget A' MinValue: 200 MaxValue: 800 StepSize: 20 BaseValue: 500 Status: Include Result: Dendro will explore reorder points from 200 to 800 in steps of 20 (200, 220, 240, ..., 800).
Optimize order quantity with small increments:
InputFactorName: Boston_Gadget_OrderQty TableName: InventoryPolicies ColumnName: SimulationPolicyValue2 Filter: FacilityName='Boston WH' AND ProductName='Gadget B' MinValue: 50 MaxValue: 500 StepSize: 5 BaseValue: 200 Status: Include Result: Dendro will explore 91 different values (50, 55, 60, ..., 500).
Let Dendro choose between different inventory policies:
InputFactorName: Chicago_Part_PolicyType TableName: InventoryPolicies ColumnName: SimulationPolicy Filter: FacilityName='Chicago Plant' AND ProductName='Part C' Enumerate: (s,S)|(R,Q)|(T,S) BaseValue: (s,S) Status: Include Result: Dendro will test (s,S), (R,Q), and (T,S) policies to see which performs best.
Optimize both policy type and parameters:
Policy Type InputFactorName: LA_Motor_PolicyType TableName: InventoryPolicies ColumnName: SimulationPolicy Filter: FacilityName='LA Warehouse' AND ProductName='Motor D' Enumerate: (s,S)|(R,Q) BaseValue: (s,S) Parameter 1 (reorder point or 's') InputFactorName: LA_Motor_Value1 TableName: InventoryPolicies ColumnName: SimulationPolicyValue1 Filter: FacilityName='LA Warehouse' AND ProductName='Motor D' MinValue: 0 MaxValue: 500 StepSize: 10 BaseValue: 100 Parameter 2 (order-up-to or order quantity) InputFactorName: LA_Motor_Value2 TableName: InventoryPolicies ColumnName: SimulationPolicyValue2 Filter: FacilityName='LA Warehouse' AND ProductName='Motor D' MinValue: 0 MaxValue: 800 StepSize: 10 BaseValue: 300 Result: Dendro will:
The most common input factors for inventory optimization target these columns in the Inventory Policies input table:

Example:
Input Factors:
[0] WH_A_Prod_1_ReorderPoint (Range: 100-1000, Step: 10, Base: 500) [1] WH_A_Prod_1_ReorderPoint (Range: 200-800, Step: 20, Base: 400) [2] WH_A_Prod_1_PolicyType (Enum: (s,S)|(R,Q), Base: (s,S))Results in:
Chromosome 1 (baseline): [500, 400, 0] (0 = first enum value = (s,S)) Chromosome 2 (random): [730, 560, 1] (1 = second enum value = (R,Q)) Chromosome 3 (random): [220, 640, 0] (0 = first enum value = (s,S))When Dendro mutates a chromosome, it changes one or more input factor values:
For Range factors:
For Enumeration factors:
Example mutation:
Original: [500, 400, 0] Mutated: [500, 420, 0] (Position 1 changed: 400 to 420) When Dendro creates a scenario to simulate using the Throg engine:
Result: Each chromosome becomes a complete, runnable supply chain scenario with its specific inventory policy settings.
When turned on, the Automatically Generate Input Factors option (a model run option in the Dendro section of the Technology Parameters) automatically creates input factor configurations based on your inventory policies and service targets.
When to use:
How it works:
The automatic builder uses intelligent rules to set min/max ranges based on current values and service performance:
MinValue: 0 MaxValue: value + 5 (or adjusted based on service) StepSize: 1 Rationale: Small values need fine-grained control and room to explore modest increases.
MinValue: max(1, rounded_value - 15) MaxValue: rounded_value + 15 StepSize: 5 Values are rounded to base 5
Rationale: Medium values can use larger steps (5) while still providing good resolution.
MinValue: max(1, rounded_value - 50) MaxValue: rounded_value + 50 StepSize: 10 Values are rounded to base 10
Rationale: Larger inventories need wider exploration ranges with proportionally larger steps.
MinValue: max(1, rounded_value - 200) MaxValue: rounded_value + 200 StepSize: 20 Values are rounded to base 20
Rationale: Very large inventories benefit from broad exploration with coarse granularity.
The builder adjusts ranges based on current service performance:
When fill rate < target service level: The ratio = target_service / current_fill_rate is used to expand the maximum:
MaxValue = max(value + buffer, ratio * value)
Example:
When fill rate => target service level: The builder is more conservative, allowing exploration below current value:
MaxValue = min(value + buffer, quantity_bounds)
Rationale: If service is already good, there may be opportunity to reduce inventory without harming service.
When fill rate <= 85% (poor service): MinValue is set to current value - does not explore lower values that would worsen service further.
For each inventory policy, the automatic generator typically creates:
Result: A complete Input Factors table ready for Dendro optimization.
Too narrow:
MinValue: 490 MaxValue: 510 StepSize: 1 Problem: Dendro cannot explore significantly different solutions. Only 21 values to test.
Too wide:
MinValue: 0 MaxValue: 100000 StepSize: 1 Problem: 100,000 possible values means Dendro will likely miss the optimal value in the haystack.
Just right:
MinValue: 200 MaxValue: 800 StepSize: 20 Why: Reasonable range around current value (500), coarse enough for efficient exploration (31 values), fine enough for precision.
Rule of thumb: Step size should be 1-5% of the expected optimal value.
For value of approximately 100:
For value of approximately 1000:
Why it matters:
Bad:
MinValue: 100 MaxValue: 1000 StepSize: 40 Problem: (1000-100) / 40 = 22 remainder 20; the max might not be reachable exactly.
Good:
MinValue: 100 MaxValue: 1000 StepSize: 30Check: (1000-100) / 30 = 30 remainder 0; the max can be reached exactly.
Dendro automatically adjusts MaxValue if needed to ensure even division.
Best practice: Set BaseValue to your current policy value.
Why:
When BaseValue is null:
For inventory policies, always configure factors for the same facility-product together:
Good - Coordinated filters:
All three factors have identical FilterWH_A_Prod_1_PolicyType Filter: FacilityName='WH A' AND ProductName='Prod 1' WH_A_Prod_1_Value1 Filter: FacilityName='WH A' AND ProductName='Prod 1' WH_A_Prod_1_Value2 Filter: FacilityName='WH A' AND ProductName='Prod 1' Bad - Mismatched filters:
WH_A_Prod_1_PolicyType Filter: FacilityName='WH A' AND ProductName='Prod 1' WH_A_Prod_1_Value1 Filter: FacilityName='WH A' AND ProductName='Prod 1' WH_A_AllProds_Value2 Filter: FacilityName='WH A' # WRONG - does not match! Why: Dendro groups factors by filter. Mismatched filters create separate uncoordinated genes.
Guideline: More input factors = larger search space = longer optimization
Example calculation:
Search space size: 50^200 = enormous!
Best practice:
Use the Status column: Set Status = 'Exclude' for factors you want to temporarily disable without deleting.
Common mistakes:
Wrong - Missing quotes:
Filter: FacilityName=Warehouse A AND ProductName=Widget
Correct - Proper quotes:
Filter: FacilityName='Warehouse A' AND ProductName='Widget'
Wrong - Incorrect column names:
Filter: Facility='WH A' AND Product='Widget'
Correct - Match actual table column names:
Filter: FacilityName='WH A' AND ProductName='Widget'
Testing tip: Run your filter as a SQL WHERE clause to verify it returns exactly one row (you can use the SQL Editor application on the Optilogic platform for this):
SELECT * FROM InventoryPolicies
WHERE FacilityName='WH A' AND ProductName='Widget';Goal: Keep current policy types and order quantities; optimize reorder points only.
Configuration:
For each facility-product:
InputFactorName: {Facility}_{Product}_ReorderPt TableName: InventoryPolicies ColumnName: SimulationPolicyValue1 Filter: FacilityName='{Facility}' AND ProductName='{Product}' MinValue: [calculated] MaxValue: [calculated] StepSize: [appropriate for value scale] BaseValue: [current value] Result: Dendro explores different reorder points while keeping other policy parameters fixed.
Goal: Let Dendro choose policy types and all parameters.
Configuration:
For each facility-product:
Policy typeInputFactorName: {Facility}_{Product}_Policy TableName: InventoryPolicies ColumnName: SimulationPolicy Filter: FacilityName='{Facility}' AND ProductName='{Product}' Enumerate: (s,S)|(R,Q)Parameter 1 InputFactorName: {Facility}_{Product}_Value1 TableName: InventoryPolicies ColumnName: SimulationPolicyValue1 Filter: FacilityName='{Facility}' AND ProductName='{Product}' [Range configuration] Parameter 2 InputFactorName: {Facility}_{Product}_Value2 TableName: InventoryPolicies ColumnName: SimulationPolicyValue2 Filter: FacilityName='{Facility}' AND ProductName='{Product}' [Range configuration] Result: Maximum flexibility - Dendro explores different policy types and parameter values.
Goal: Optimize top 20% of items by revenue; leave others unchanged.
Approach:
SQL example for selective generation - Create Input Factors for top revenue items only:
INSERT INTO InputFactors (...)
SELECT ... FROM InventoryPolicies ip
JOIN ProductRevenue pr ON ip.ProductName = pr.ProductName
WHERE pr.AnnualRevenue > [threshold]
Result: Focused optimization on items that matter most, faster runtime.
Goal: Use wider ranges for variable-demand products, tighter for stable products.
Configuration:
Stable, predictable products:
MinValue: current_value * 0.8 MaxValue: current_value * 1.2 StepSize: small (fine control) Variable, unpredictable products:
MinValue: current_value * 0.5 MaxValue: current_value * 2.0 StepSize: larger (broader exploration) Result: Appropriate exploration ranges based on demand variability.
Symptom: During loading, you see "no matching inventory policy" in the Job Log.
Cause: The Filter does not match any row in the InventoryPolicies table.
Solutions:
SELECT * FROM InventoryPolicies WHERE [your filter]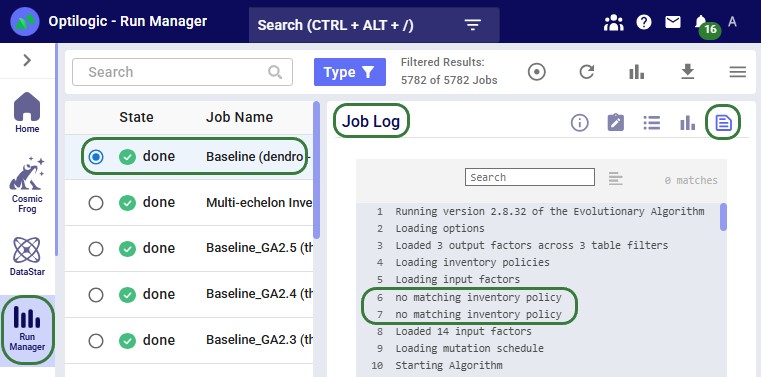
Symptom: Multiple separate genes instead of one coordinated policy set.
Cause: Filters do not match exactly across related factors.
Example problem:
Factor 1 Filter: FacilityName='WH A' AND ProductName='Widget' Factor 2 Filter: FacilityName='WH A' and ProductName='Widget' # lowercase 'and'! Solution: Ensure identical filter text across all factors for the same facility-product.
Symptom: Dendro tests impractical inventory levels (too high or too low).
Cause: Min/Max ranges too wide or poorly set.
Solutions:
Symptom: Fitness scores are not getting better across generations.
Possible causes:
Cause 1: Ranges too narrow
Cause 2: Step size too coarse
Cause 3: Wrong factors optimized
Cause 4: Conflicting objectives
Overall Fitness Scores can be assessed in the Simulation Evolutionary Algorithm Summary output table after a Dendro run has completed, while scores of individual output factors can be reviewed in the Simulation Evolutionary Algorithm Output Factor Report output table:
Symptom: Warnings or errors about order-up-to levels below reorder points.
Cause: Ranges configured without considering logical constraints.
Solution: Dendro handles this automatically through special mutation logic, but you can help by:
Note: Dendro automatically enforces S => s during gene creation and mutation.
Input factors are the foundation of Dendro optimization:
Key takeaways:
Well-configured input factors give Dendro the right level of control to find optimal solutions efficiently. Too much freedom creates an intractably large search space; too little prevents discovering improvements. The art is finding the right balance for your specific supply chain.
You may find these links helpful, some of which have already been mentioned above:
Please do not hesitate to contact the Optilogic Support team on support@optilogic.com for any questions or feedback.
Output factors define what Dendro tries to optimize - they are your business objectives translated into measurable metrics. While input factors control what can change, output factors determine what "better" means.
Key concepts:
This guide explains how to configure output factors to align Dendro's optimization with your business goals. These can be specified in the Output Factors input table in Cosmic Frog models.
Recommended reading prior to diving into this guide: Getting Started with Dendro, a high-level overview of how Dendro works, and Dendro: Genetic Algorithm Guide which explains the inner workings of Dendro in more detail.
An output factor tells Dendro's genetic algorithm:
Imagine you are evaluating employee performance:
Dendro uses the same approach to evaluate inventory policy combinations across your supply chain.
Output factors are configured in the Output Factors input table with the following columns:
Minimize overall supply chain costs:
OutputFactorName: TotalCost TableName: SimulationNetworkSummaryReplicationDetail ColumnName: TotalSupplyChainCost Filter: (leave empty for all data)UtilityCurve: [1500000,100],[2000000,0]OutputFactorWeight: 0.40 Status: Include Interpretation:
Maximize service level performance:
OutputFactorName: ServiceLevel TableName: SimulationNetworkServiceSummaryReplicationDetailColumnName: TotalPlacedCustomerOrderQuantityOnTimeInFullRate Filter: (leave empty) UtilityCurve: [0,0],[85,10],[95,99],[100,100]OutputFactorWeight: 0.35 Status: Include Interpretation:
Focus on inventory costs at distribution centers only:
OutputFactorName: DC_HoldingCost TableName: SimulationFacilityCostSummaryReplicationDetail ColumnName: InventoryHoldingCost Filter: FacilityType='DC' UtilityCurve: [50000,100],[150000,0]OutputFactorWeight: 0.25 Status: Include Interpretation:
The following 2 screenshots show the Output Factors input table in Cosmic Frog; it contains 3 rows which represent the 3 examples above:
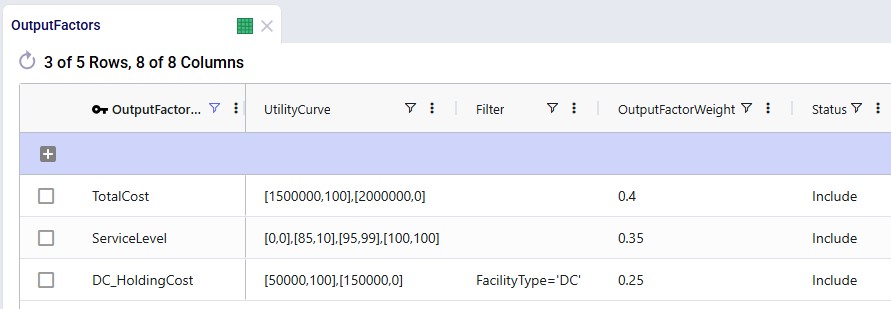
A utility curve translates raw metric values (like dollars or percentages) into standardized quality scores (0-100 points). It answers the question: "How good is this value?".
Format:[value1,score1],[value2,score2],[value3,score3],...
Each [value,score] pair defines a point on the curve:
Dendro connects these points with straight lines to create a piecewise linear curve.
[1000,100],[2000,0]
Meaning:
Visualization:
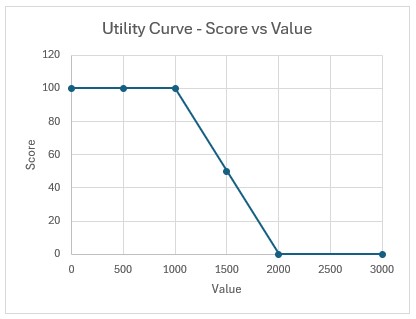
Best for:
[50,0],[100,50],[150,100]
Meaning:
Visualization:
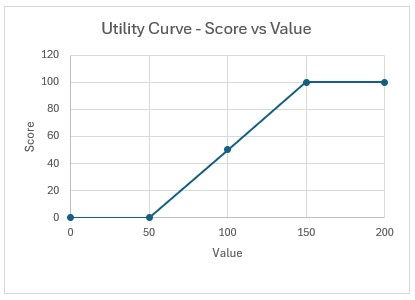
Best for:
[0,0],[85,10],[95,99],[100,100]
Meaning:
Characteristics:
Visualization:
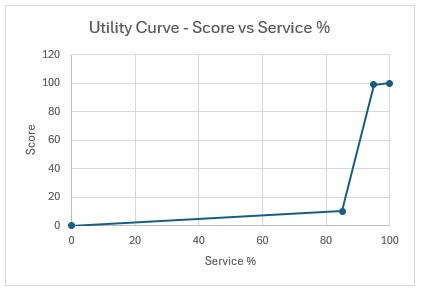
Best for:
The challenge: Early in optimization, Dendro does not know what the best and worst possible values are.
The solution: Utility curves automatically expand when new extremes are discovered.
Example scenario:
Generation 1:
[1800000,100],[2200000,0]Generation 5:
[1600000,100],[2200000,0]Why it matters:
When rescaling occurs:
Weights determine how much each output factor contributes to the overall fitness score.
Common approaches:
Total Cost: Weight = 0.40 (40%) Service Level: Weight = 0.35 (35%) Inventory Value: Weight = 0.25 (25%) Total = 1.00 (100%) Advantage: Easy to understand - directly represents percentage contribution.
Total Cost: Weight = 40 Service Level: Weight = 35 Inventory Value: Weight = 25 Total = 100 (but could be any sum) Advantage: Can use any convenient scale; Dendro handles normalization.
Critical Factor: Weight = 10 Important Factor: Weight = 5 Secondary Factor: Weight = 2 Minor Factor: Weight = 1 Advantage: Emphasizes relative priorities clearly.
Example calculation:
Output Factors:
Holding Cost: Raw value = $80,000 → Utility score = 60 → Weight = 0.40 Service Level: Raw value = 94% → Utility score = 85 → Weight = 0.35 Transport Cost: Raw value = $45,000 → Utility score = 70 → Weight = 0.25 Weighted Contributions:
Holding Cost: 60 × 0.40 = 24.0 pointsService Level: 85 × 0.35 = 29.75 points Transport Cost: 70 × 0.25 = 17.5 points Overall Fitness Score: 24.0 + 29.75 + 17.5 = 71.25 points
Higher fitness scores are better in Dendro
The fitness calculation adds these weighted scores, so the formula is:
Fitness = 24.0 + 29.75 + 17.5 = 71.25
Balanced approach:
Cost factors (total): 50% Service factors (total): 50% Equal priority to cost reduction and service achievement.
Cost-focused approach:
Cost factors (total): 70% Service factors (total): 30% Emphasizes cost minimization; willing to accept moderate service levels.
Service-focused approach:
Cost factors (total): 30% Service factors (total): 70% Prioritizes customer service; cost is secondary.
Multi-objective balanced:
Holding cost: 25% Transport cost: 25% Service level: 25% Inventory turns: 25% Equal consideration to multiple objectives.
For each output factor, Dendro reads the metric value from the simulation results:
Factor 1 (Total Cost): Reads TotalSupplyChainCost → $1,750,000 Factor 2 (Service Level): Reads OnTimeInFullRate → 92% Factor 3 (Holding Cost): Reads InventoryHoldingCost → $320,000 Each value is mapped to a raw score using its utility curve:
Factor 1: $1,750,000 → Utility curve [1500000,100],[2000000,0]Interpolation: (1,750,000 - 1,500,000) / (2,000,000 - 1,500,000) = 0.5 Raw score: 100 - (0.5 × 100) = 50 Factor 2: 92% → Utility curve [0,0],[85,10],[95,99],[100,100]Falls between 85 and 95: Interpolate Raw score: 10 + ((92-85)/(95-85)) × (99-10) = 10 + 62.3 = 72.3Factor 3: $320,000 → Utility curve [200000,100],[400000,0]Interpolation: (320,000 - 200,000) / (400,000 - 200,000) = 0.6Raw score: 100 - (0.6 × 100) = 40 Utility scores are scaled to a 0-100 range based on the min/max scores in the curve:
If all curves use 0-100 range → No additional scaling neededScores are already normalized: 50, 72.3, 40 Multiply each normalized score by its weight:
Factor 1: 50 × 0.40 = 20.0 Factor 2: 72.3 × 0.35 = 25.3 Factor 3: 40 × 0.25 = 10.0 Combine all weighted scores:
Overall score = 20.0 + 25.3 + 10.0 = 55.3
Chromosome A:
Total Cost: $1,600,000 → Score 80 → Weighted 32.0 Service: 96% → Score 100 → Weighted 35.0 Holding: $280,000 → Score 60 → Weighted 15.0 Total: 82.0 Chromosome B:
Total Cost: $1,750,000 → Score 50 → Weighted 20.0 Service: 92% → Score 72 → Weighted 25.2 Holding: $320,000 → Score 40 → Weighted 10.0 Total: 55.2 Result: Chromosome A (fitness score of 82.0) is better than Chromosome B (fitness score of 55.2).
Chromosome A achieves better performance across all metrics, resulting in a higher fitness score.
In Cosmic Frog, the Overall Fitness Scores of all scenarios (=chromosomes) run can be assessed in the Simulation Evolutionary Algorithm Summary output table after a Dendro run has completed. Scores of individual output factors can be reviewed in the Simulation Evolutionary Algorithm Output Factor Report output table:
The Automatically Generate Output Factors option automatically creates standard output factor configurations based on your target service levels and baseline simulation results. This option can be set in the Dendro section of the Technology Parameters.
When to use:
What it creates:
Step 1: Run baseline simulation Execute your current inventory policies to measure actual cost.
Step 2: Establish boundaries
Baseline Cost: $1,800,000 Left Boundary (best): 75% of baseline = $1,350,000 Right Boundary (worst): 110% of baseline = $1,980,000 Step 3: Create utility curve
UtilityCurve: [1350000,100],[1980000,0]
Interpretation:
Step 4: Set weight
OutputFactorWeight: 1 (50% when combined with service factor)
Step 1: Use configured service targets
DefaultTargetService: 95% LowService: 85% Step 2: Create multi-point utility curve
UtilityCurve: [0,0],[85,10],[95,99],[100,100]
Interpretation:
Design rationale:
Step 3: Set weight
OutputFactorWeight: 1 (50% when combined with cost factor)
OutputFactors Table:
Row 1: OutputFactorName: Cost TableName: SimulationNetworkSummaryReplicationDetailColumnName: TotalSupplyChainCost Filter: NULL UtilityCurve: [1350000,100],[1980000,0]OutputFactorWeight: 1 Status: Include Row 2: OutputFactorName: Service TableName: SimulationNetworkServiceSummaryReplicationDetailColumnName: TotalPlacedCustomerOrderQuantityOnTimeInFullRateFilter: NULL UtilityCurve: [0,0],[85,10],[95,99],[100,100]OutputFactorWeight: 1 Status: Include Optimization behavior: Dendro will seek policies that:
Goal: Find the lowest-cost inventory policies without service constraints.
Setup:
OutputFactorName: TotalCost TableName: SimulationNetworkSummaryReplicationDetailColumnName: TotalSupplyChainCost UtilityCurve: [1000000,100],[3000000,0]OutputFactorWeight: 1.0 Result: Dendro minimizes cost aggressively; service may suffer.
When to use:
Goal: Maximize service while preventing excessive cost increases.
Setup:
Factor 1 - Service (Primary): OutputFactorName: Service TableName: SimulationNetworkSummaryReplicationDetailColumnName: OnTimeInFullRate UtilityCurve: [90,0],[95,50],[98,99],[100,100]OutputFactorWeight: 0.70 Factor 2 - Cost (Constraint):OutputFactorName: CostLimit TableName: SimulationNetworkSummaryReplicationDetailColumnName: TotalSupplyChainCost UtilityCurve: [1500000,100],[2000000,50],[2500000,0]OutputFactorWeight: 0.30 Result: Dendro prioritizes service but penalizes solutions exceeding cost thresholds.
When to use:
Goal: Optimize multiple objectives with balanced priorities.
Setup:
Factor 1 - Holding Cost: OutputFactorName: HoldingCost TableName: SimulationNetworkSummaryReplicationDetailColumnName: InventoryHoldingCost UtilityCurve: [200000,100],[500000,0]OutputFactorWeight: 0.25 Factor 2 - Transport Cost: OutputFactorName: TransportCostTableName: SimulationNetworkSummaryReplicationDetailColumnName: TransportationCost UtilityCurve: [300000,100],[600000,0]OutputFactorWeight: 0.25 Factor 3 - Service Level: OutputFactorName: Service TableName: SimulationNetworkSummaryReplicationDetailColumnName: FillRate UtilityCurve: [85,0],[95,99],[100,100]OutputFactorWeight: 0.30 Factor 4 - Inventory Turns: OutputFactorName: InventoryTurnsTableName: SimulationNetworkSummaryReplicationDetailColumnName: InventoryTurns UtilityCurve: [2,0],[6,50],[12,100]OutputFactorWeight: 0.20 Result: Dendro finds well-rounded solutions balancing cost, service, and efficiency.
When to use:
Goal: Different service targets for different regions.
Setup:
Factor 1 - Premium Region Service: OutputFactorName: Premium_Service TableName: SimulationNetworkSummaryReplicationDetailColumnName: FillRate Filter: Region='Premium' UtilityCurve: [92,0],[98,99],[100,100]OutputFactorWeight: 0.40 Factor 2 - Standard Region Service: OutputFactorName: Standard_Service TableName: SimulationNetworkSummaryReplicationDetailColumnName: FillRate Filter: Region='Standard' UtilityCurve: [85,0],[92,99],[100,100]OutputFactorWeight: 0.30 Factor 3 - Overall Cost: OutputFactorName: TotalCost TableName: SimulationNetworkSummaryReplicationDetailColumnName: TotalSupplyChainCost UtilityCurve: [2000000,100],[3000000,0]OutputFactorWeight: 0.30 Result: Premium regions get higher service targets; standard regions have lower thresholds.
When to use:
Some output tables contain multiple rows per scenario (e.g., one row per facility or product). Dendro combines these into a single metric value by using a straight average calculation. More options will be added in future releases.
How it works: Calculates the arithmetic mean of all matching rows.
SQL equivalent:
SELECT AVG(ColumnName)
FROM TableName
WHERE ScenarioName = 'Gen3_Chr5' AND [Filter]Example:
Facility A holding cost: $80,000 Facility B holding cost: $120,000 Facility C holding cost: $100,000 SimpleAverage: ($80,000 + $120,000 + $100,000) / 3 = $100,000 Best for:
Do not use:
[0,0],[10,5],[20,15],[30,28],[40,45],[50,65],[60,82],[70,95],[80,98],[90,99],[100,100]
Over-complicated curves are hard to understand and maintain.
Do use:
[0,0],[85,10],[95,99],[100,100]
Simple curves with clear inflection points at meaningful thresholds.
Principle: Use the minimum number of points to capture your business logic.
Cost factors (minimize):
[best_cost, 100], [worst_acceptable_cost, 0]
Lower values → higher scores.
Service factors (maximize):
[minimum_acceptable, 0], [target, 99], [perfect, 100]
Higher values → higher scores.
Efficiency metrics (target range):
[too_low, 0], [optimal, 100], [too_high, 0]
Sweet spot in the middle.
Too narrow:
[1900000,100],[2000000,0]
Only a 5% range - most solutions will score 0 or 100, providing little differentiation.
Too wide:
[500000,100],[5000000,0]
Unrealistic extremes - actual values may all cluster in a small region, reducing curve sensitivity.
Just right:
[1500000,100],[2500000,0]
Reasonable range around baseline (±25%) allows meaningful differentiation.
Avoid extreme imbalances:
Cost: Weight = 0.95 Service: Weight = 0.05 Service becomes nearly irrelevant - Dendro will slash costs with little regard for service.
Prefer balanced or clearly justified ratios:
Cost: Weight = 0.60 Service: Weight = 0.40 Both factors matter; cost slightly more important.
Or equal weighting for exploration:
Cost: Weight = 0.50 Service: Weight = 0.50 Neutral stance - let Dendro find the natural trade-off.
Workflow:
Benefits:
Before running full optimization:
SELECT * FROM SimulationFacilityCostSummaryReplicationDetail
WHERE ScenarioName = 'Baseline' AND FacilityType = 'DC'[100,0],[200,100] ✓ Valid [100,0] [200,100] ✗ Invalid (missing comma between pairs)Simulate scoring: Manually calculate expected fitness for baseline After the Dendro runs have all completed, review the Overall Fitness Score values in the Simulation Evolutionary Algorithm Summary output table and the scores of the individiual otuput factors Simulation Evolutionary Algorithm Output Factor Report output tables.
Healthy optimization shows:
Warning signs:
The symptoms of the problems desribed in this section can generally be seen either in the Cosmic Frog output tables, typically the Simulation Evolutionary Algorithm Summary and/or the Simulation Evolutionary Algorithm Output Factor Report output tables, or in the logs of the base scenario that Dendro was run on. These logs can be reviewed using the Run Manager application. The following screenshot shows part of a Job Log of a Dendro run, which is the most detailed log available:
Besides the Job Log, the Job Records log (second icon in the row of icons at the top rightof the logs) can also be helpful; it contains status messages of a run at a more aggregated level. If a run ends in an error, the Job Error Log may provide useful troubleshooting information. This log is accessed by clicking on the last icon in the row of icons at the top right of the logs.
Symptom: Fitness scores are nearly identical across different policy combinations.
Possible causes:
Cause 1: Utility curves too flat
UtilityCurve: [0,100],[10000000,0]
Range is so wide that actual values ($1.5M-$2.5M) all map to ~80-90 points.
Solution: Narrow the utility curve to the realistic range of values.
Cause 2: Weights too imbalanced
Dominant factor: Weight = 0.99 Other factors: Weight = 0.01 (total) One factor overwhelms all others, hiding differentiation.
Solution: Balance weights more evenly (unless extreme prioritization is truly intended).
Cause 3: Input factors do not affect output metrics - optimizing parameters that do not impact measured outcomes.
Solution: Verify that input factor changes influence output metrics via simulation.
Symptom: Cost decreases but service stays low or drops.
Possible causes:
Cause 1: Service weight too low
Cost: Weight = 0.90 Service: Weight = 0.10 Dendro focuses almost entirely on cost reduction.
Solution: Increase service weight to at least 0.30-0.50.
Cause 2: Service utility curve rewards poor performance
UtilityCurve: [80,50],[100,100]
80% service still gets 50 points - not enough penalty.
Solution: Use a steeper curve with lower minimum:
UtilityCurve: [80,0],[95,99],[100,100]
Cause 3: Conflicting objectives Impossible to improve service without exceeding cost limits defined in utility curves.
Solution: Relax cost constraints or adjust service targets to achievable levels.
Symptom: Frequent rescaling events throughout optimization.
Possible cause: Utility curve bounds are too narrow; Dendro keeps finding values outside the range.
Solution:
Symptom: Error loading output factors or calculating fitness.
Possible causes:
Cause 1: Wrong table name
TableName: NetworkSummary
Actual table is SimulationNetworkSummaryReplicationDetail.
Solution: Use exact table name from database schema.
Cause 2: Wrong column name
ColumnName: TotalCost
Actual column is TotalSupplyChainCost.
Solution: Verify column names match simulation output schema exactly.
Cause 3: Filter returns no rows
Filter: Region='West Coast'
No rows in output table have Region='West Coast'.
Solution: Test filter with SQL query against actual simulation output.
Symptom: "UtilityCurve is None" or parsing failures.
Common syntax errors:
❌ Missing commas between pairs:
[100,0][200,100]
✓ Correct:
[100,0],[200,100]
❌ Spaces inside brackets:
[ 100 , 0 ],[ 200 , 100 ]
✓ Correct (spaces are removed automatically but avoid for clarity):
[100,0],[200,100]
❌ Invalid numbers:
[1,000,0],[2,000,100]
Commas in numbers are invalid.
✓ Correct:
[1000,0],[2000,100]
❌ Single point:
[100,0]
Need at least two points for a curve.
✓ Correct:
[100,0],[200,100]
Optimize performance across different time periods:
Factor 1 - Peak Season Service: Filter: Month IN (11,12) Weight: 0.40 Factor 2 - Off-Season Service: Filter: Month NOT IN (11,12) Weight: 0.20 Factor 3 - Annual Cost: Filter: (empty - all months) Weight: 0.40 Result: Higher service standards during peak season, relaxed otherwise.
Different objectives for different product categories:
Factor 1 - A-Item Service (High priority): Filter: ProductCategory='A' UtilityCurve: [95,0],[98,99],[100,100] Weight: 0.35 Factor 2 - B-Item Service (Medium priority): Filter: ProductCategory='B' UtilityCurve: [90,0],[95,99],[100,100] Weight: 0.25 Factor 3 - C-Item Service (Low priority): Filter: ProductCategory='C' UtilityCurve: [85,0],[90,99],[100,100] Weight: 0.15 Factor 4 - Total Cost (All categories): Filter: (empty) Weight: 0.25 Result: ABC-based service differentiation with balanced cost control.
Output factors define success in Dendro optimization:
✓ What to measure: Metrics from simulation output tables
✓ How good is good: Utility curves mapping values to quality scores
✓ How important: Weights defining relative priorities
Key takeaways:
Well-configured output factors ensure Dendro optimizes for what truly matters to your business - whether that is cost minimization, service maximization, or balanced multi-objective optimization.
You may find these links helpful, some of which have already been mentioned above:
Please do not hesitate to contact the Optilogic Support team on support@optilogic.com for any questions or feedback.

