

In this quick start guide we will show how Leapfrog AI can be used in DataStar to generate tasks from natural language prompts, no coding necessary!
This quick start guide builds upon the previous one where a CSV file was imported into the Project Sandbox, please follow the steps in there first if you want to follow along with the steps in this quick start. The starting point for this quick start is therefore a project named Import Historical Shipments that has a Historical Shipments data connection of type = CSV, and a table in the Project Sandbox named rawshipments, which contains 42,656 records.
The Shipments.csv file that was imported into the rawshipments table has following data structure (showing 5 of the 42,656 records):

Our goal in this quick start is to create a task using Leapfrog that will use this data (from the rawshipments table in the Project Sandbox) to create a list of unique customers, where the destination stores function as the customers. Ultimately, this list of customers will be used to populate the Customers input table of a Cosmic Frog model. A few things to consider when formulating the prompt are:
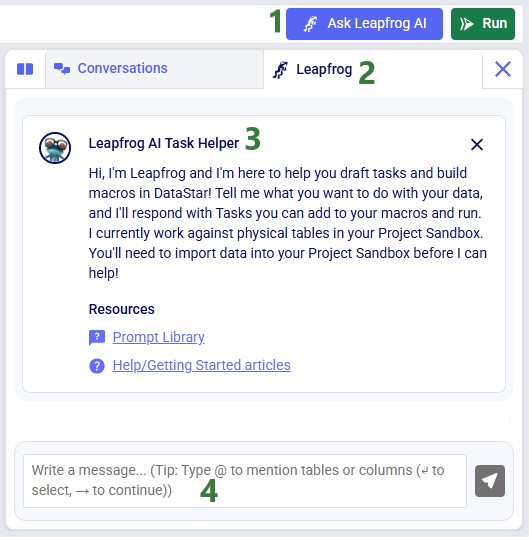
Within the Import Historical Shipments DataStar project, click on the Import Shipments macro to open it in the macro canvas, you should see the Start and Import Raw Shipments tasks on the canvas. Then open Leapfrog by clicking on the Ask Leapfrog AI button to the right in the toolbar at the top of DataStar. This will open the Leapfrog tab where a welcome message will be shown. Next, we can write our prompt in the “Write a message…” textbox.
Keeping in mind the 5 items mentioned above, the prompt we use is the following: “Use the @rawshipments table to create unique customers (use the @rawshipments.destination_store column); average the latitudes and longitudes. Only use records with the @rawshipments.ship_date between July 1 2024 and June 30 2025. Match to the anura schema of the Customers table”. Please note that:
After clicking on the send icon to submit the prompt, Leapfrog will take a few seconds to consider the prompt and formulate a response. The response will look similar to the following screenshot, where we see from top to bottom:
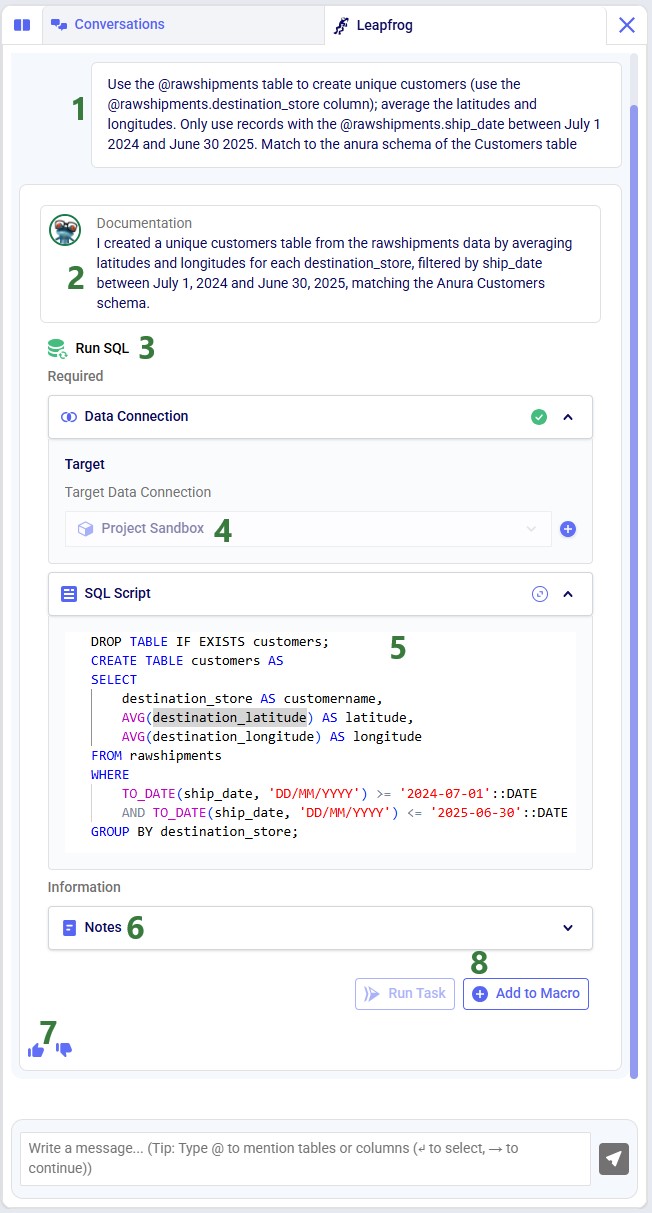
For copy-pasting purposes, the resulting SQL Script is repeated here:
DROP TABLE IF EXISTS customers;
CREATE TABLE customers AS
SELECT
destination_store AS customername,
AVG(destination_latitude) AS latitude,
AVG(destination_longitude) AS longitude
FROM rawshipments
WHERE
TO_DATE(ship_date, 'DD/MM/YYYY') >= '2024-07-01'::DATE
AND TO_DATE(ship_date, 'DD/MM/YYYY') <= '2025-06-30'::DATE
GROUP BY destination_store;
Those who are familiar with SQL, will be able to tell that this will indeed achieve our goal. Since that is the case, we can click on the Add to Macro button at the bottom of Leapfrog’s response to add this as a Run SQL task to our Import Shipments macro. When hovering over this button, you will see Leapfrog suggests where to put it on the macro canvas and to connect it to the Import Raw Shipments task, which is what we want. When next clicking on the Add to Macro button it will be added.
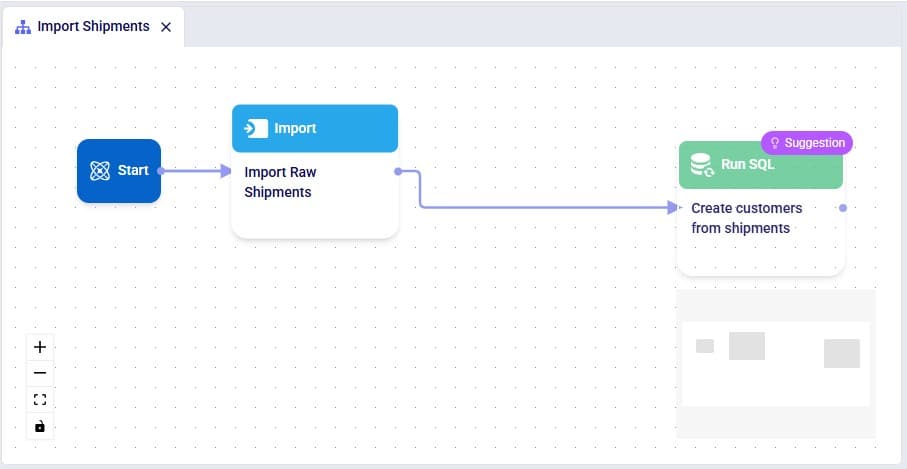
We can test our macro so far, by clicking on the green Run button at the right top of DataStar. Please note that:
Once the macro is done running, we can check the results. Go to the Data Connections tab, expand the Project Sandbox connection and click on the customers table to open it in the central part of DataStar:
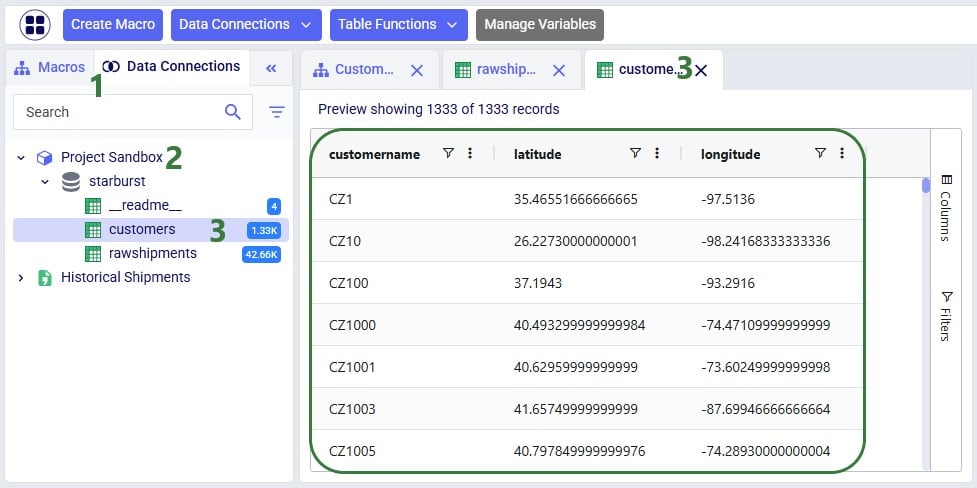
We see that the customers table resulting from running the Leapfrog-created Run SQL task contains 1,333 records. Also notice that its schema matches that of the Customers table of Cosmic Frog models, which includes columns named customername, latitude, and longitude.
Writing prompts for Leapfrog that will create successful responses (e.g. the SQL Script generated will achieve what the prompt-writer intended) may take a bit of practice. This Mastering Leapfrog for SQL Use Cases: How to write Prompts that get Results post on the Frogger Pond community portal has some great advice which applies to Leapfrog in DataStar too. It is highly recommended to give it a read; the main points of advice follow here too:
As an example, let us look at variations of the prompt we used in this quick start guide, to gauge the level of granularity needed for a successful response. In this table, the prompts are listed from least to most granular:
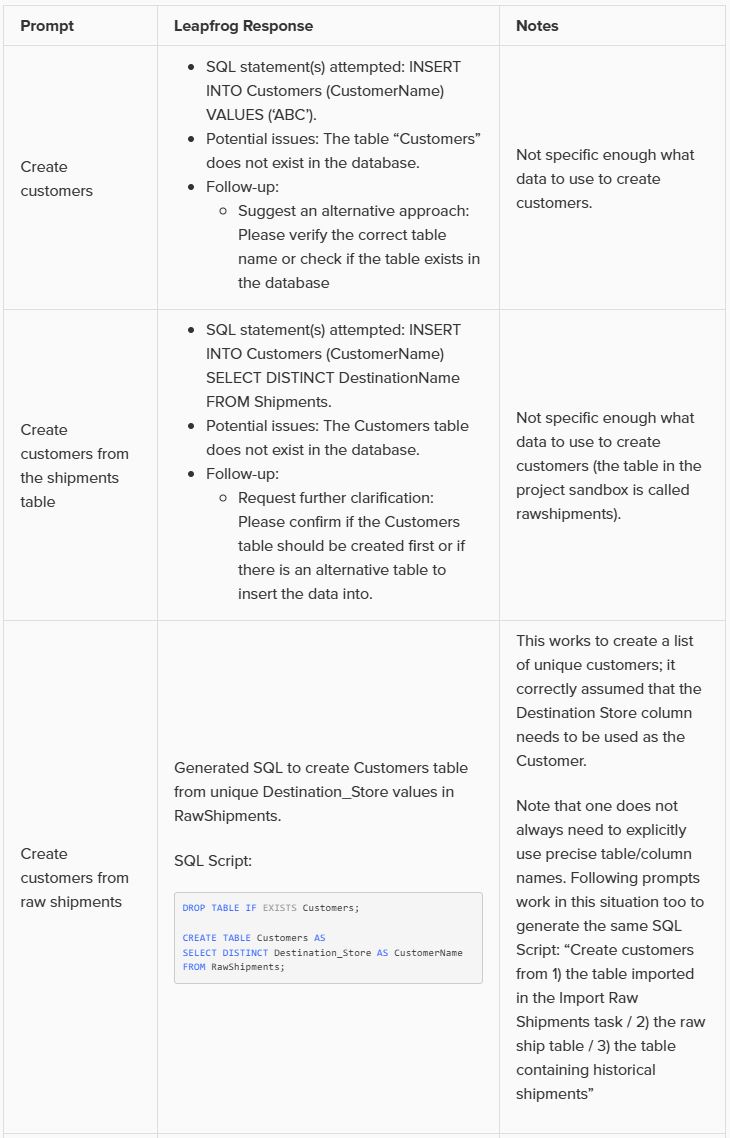
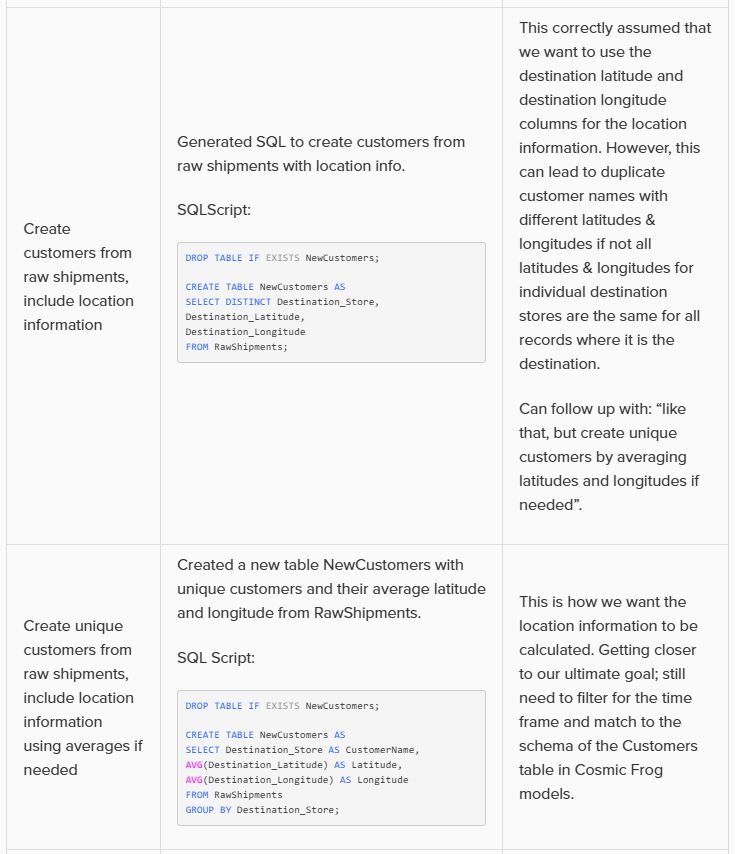

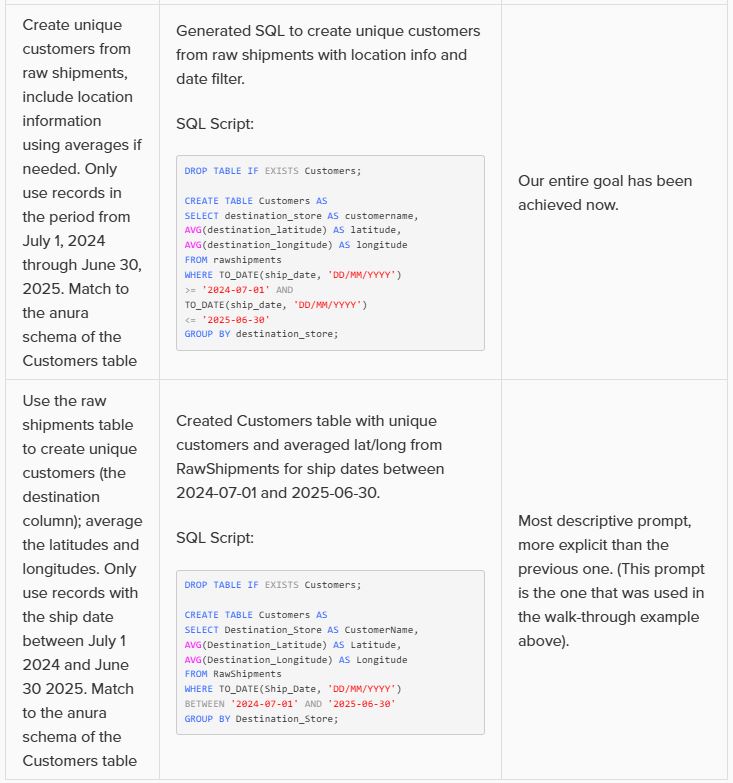
Note that in the above prompts, we are quite precise about table and column names and no typos are made by the prompt writer. However, Leapfrog can generally manage well with typos and often also pick up table and column names when not explicitly used in the prompt. So while generally being more explicit results in higher accuracy, it is not necessary to always be extremely explicit and we just recommend to be as explicit as you can be.
In addition, these example prompts do not use the @ character to specify tables and columns to use, but they could to facilitate prompt writing further.

In this quick start guide we will show how Leapfrog AI can be used in DataStar to generate tasks from natural language prompts, no coding necessary!
This quick start guide builds upon the previous one where a CSV file was imported into the Project Sandbox, please follow the steps in there first if you want to follow along with the steps in this quick start. The starting point for this quick start is therefore a project named Import Historical Shipments that has a Historical Shipments data connection of type = CSV, and a table in the Project Sandbox named rawshipments, which contains 42,656 records.
The Shipments.csv file that was imported into the rawshipments table has following data structure (showing 5 of the 42,656 records):
Our goal in this quick start is to create a task using Leapfrog that will use this data (from the rawshipments table in the Project Sandbox) to create a list of unique customers, where the destination stores function as the customers. Ultimately, this list of customers will be used to populate the Customers input table of a Cosmic Frog model. A few things to consider when formulating the prompt are:
Within the Import Historical Shipments DataStar project, click on the Import Shipments macro to open it in the macro canvas, you should see the Start and Import Raw Shipments tasks on the canvas. Then open Leapfrog by clicking on the Ask Leapfrog AI button to the right in the toolbar at the top of DataStar. This will open the Leapfrog tab where a welcome message will be shown. Next, we can write our prompt in the “Write a message…” textbox.
Keeping in mind the 5 items mentioned above, the prompt we use is the following: “Use the @rawshipments table to create unique customers (use the @rawshipments.destination_store column); average the latitudes and longitudes. Only use records with the @rawshipments.ship_date between July 1 2024 and June 30 2025. Match to the anura schema of the Customers table”. Please note that:
After clicking on the send icon to submit the prompt, Leapfrog will take a few seconds to consider the prompt and formulate a response. The response will look similar to the following screenshot, where we see from top to bottom:
For copy-pasting purposes, the resulting SQL Script is repeated here:
DROP TABLE IF EXISTS customers;
CREATE TABLE customers AS
SELECT
destination_store AS customername,
AVG(destination_latitude) AS latitude,
AVG(destination_longitude) AS longitude
FROM rawshipments
WHERE
TO_DATE(ship_date, 'DD/MM/YYYY') >= '2024-07-01'::DATE
AND TO_DATE(ship_date, 'DD/MM/YYYY') <= '2025-06-30'::DATE
GROUP BY destination_store;
Those who are familiar with SQL, will be able to tell that this will indeed achieve our goal. Since that is the case, we can click on the Add to Macro button at the bottom of Leapfrog’s response to add this as a Run SQL task to our Import Shipments macro. When hovering over this button, you will see Leapfrog suggests where to put it on the macro canvas and to connect it to the Import Raw Shipments task, which is what we want. When next clicking on the Add to Macro button it will be added.
We can test our macro so far, by clicking on the green Run button at the right top of DataStar. Please note that:
Once the macro is done running, we can check the results. Go to the Data Connections tab, expand the Project Sandbox connection and click on the customers table to open it in the central part of DataStar:
We see that the customers table resulting from running the Leapfrog-created Run SQL task contains 1,333 records. Also notice that its schema matches that of the Customers table of Cosmic Frog models, which includes columns named customername, latitude, and longitude.
Writing prompts for Leapfrog that will create successful responses (e.g. the SQL Script generated will achieve what the prompt-writer intended) may take a bit of practice. This Mastering Leapfrog for SQL Use Cases: How to write Prompts that get Results post on the Frogger Pond community portal has some great advice which applies to Leapfrog in DataStar too. It is highly recommended to give it a read; the main points of advice follow here too:
As an example, let us look at variations of the prompt we used in this quick start guide, to gauge the level of granularity needed for a successful response. In this table, the prompts are listed from least to most granular:
Note that in the above prompts, we are quite precise about table and column names and no typos are made by the prompt writer. However, Leapfrog can generally manage well with typos and often also pick up table and column names when not explicitly used in the prompt. So while generally being more explicit results in higher accuracy, it is not necessary to always be extremely explicit and we just recommend to be as explicit as you can be.
In addition, these example prompts do not use the @ character to specify tables and columns to use, but they could to facilitate prompt writing further.







